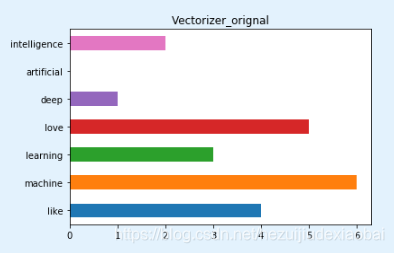
文档的向量化
0 CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'I like machine Learning.',
'I love Deep Learning',
'And i deep love Artificial Intelligence'
]
1 未经停用词过滤的文档向量化
vectorizer = CountVectorizer()
vectorizer.fit_transform(corpus).todense() # 转化为完整特征矩阵

vectorizer.vocabulary_

import pandas as pd
pd.Series(vectorizer.vocabulary_).plot.barh(title='Vectorizer_orignal')
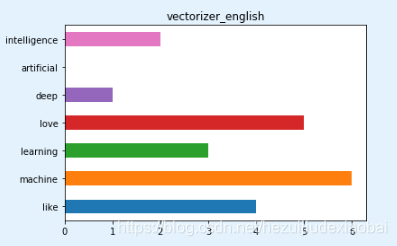
2 经过停用词过滤后的文档向量化
import nltk
nltk.download('stopwords')
停用词
stopwords = nltk.corpus.stopwords.words('english')
stopwords

vectorizer_english = CountVectorizer(stop_words='english')
vectorizer_english.fit_transform(corpus).todense()

vectorizer_english.vocabulary_

pd.Series(vectorizer_english.vocabulary_).plot.barh(title='vectorizer_english')
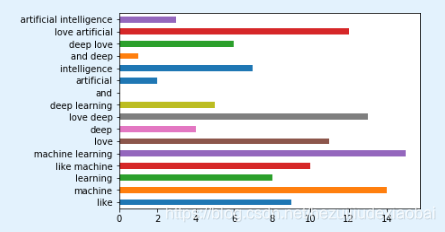
3 采用ngram模式进行文档向量化
ngram_range
vectorizer_ngrame = CountVectorizer(ngram_range=(1, 2))
vectorizer_ngrame.fit_transform(corpus).todense()

vectorizer_ngrame.vocabulary_

pd.Series(vectorizer_ngrame.vocabulary_).plot.barh('vectorizer_ngrame')