1、局部束搜索:
a、随机产生k个状态,然后每一步从所有的后继状态中选择k个最佳的后继状态(也有健康度函数,详见下文)直到找到目标状态(内存中同时保留k个状态),增大了找到全局最优的概率。
b、相当于多个人去找,或者多次爬山法。
c、状态越多,找到最优的可能性越大
d、空间复杂度高;时间复杂度大;来自同一个父节点的子节点可能非常相似,可能导致同样的一个局部最优,从而减小了找到全局最优的可能性。
e、可以通过每个状态各产生一个最佳后继状态(待验证)
2、随机束搜索:不找k个最佳,而是随机找到k个后继状态,随机概率与状态值(这个状态好不好)成正比,又引入了随机性减少了子节点的相似性。状态值越好,越可能被随机选中。
3、遗传算法:模拟生物学上的有性繁殖,然后进行人工培育。
a、以k个随机产生的状态开始(遗传了局部束算法的特点)
b、一个后继状态由两个父状态决定(增加了子状态的多样性和进化的可能性)
c、通常一个状态表示成一个字符串
d、定义一个健康度量函数用来评价状态的好坏程度。
e、以八皇后问题为例,非冲突的皇后对数量最小为0,最高为(87)/(12)=28,因此如果有四个样本,分别有24、23、20、11对非冲突皇后,那么计算出概率为24/(24+23+20+11)=31%,得到四个样本被选中产生子节点的概率。
f、然后选择n个样本进行两两配对,产生新的子样本(以皇后问题为例,进行交叉互换,随机选择一个断开点,然后交叉互换样本值,产生新的样本)
g、还需要发生基因突变,随机选择一个样本的一个位置,然后将其随机更改为一个合适的值。
h、通过选择、交叉、突变的操作产生下一轮的状态。
i、设计代码的时候尽可能避免自交。
j、当健康度曲线比较平滑和缓慢的时候就可以结束。跑一次不一定能找到最优解,但有找到最优解的可能。
4、使用不确定性动作的搜索:
a、环境是完全可观察的和确定的
b、环境是部分可观察的或不确定的(当前行为不能确定下一行为,或者有概率)
5、无观察信息搜索:
a、可能有解,也可能无解
b、agent感知不到任何信息,称为无传感问题,也称为相容问题
c、信念状态:可能状态的集合
d、在信念状态解无观察信息的问题
e、信念状态:
①、假定n个可能状态时,信念状态有2^n个
②、目标状态:信念状态中所有物理状态都是
6、部分可观察信息搜索:通过移动之后感知的状态反推出上一状态
7、博弈:竞争环境中多个agent之间的目标是有冲突的,称为对抗搜索问题,也称为博弈。
8、特点:问题复杂,注重时间效率(时间要求高),实时性强;
9、博弈一般都是有完整信息的,确定的,轮流行动的,两个游戏者的零和游戏(利弊等值,结果加起来等于0)
10、零和游戏:在严格竞争下,一方的收益必然意味着另一方的损失,博弈各方的收益和损失相加总和永远为“零”,双方不存在合作的可能
11、博弈游戏,目的是寻找最优的方案使得自己能够利益最大化
12、效用值:表示状态好坏,效用值越大对max选手有利;越小对min选手有利
13、极小极大算法:
a、博弈树的最优策略通过检查每个节点的极大极小值来决定。max走有极大值的节点,min走极小值的节点
b、从一开始,就已经得到了所有的可能的下棋方式和可能的结果并记录了所有的方式的效用值,在分出胜负之后才进行回溯。
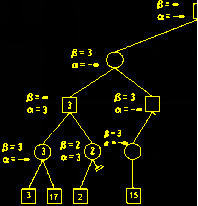
c、以下图为例:

上图中显示了所有候选方案。让我们如下分析:(注意:根节点为当前局面,某一结点的子节点为下一步走法产生的局面。图中的所有数字都是A的利益值,可以由估值函数得出,越大越有利于A)。
假设A选择第一个方案,B有两个候选方案,B为了使得A利益最小化,所有在7和3中选择了3,所以A只能获得3。
假设A选择第二个方案,B只有一个选择,A最终可以获得15。
假设A选择第三个方案,B有4个可选方案,为了使得A利益最小,B选择第一个方案,则A只能获得利益1。
A为了使得自己利益最大,所以A会选择第二个方案,即获得利益15。
从上图可以看出,B总是选择候选方案中的最小值,而A总是选择候选方案中的最大值,极小极大的名字也就源于此。该算法使用深度优先搜索遍历决策树来填充树中间节点的利益值,叶子节点的利益值通常是通过一个利益评估函数算。
注意,在不是自己的选择中填充的数字(即上图中的圆将会填充的数字)是选择了该条分支后对手做出反应后我能得到的实际的结果。

d、时间复杂度:bn,空间复杂度:bn,和深度优先类似。
e、搜索深度有限时是完备的,深度无限不完备
f、极大极小值是一个最优算法,因为遍历了所有的可能。
g、是一个嵌套递归(有一个max选手函数和一个min选手函数,直到游戏结束才终止递归)
14、多人博弈:存在一个联盟与破坏联盟的问题,所以不能简单地考虑让自己的值最大。用向量值取代单一值,通常选择使自己效用值最大的行为。
15、α-β剪枝:通过剪枝消除对部分状态的搜索
a、从一开始,就已经得到了所有的可能的下棋方式和可能的结果并记录了所有的方式的效用值,在分出胜负之后才进行回溯。
b、游戏状态数目的增长是指数级的
c、是否剪枝与分支排列顺序有关
d、if(u>b)then return u;a<–max(a,u)发生剪枝的部分
e、相当于极小极大法的升级
f、假设α为下界,β为上界,对于α ≤ N ≤ β: 若 α ≤ β 则N有解;若 α > β 则N无解。
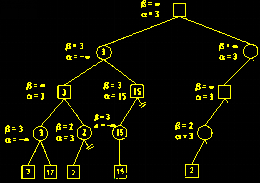
g、以下图为例:

上图为整颗搜索树。这里使用极小极大算法配合Alpha-Beta剪枝算法,正方形为自己(A),圆为对手(B)。
初始设置α为负无穷大,β为正无穷大。
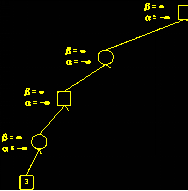
对于B(第四层)而已,尽量使得A获利最小,因此当遇到使得A获利更小的情况,则需要修改β。这里3小于正无穷大,所以β修改为3。
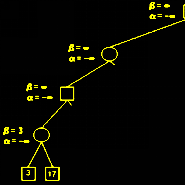
(第四层)这里17大于3,不用修改β。对于A(第三层)而言,自己获利越大越好,因此遇到利益值大于α的时候,需要α进行修改,这里3大于负无穷大,所以α修改为3。
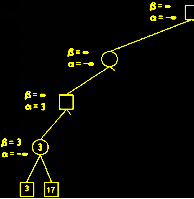
B(第四层)拥有一个方案使得A获利只有2,α=3, β=2, α > β, 说明A(第三层)只要选择第二个方案, 则B必然可以使得A的获利少于A(第三层)的第一个方案,这样就不再需要考虑B(第四层)的其他候选方案了,因为A(第三层)根本不会选取第二个方案,多考虑也是浪费。
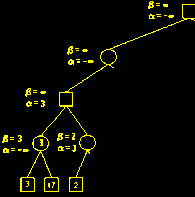
B(第二层)要使得A利益最小,则B(第二层)的第二个方案不能使得A的获利大于β, 也就是3. 但是若B(第二层)选择第二个方案, A(第三层)可以选择第一个方案使得A获利为15, α=15, β=3, α > β, 故不需要再考虑A(第三层)的第二个方案, 因为B(第二层)不会选择第二个方案。
A(第一层)使自己利益最大,也就是A(第一层)的第二个方案不能差于第一个方案, 但是A(第三层)的一个方案会导致利益为2, 小于3, 所以A(第三层)不会选择第一个方案, 因此B(第四层)也不用考虑第二个方案。
当A(第三层)考虑第二个方案时,发现获得利益为3,和A(第一层)使用第一个方案利益一样.如果根据上面的分析A(第一层)优先选择了第一个方案,那么B不再需要考虑第二种方案,如果A(第一层)还想进一步评估两个方案的优劣的话, B(第二层)则还需要考虑第二个方案,若B(第二层)的第二个方案使得A获利小于3,则A(第一层)只能选择第一个方案,若B(第二层)的第二个方案使得A获利大于3,则A(第一层)还需要根据其他因素来考虑最终选取哪种方案。
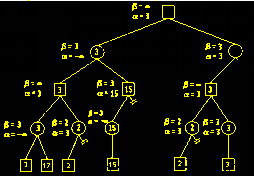
h、时空复杂度理论上与极小极大相同,可能在过程上有剪枝会有一点减小
i、执行结果是最优的
j、资源限制(阶段回溯):当遇到大的问题时搜索空间非常大,解决方法如下:
①、评估函数:
中间节点的结果与真实情况相同。即对中止状态的排序应和效用函数一致。
反映出的优势大小应该与取胜的概率成正比。即对于非终止状态和获胜的概率有关。
计算时间不能太长。
如国际象棋(特征加权法):未考虑时间因素对棋子数量差产生的局势差异的影响以及棋子位置。线性评估假定特征之间是相互独立的,然而实际中特征之间具有关联性。
②、截断测试:限制搜索深度或搜索时间;效用值替换为评估值,无法得到最优。
机器智能(四)

猜你喜欢
转载自blog.csdn.net/qq_40851744/article/details/105056876
今日推荐
周排行