1、无信息搜索(只有信息的一些真实的条件)/有信息搜索(除了真实的条件还有一些估计的条件,以让我们能够定义评价函数。比方说上面的罗马问题中给出节点间的直线距离)
2、有信息的搜索策略
a、有额外信息辅助预测
b、贪婪最佳优先搜索
3、最佳优先搜索:
a、基本思路:通过对每一个节点计算评价函数f(n)值,找到一个f(n)最低的未扩散的节点。和一致代价搜索很像。但是这里的评价函数是估计值,而一致搜索中的代价是计算真实值。
b、实现:队列中的节点按照评价函数从低到高排列
c、大多数评价函数由启发函数h构成:h(n)节点n到目标节点的最小代价估计值。
4、贪婪最佳优先算法
a、首先扩展与目标节点估计距离最近的节点(比方说罗马尼亚问题中用两点间的直线距离来估测两点之间的实际距离)
b、不一定最优,具有完备性,时间复杂度为bm,空间复杂度为bm,b为分支因子数,m为层数
c、不是最优,因为计算的是剩余长度,没有考虑当前节点与下一个节点之间的距离
5、a*树搜索算法
a、就是对贪婪的改进,引进了当前节点与下一节点的距离
b、评价函数f(n)=g(n)+h(n):f(n)通过节点n到达目标节点的总评估代价(距离);g(n)到达节点n已花费的代价;h(n)节点n到目标节点的评估代价(距离)
c、类比一致代价搜索,代价是估计值,为当前代价+估计代价。
d、最优,具有完备性,时间复杂度为bm,空间复杂度为bm,b为分支因子数,m为层数
6、启发函数h(n)是可采纳的条件:对于每个节点n,h(n)<=h*(n),其中h*(n)是到达目标节点的真实代价,即要求路径上的任何一个节点与目标节点的估计距离小于直线距离。
a、可采纳启发函数绝不会高估到目标节点的代价,因此是最优的
b、定理:若启发式函数h(n)是可采纳的,那么使用a使用树搜索是最优的。
c、证明:假设start为开始节点,G为目标节点,n在最短路径上,G2是局部最优。那么只要证明f(G2)>f(n)<证明路径是最优的>和f(G2)>f(G)<没到达G之前,G2不会出队>即可。
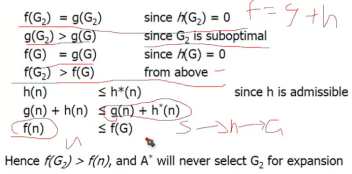
7、启发函数h(n)是一致性的条件:若当前节点n到达G的估计距离<当前节点n到达n’的实际距离+n’到G的估计距离,那么就是一致的—》n与n’之间的估计距离小于实际距离。即要求任何两点的估计距离小于直线距离。
a、一致性是可采纳性的特例,类比于图搜索是树搜索的特例
b、当启发式算法只能满足可采纳性而不能满足一致性,那么此时树搜索是最优的,但图搜索不是最优的;若满足一致性,那么搜索结果应该相同。
c、定理:若启发式函数h(n)是一致的,那么使用a使用图搜索是最优的。
d、证明:A根据f值从小到大扩展结点;A选择扩散结点n时,就已经找到了达到结点n的最优路径。如若不是,假设存在另一个边缘结点n’在到达n的最优路径上,因为由一致性可得到f(n’)<f(n),所以n’会被优先选择。
8、启发式函数设计:
a、八数码问题:
①、状态:八个棋子在九宫格上的分布
②、初始状态:任意状态
③、行动:上下左右
④、转移模型:状态+行动->新状态
⑤、目标测试:检查状态是否匹配目标状态
⑥、路径消耗:1)行动
⑦、平均解的深度是22
⑧、平均分支因素是3
b、两个启发式函数样例:
①、h1(n)—不在位的棋子数
②、h2(n)—所有棋子到其目标位置的距离和
③、以上两个都是可采纳的
9、有效分值因子:
a、对于某一问题,如果A算法生成的总结点数为N,解的深度为d,那么b’就是深度为d的标准搜索树为了能够包括N+1个结点所必需的分支因子。即所有节点之和:N+1=1+b’+(b’)2+…+(b’)d
b、有效分值因子越小,算法性能越好。最小是1,说明初始节点到目标节点只要一条直线就可以找到,都不需要回溯
10、对于所有节点,若h2(n)>=h1(n),那么说h2有优势,即更接近于真实估计的函数更有优势
11、松弛问题:
a、减少了行动限制的问题称为松弛问题
b、松弛问题增加了状态空间的边
c、原有问题的任一最优解同样是松弛问题的解,但松弛问题可能存在更优的解
12、某些问题中,不是找到目标状态的路径,而是目标状态本身——局部搜索算法:
a、从当前状态出发,通过行为到达他的邻近状态而不保留搜索路径
b、优点:很少的内存、能在很大或无限的状态空间中找到合理的解
13、爬山法:
a、只要发现上坡就向上爬,直到当前位置周围只有下坡
b、空间复杂度不高
c、不一定找得到最优解,只能找到局部最优解
d、不完备,比方说n皇后问题
14、模拟退火算法:
a、爬山法每次都向当前最优方向,也就是路径是一定的,因此可能陷入局部最优
b、模拟退火算法是爬山法和随机法的结合
c、思想:允许算法向坏的方向移动以摆脱局部最优值,但是这种移动随着时间的推移概率逐步下降(1、随着时间的推移,距离最优点越近;2、在邻近最优点的时候,算法容易发生震荡而不收敛);最初允许更大概率选择坏方向,随着时间推移向好方向。
d、算法初期向坏的方向移动更加有利于找到全局最优
e、模拟退火算法每执行一次基本都不同
f、如果时间下降的足够慢,则可以找到最优值
