语音识别之进行实时语音互动
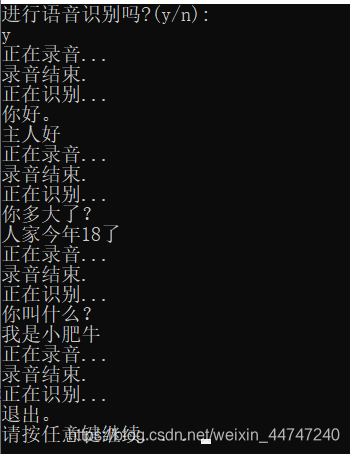
今天心血来潮,利用百度API语音识别,用python尝试做了一下语音识别的小互动,感觉还不错,记录一下过程,分享一下。已经完成了互动的过程,你说一句它说一句,无奈不能上传视频,效果不明显。
用到的东西呢
主要的是利用百度API
首先呢,需要拥有一个百度账号,登录百度智能云:https://ai.baidu.com/tech/speech,然后建立一个语音识别的应用。会得到ID\APIKEY\SecretKey

其中可以用两种方式调用:
可以下载使用SDK
不下载使用SDK:根据文档组装url获取token,处理本地音频以JSON格式POST到百度语音识别服务器,获得返回结果
#百度语音
APP_ID = 'xxxxxxx'
base_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s"
APIKey = "xxxxxxxxx"
SecretKey = "xxxxxxxxxxxx"
client = AipSpeech(APP_ID, APIKey, SecretKey)
HOST = base_url % (APIKey, SecretKey)
#获取token
def getToken(host):
res = requests.post(host)
return res.json()['access_token']
录音及识别相关函数
#保存语音文件
def save_wave_file(filepath, data):
wf = wave.open(filepath, 'wb')
wf.setnchannels(channels)
wf.setsampwidth(sampwidth)
wf.setframerate(framerate)
wf.writeframes(b''.join(data))
wf.close()
#录音
def my_record():
pa = PyAudio()
stream = pa.open(format=paInt16, channels=channels,
rate=framerate, input=True, frames_per_buffer=num_samples)
my_buf = []
# count = 0
t = time.time()
print('正在录音...')
while time.time() < t + 4: # 秒
string_audio_data = stream.read(num_samples)
my_buf.append(string_audio_data)
print('录音结束.')
save_wave_file(FILEPATH, my_buf)
stream.close()
def get_audio(file):
with open(file, 'rb') as f:
data = f.read()
return data
def speech2text(speech_data, token, dev_pid=1537):
FORMAT = 'wav'
RATE = '16000'
CHANNEL = 1
CUID = '*******'
SPEECH = base64.b64encode(speech_data).decode('utf-8')
data = {
'format': FORMAT,
'rate': RATE,
'channel': CHANNEL,
'cuid': CUID,
'len': len(speech_data),
'speech': SPEECH,
'token': token,
'dev_pid':dev_pid
}
url = 'https://vop.baidu.com/server_api'
headers = {'Content-Type': 'application/json'}
# r=requests.post(url,data=json.dumps(data),headers=headers)
print('正在识别...')
r = requests.post(url, json=data, headers=headers)
Result = r.json()
if 'result' in Result:
return Result['result'][0]
else:
return Result
主函数
if __name__ == '__main__':
engine = pyttsx3.init()
engine.say('进行语音识别吗?')
engine.runAndWait()
flag = input('进行语音识别吗?(y/n): \n')
while True:
my_record()
TOKEN = getToken(HOST)
speech = get_audio(FILEPATH)
result = speech2text(speech, TOKEN, int(1537))
print(result)
if type(result) == str:
openbrowser(result)
if result=='退出。':
break
