激活函数;梯度消失梯度爆炸问题;损失函数;反向传播;
文章目录
一、激活函数
1.什么是激活函数?激活函数是干什么的?
激活函数是在神经网络每一层卷积或者全连接后的非线性函数部分。
她是干什么的?如果没有激活函数只有前面的全连接的话,相当于整个神经网络只有线性函数,每一层都是权重与输入的乘机,网络的拟合能力有限。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
2.常见的激活函数
记住下图就可以了
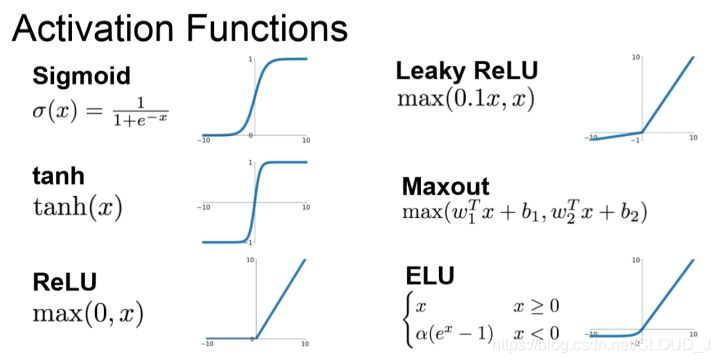
3.为啥relu用的比较多?relu的优点?
1、sigmoid激活函数以及tanh激活函数容易产生梯度消失现象;relu解决了梯度消失问题。
2、sigmoid计算量较大,而relu计算量较小。速度快
3、relu会使得负数为0,使得网络具有一定稀疏性,提高网络表达能力,抗过拟合特性。(但是这也使得一些神经元未被激活…)
4.为啥sigmoid会有梯度显示现象?
看第二部分“梯度消失”
二、梯度消失、梯度爆炸
1.梯度消失的例子
举个例子,对于一个含有20层隐藏层的简单神经网络来说,当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。
注意:浅层是指靠近输出端;深层是靠近输入端的;
2.梯度消失与梯度爆炸
梯度计算前层上的梯度的计算来自于后层上梯度的乘积(链式法则)。当层数很多时,就容易出现不稳定。如果激活函数求导后与权重相乘的积大于1,那么层数增多的时候,最终的求出的梯度更新信息将以指数形式增加,即发生梯度爆炸,如果此部分小于1,那么随着层数增多,求出的梯度更新信息将会以指数形式衰减,即发生了梯度消失。
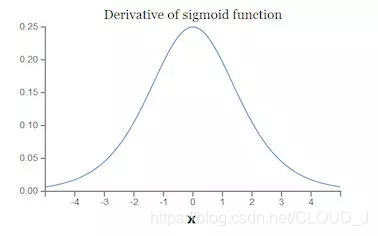
3.分析sigmoid梯度消失
sigmoid的函数求其导数得到下图,可以看出当x为0时梯度最大为0.25,而且当x稍微偏大或者偏小会趋近于0。
两个角度理解:
A)一个梯度最大为0.25,当层数增加后,不断向深层传播会出现0.25*0.25…越来越小,梯度消失。
B)某一层梯度可能会因为输入过大导致出现为0的时候向前传播就危险了!梯度会随着输入的变化而变化。
那么为啥人家relu就好呢!!!
relu其实长得非常像一个线性函数。(认真看!)
1)sigmoid函数的梯度随着x的增大或减小和消失,而ReLU不会。输入大于0就是1,输入小于0就截止了。
(这一点呢,后来出现leakRelu)
2)它让负数输入的时候为0.1x,稍微激活一下…缓解relu的负数为0的问题,但是我考虑按照sigmoid的第一条问题的话leakrelu也有,负数为0.1,不断传播就越来越小,但是呢,他没有趋近于0的时候,所以相对于sigmoid好太多!!!!!
4.解决梯度消失的方法
1、换激活函数
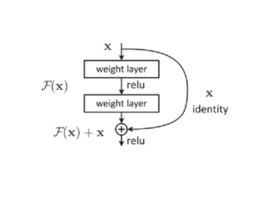
2、残差网络(这个后面详细说)
就是下面这个图,当初就是有了它,网络的层数瓶颈打开了!!
可以看出后一层有一个 +x ,梯度就是+1,这个好,梯度不会变的越来越小了。
网络再深也不会消失了。
3、BN批量规范化(BatchNormalization)
老牛逼了,现在几乎所有的网络都加个这个!后面详细说
4、LSTM网络
这个循环神经网络具有记忆功能,可以缓解梯度消失。
5、权重初始化注意一下
比如用个高斯分布初始化;因为有一部分原因在于权重初始化值过高导致函数的值发生梯度爆炸

5.实验过程中怎么发现是否有梯度消失或者梯度爆炸?
1、我们会看一下某些层的梯度变化,是否出现越来越小,是否出现爆表。
2、权重是否会变为Nan?
3、梯度快速变大变小。
三、损失函数
1.交叉熵
深度学习中一般用交叉熵这个损失函数。
交叉熵损失函数刻画的是两个概率分布之间的距离。如下式,交叉熵刻画的的是通过概率分布q来表达概率分布p的困难程度,其中p为真实分布,q为预测,交叉熵越小,两个概率分布越接近。
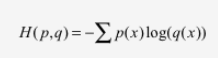
在深度学习中,对于一个多分类问题,一般用softmax将最后的全连接层啥的转为一个概率分布的情况,softmax如下式。其实就是用了个指数,然后分母是每个数据所对应各类得分的总和,分子是他的标签类所对应的分数,这样就转为一个概率了。再用上面那个交叉熵。
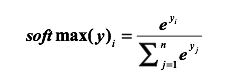
实际
2.为啥人们选择交叉熵
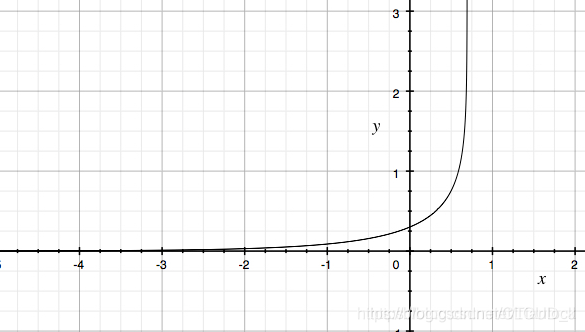
交叉熵的曲线如下图所示,他是一个凸函数,有一个最低点,利于loss梯度下降法优化。
3.回归问题损失函数
均方差(MES, Mean square error)

均方根误差RMSE
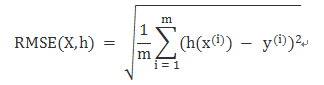
参考文献
[1]深度学习中常用损失函数https://blog.csdn.net/Tianlock/article/details/88232467
