文章目录
一、BN批量标准化(手撕!!)
1.1 独立同分布
(1)去除特征之间的相关性 —> 独立;
(2)使得所有特征具有相同的均值和方差 —> 同分布。
在训练时我们希望输入的数据能够是独立同分布的话最好,独立同分布的数据之间具有独立性,每个特征不会相互影响,都是最后结果的一个条件,这一点是好的;
第二点,对于每一个特征应该具有同分布,这样训练起来使得网络训练更快!收敛更快。
1.2 ICS影响
深度神经网络模型的训练为什么会很困难?其中一个重要的原因是,深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致上层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断去重新适应底层的参数更新。为了训好模型,我们需要非常谨慎地去设定学习率、初始化权重、以及尽可能细致的参数更新策略。
简而言之,每个神经元的输入数据不再是“独立同分布”。
其一,上层参数需要不断适应新的输入数据分布,降低学习速度。
其二,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止。
其三,每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎。
1.3 BN来了
BN的算法如下所示,某一层网络的输出会得到特征x,然后计算这一个batchsize下的均值,m代表batchsize,xi是每个数据的该特征。然后求均值,然后就标准化,到这大家都理解。后面它又来了可尺度变换和缩放,相当于又变道一个服从N(gama,beta)的分布了!这里的gama和beta都是参数,是需要训练的,相当于我们为每一层网络的输出每一个特征训练了一个分布。哈哈

1.4手撕代码
主要是反向传播推到!
反向传播求梯度:
因为:
所以:
因为:
所以:
因为:
和
所以:
所以:
def batchnorm_backward(dout, cache):
"""
Inputs:
- dout: 上一层的梯度,维度(N, D),即 dL/dy
- cache: 所需的中间变量,来自于前向传播
Returns a tuple of:
- dx: (N, D)维的 dL/dx
- dgamma: (D,)维的dL/dgamma
- dbeta: (D,)维的dL/dbeta
"""
x, gamma, beta, x_hat, sample_mean, sample_var, eps = cache
N = x.shape[0]
dgamma = np.sum(dout * x_hat, axis = 0)
dbeta = np.sum(dout, axis = 0)
dx_hat = dout * gamma
dsigma = -0.5 * np.sum(dx_hat * (x - sample_mean), axis=0) * np.power(sample_var + eps, -1.5)
dmu = -np.sum(dx_hat / np.sqrt(sample_var + eps), axis=0) - 2 * dsigma*np.sum(x-sample_mean, axis=0)/ N
dx = dx_hat /np.sqrt(sample_var + eps) + 2.0 * dsigma * (x - sample_mean) / N + dmu / N
return dx, dgamma, dbeta
1.5 参数量计算补充
这里主要补充卷积网络中BN知识点!!

二、Linux环境下常用指令(必备!!)
1、查看当前进程
ps -aus
2、vim操作
vim xxx.xx //编辑文件
- 进入为命令行界面,按“i”进入insert输入界面,可以编辑操作,写完后,按ESC退出,回到命令行界面;
- 如果不想保存按住“:q!”强制退出;如果想保存按住“:wq”即可;
- 命令行界面下搜索指令:“/word”;向下搜索;n继续向下搜索;
"?word"向上搜索 n继续向上搜索 N反向搜索; - nG到第n行
- 多窗口操作,打开一个窗口后,:sp yyy.xx打开另一个文件,两个文件一起看,先按住ctr+w+再上下按钮切换窗口;
3、显示信息
ls ccc/ -a //显示所有信息
ls ccc/ -l // 显示列表信息 等同于 ll ccc/
4、软连接
ln -s ccc/sss ./test //把他软连到test
5、创建一个文件
touch 2.zz
6、显示绝对路径
pwd
7、查看内存情况
df -h
8、查看GPU情况
nvidia-smi
9、查看IP地址
ifconfig
10、删除|移动
mv aaa bbb //移动文件
mv -r aaa/ bbb/ //移动文件夹
rm aaa //删除文件
11、
三、关于正则化问题
1.什么是过拟合
过拟合是指我们训练的网络过度拟合以满足在训练集有一个完美的效果,但是过度完美他会使得一些噪声也能拟合好,这样对于测试集不利。下图所示。
其实就是欠拟合代表拟合效果过于简单,过拟合就是拟合效果过于复杂

1.2 解决过拟合的方法
1、减少特征数量:其实也等同于网络简单化,网络太复杂,参数多固然拟合效果足够好,所以针对不同的数据会对应不同复杂度的网络,这样才能减少过拟合。
2、正则化项:正则化也叫惩罚因子,目标函数追求越小越好,可能他会无法无天的改变模型,我们加一个惩罚控制模型的趋势,让他模型不要太复杂,所以就有了L1、L2正则化
3、dropout
在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。那么具体到代码怎么干呢?
在没有dropout时,代码如下图所示,就是简单的一个感知机。
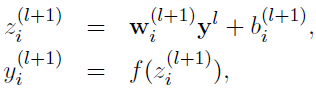
引入dropout后,我们需要首先生成一个概率参数,值为0/1的一个序列,让y去乘这个概率,实际就让某些输入变为0,其实就是上一层的神经元白计算了,没有向后传播。
这样搞有一个固定的比例k代表我们要禁止多少比例神经元,如果禁止掉0.4,那么相当远其他神经元的权重作用就会增加,测试时我们还需要对每个神经元乘(1-k)。让他发挥0.6的作用(好好理解下)
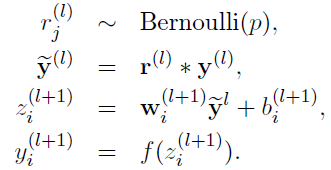
为什么说dropout具有防止过拟合的效果:
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
贴个代码,大家看看
import numpy as np
# dropout函数的实现
def dropout(x, level):
if level < 0. or level >= 1: # level是概率值,必须在0~1之间
raise Exception('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
# 我们通过binomial函数,生成与x(x表示输入数据,要对其dropout)一样的维数向量。
# binomial函数就像抛硬币一样,我们可以把每个神经元当做抛硬币一样
# 硬币正面的概率为p,n表示每个神经元试验的次数
# 因为我们每个神经元只需要抛一次就可以了所以n=1,size参数是我们有多少个硬币。
# 即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
sample = np.random.binomial(n=1, p=retain_prob, size=x.shape)
print(sample) # 【0,1,0,1。。。】有点像独热
# 0、1与x相乘,我们就可以屏蔽某些神经元,让它们的值变为0。1则不影响
x *= sample
print(x)
# 对余下的非0的进行扩大倍数,因为p<0。0/x=0,所以0不影响
x /= retain_prob
return(x)
# 对dropout的测试,大家可以跑一下上面的函数,了解一个输入x向量,经过dropout的结果
x = np.asarray([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=np.float32)
dropout(x, 0.2)
参考文献
[1] 详解深度学习中的Normalization,BN/LN/WN:https://zhuanlan.zhihu.com/p/33173246
[2]深度学习中Dropout原理解析
[3]Batch Normalization反方向传播求导
[4]Batch Normalization梯度反向传播推导
