复杂度
- 空间复杂度(用层数和待优化的参数个数表示)
- 层数 = 隐藏层的层数+1个输出层(输入层不算)
- 总参数 = 总w + 总b
- 时间复杂度:
乘加运算次数
学习率
学习率是一个超参数,根据经验来设定,学习速率调得太低,训练速度会很慢,学习速率调的过高,每次迭代波动会很大,再反向传播的过程中会更新权值w

指数衰减学习率:可以先用较大的学习率,快速得到较优解,然后逐步减小学习率,使模型再训练后期稳定。
指数衰减学习率 = 初始学习率 * (学习率衰减率^(当前轮数/多少轮衰减一次))
激活函数
-
激活函数的定义:
激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端 -
为什么要有激活函数
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机。
如果使用激活函数,激活函数给神经元引入了非线性因素,使得神经网络可以逼近人任何非线性函数,这样神经网络可以用到多种非线性的模型中。 -
常用的激活函数
-
Sigmoid函数
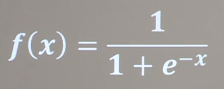

特点:- 容易造成梯度消失
- 输出非0均值,收敛慢
- 幂运算复杂,训练时间长
-
Tanh函数
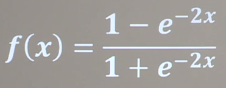

特点:- 输出均值是0
- 易造成梯度损失
- 幂运算复杂,训练时间长
-
Relu函数


优点:- 解决了梯度消失问题(在正区间)
- 只需判断输入是否大于0,计算速度快
- 收敛速度远快于sigmoid和tanh
缺点:
- 输出非0均值,收敛慢
- Dead RelU问题:某些神经元可能永远不会被激活,导致相应的参数永远不能被更新(不会被激活的原因:在负区间,输入特征为0,在进行反向传播的时候,梯度一直为0,不会进行参数的更新)
-
Leaky Relu函数


理论上讲,leaky Relu函数解决了输入特征为负区间的问题,但是在实际操作中,多用Relu函数
-
-
总结:(对于初学者)
- 首选relu激活函数
- 学习率设置较小值
- 输入特征标准化,即让输入特征满足以0为均值,1为标准差的正态分布
初始参数中心化,即让随机生成的参数满足以0为均值, 为标准差的正态分布
损失函数
损失函数表示的是预测值y与标准答案y_的差距,损失函数可以定量判断w、b的优劣,当损失函数输出最小时,参数w、b会出现最优值
常用的损失函数:
-
均方误差mse
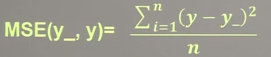
loss_mse = tf.reduce_mean(tf.square(y - y_)) -
自定义损失函数(根据实际情况进行自定义,相当于自己建立模型)
如预测商品销量,预测多了,损失成本;预测少了,损失利润。若利润不等于成本,则mse产生的loss无法利益最大化
自定义损失函数
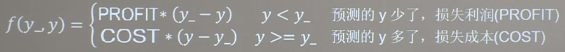
loss_zdy = tf.reduce_sum(tf.where(tf.greater(y,y_),COST (y - y_),PROFIT(y_-y))) -
交叉熵损失函数CE(Cross Entropy):表征两个概率分布之间的距离

Tf.losses.categorical_crossentory(y_,y)
例子:已知答案y_=(1,0) 预测y1=(0.6,0.4) y2=(0.8,0.2) 哪个更接近标准答案?
softmax与交叉熵结合 输出先过sofimax函数,再计算y与y_的交叉熵损失函数 tf.nn.softmax_cross_entropy_with_logits(y_,y)
下面的是笔者的微信公众号,欢迎关注,会持续更新c++、python、tensorflow、机器学习、深度学习等系列文章

