论文:XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
Github:https://github.com/allenai/XNOR-Net
yolo的作者Joseph Redmon 作为三作的论文,论文提出了
权重二值网络(Binary-Weight-Networks(BWN))和全二值 异或网络(XNOR-Net)
本篇文章是在Binary-weight-network(BWN)和BinaryConnect(BC)两篇文章基础上做出改进。主要改进有两点:
1.在对权重进行{-1,+1}量化的同时,加入了尺度因子α;
2.除了对权重进行量化,还对特征值进行了量化,同样引入了尺度因子β,不过β因子重要性不及α。
论文翻译
https://blog.csdn.net/weixin_37904412/article/details/80604425?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
背景
其他方法
剪枝:
1)Hessian矩阵剪枝
2)权重排序剪枝
3)减少激活函数
4)hash函数压缩
dropconnect指出二值化是一种正则化,利于提高精度。本文也证明了BNN 的方法不适合大数据集Imagenet,也就是B CNN
2 B CNN
首先通过文章第一幅图来大致说明量化为何能够压缩和加速网络:
为何第二行包括实数,却没有乘法了呢,哦,只改变原数据的正负,取反符号位即可,再做浮点数加法。对吗?

BWN
只二值权重W

利用α把二值矩阵近似成全精度矩阵。
已知W 求解 α 和B
就像神经网络,知道真值,损失函数,用SGD等优化算法求权重和偏置;
那么完全可以也用优化算法求a和B啊
转换为优化问题
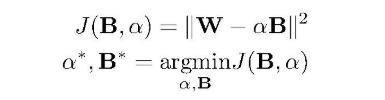
拆开,W是一个已知变量,
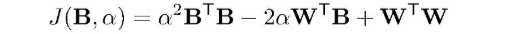
只有一个变量,可以再转化为:
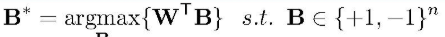
肉眼可解,最优的方案就是
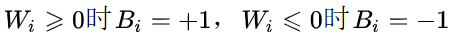 ,
,
即:
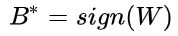
B就是 W的符号,±1
下面就是求最优α,一元二次方程最小值在对角线:
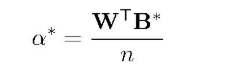
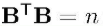
BTB = n ,n = channel * w * h为权重矩阵的元素个数
代入B*,矩阵乘自己的符号累加,负的变正的,正的还是正的,然后加起来。这就是L1L1范数。
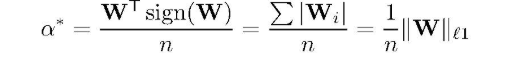
训练方法

两个过程:
- 前向传播用二值,
- 求导反向的时候,最后更新的是高精度W,
所以需要对二值W~进行链式法则求导。
而对二值W~求导涉及到了符号函数的求导,怎么办?
就在前人肩膀上不做改变,使用BNN的Htanh()(crop())函数,可见上篇文章
权重更新公式是反向里最麻烦的,具体推导如下:
估计值由上边公式代入可知:
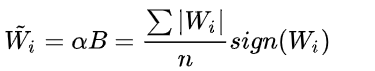
Wi更新公式:利用链式法则和代入,再根据对估值用乘法的求导,前后导数的和(公式里的α分别用了代入和没代入的,不知道作者为啥这样写,感觉不够统一不方便理解):
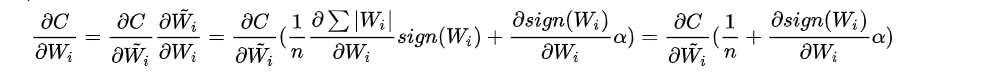
更新之后的 W会得到新的α B,αB就是W~,继续前传。。。
因此核心就是多了个尺度因子α,
Q:但是α也是实数化的矩阵啊,真的起到简化的作用了吗,B也不能算是最后权重,不知道所欲为何
先看全二值吧
XNOR
把激活值输入X也作二值近似,
上述的优化是对W,这里进一步,XW
整体看,就是
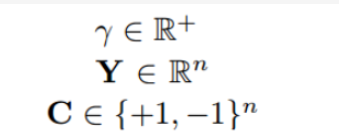
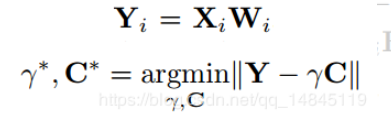
与上一节衔接,利用已有二值权重的话,把C拆开,就是X也做二值近似
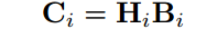
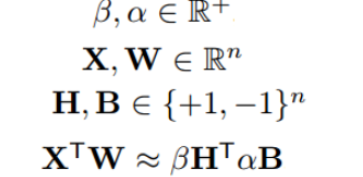
对激活值也量化X=βH,其中H也是{-1,1},β是它的尺度系数,
优化转换为
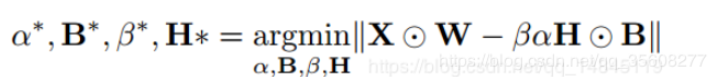
圆圈点表示elentment-wise乘积,逐个点乘积,
Q:这里为啥把矩阵乘法变成点积?
暂时不管,先按照上节的解法求C*,r*
求解
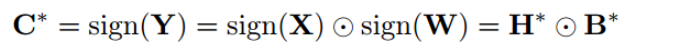
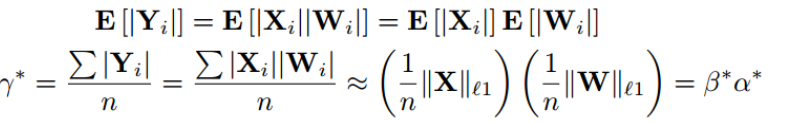
Q:这个近似多除以一个n,可以近似吗?
卷积操作有冗余,咋办
原算法是先算出每个位置(X)的β和H, 其中β = (1 / n)* || X ||,n-=channelwh
实际上H矩阵就是对原矩阵进行sign操作而已,根本没必要对每个位置(X)求对应的H,直接对输入 I 实际上是一个更为简洁的做法 。既然如此,何不直接先算出每个位置对应的β,形成一个β矩阵,然后β矩阵和sign( I )就代表输入的量化了。
实际上减少channel维度的多次冗余。
先对输入I在通道维度求绝对值的均值得到
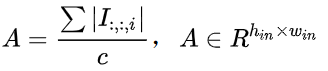
然后让A和2D的卷积核k做卷积得到K=A*k
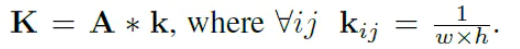
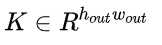
A矩阵和均值滤波器k 卷积 对A矩阵均值滤波后得到K矩阵,K矩阵的每个元素实际就是每个位置(X)对应的β,包含了输入I对应的所有缩放因子 β
Q:为什么平均之后就可以去了冗余呢
这样在带入
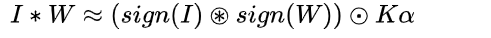
这里的 ※表示的是只使用XNOR和bitcount操作,卷积包括重复shift操作和点乘,shift指的是filter在输入图上进行移动,当输入输出都变为二值时,将权重和激活值的尺度系数提取出来之后,卷积可以变成xnor-bitcounting操作。
前向传播
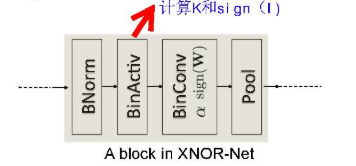
反向传播与BWN算法相同
plus
可以二值化梯度
可以通过位操作来提高训练效率。
可以kbit 量化
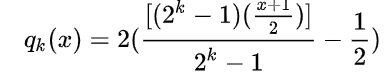
效果
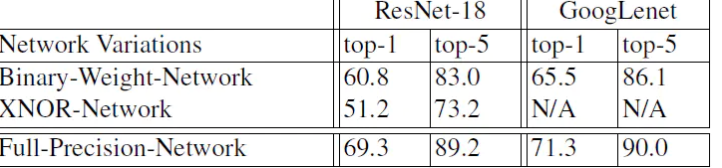
上面部分花了很大篇幅去求β矩阵,但是作者实验发现,其实没有β因子,对结果影响不大,所以,代码压根没算β矩阵
CODE
https://github.com/jiecaoyu/XNOR-Net-PyTorch
https://github.com/cooooorn/Pytorch-XNOR-Net
ref
https://www.jianshu.com/p/8a32eae3415e
