之前介绍的树模型属于弱学习器,本身的算法比较简单,但是与集成算法合并后,会产生更好的效果。比如:决策树+bagging=随机森林;决策树+boosting=提升树
这里先简单介绍下集成算法,然后对随机森林和提升树再做说明。
集成算法
集成算法:通过对多个模型进行组合来解决实际问题。
多个模型集成成为的模型叫做集成评估器,组成集成评估器的每个模型都叫做基评估器。

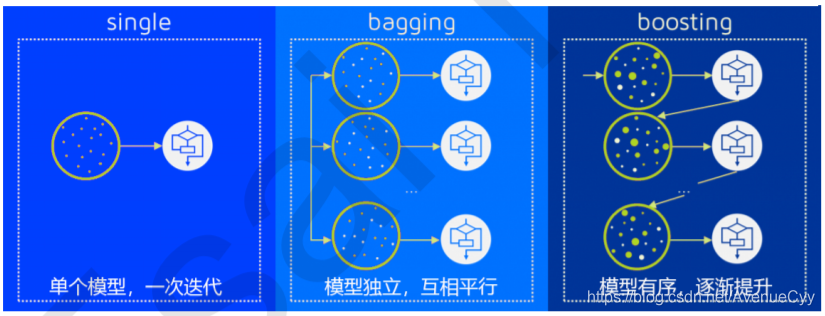
而这个“组合”的方式主要有以下两种:装袋法(Bagging),提升法(Boosting).
Bagging和Boosting是对于相同类型的个体学习器,这样的集成是同质;而对于不相同类型的个体学习器,这样的集成是异质。
按照同质弱学习器之间是否存在依赖关系可以将同质集成分类两类:
- 弱学习器之间存在强依赖关系,一系列弱学习器基本都需要串行生成(该弱学习器是对上一个弱学习器的结果进行处理),代表算法是Boosting系列算法;
- 弱学习器之间没有较强的依赖关系,一系列弱学习器可以并行生成,(弱学习器共同处理,互相独立)代表算法是Bagging系列算法。
Bagging
通过随机有放回的采样数据,而不同的数据就会产生不同的模型,T个数据就会产生T个模型,然后通过某种结合策略将这些模型结合得到结果。

大概有1/3的数据没有选中,在随机森林中(随机森林有oob),就可以进行测试,不需要单独划分交叉验证集。

结合策略
平均法
取其均值作为输出。

投票法
少数服从多数。

学习法
stacking:将初级学习器M个结果作为新的数据,再放入新的模型(次级学习器)中进行学习,得出最终的结果。比如将随机森林的结果放入线性回归中,多个模型叠加得到最后的结果。

Boosting
Bagging的弱学习器之间是没有依赖关系的,而Boosting的弱学习器之间是有依赖关系的,因此它的弱学习器是串行生成,利用上一步的结果。
先用弱学习器去训练,将结果与真实值进行比较,对预测错误的值赋予更大的权重,再放入下一个弱学习器中进行训练,以此往复。

Bagging与Boosting比较
Bagging:方差小(泛化能力强),偏差大(弱学习器的准确度不行),因此为了提升弱学习的拟合能力,降低偏差,选择深度较大的决策树(深度较深的决策树是过拟合的,正好弥补了偏差小的特性)。
Boosting:方差大(泛化能力弱),偏差小(弱学习器的准确度可以),因此为了降低弱学习的拟合能力,降低方差,选择深度较小的决策树(深度较小相对于深度较大的是欠拟合的,正好弥补了方差大的特性)。
这点在随机森林和GBDT调参时,决策树深度的大小上也能体现出来。


随机森林
随机森林是决策树和Bagging结合的产物。但自身又多了一些特点:
- 相比于Bagging的仅对数据的多少进行随机采样,随机森林又增加了特征的随机采样。
- 决策树采用的是CART,由于特征是随机选择的(放入模型的特征数小于数据原本的特征数),因此随机森林中CART树要比正常的CART规模要小,对训练集和测试集的效果差不多,鲁棒性比较好。
随机森林的算法流程:
其中决策树不剪枝是由于bagging偏差大的特点决定的。
对于结果,回归采用均值;分类采用多数投票。

随机森林优缺点
1.并行计算,速度快
2.基于CART树,可分类也可回归
3.由于特征是随机选择的,因此提取的特征量不是全部,可解决高维特征的问题,另外也能防止过拟合。但特征的随机抽取有利有弊,会对结果造成影响。


AdaBoost
AdaBoost算法:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时在每一轮中加入一个新的弱分类器,直到得到某个预定的足够小的错误率或达到预定的最大迭代次数。
- 加法模型:最终强分类器是若干个弱分类器加权平均得到。
- 前向分布算法:算法是通过一轮轮弱学习器得到,利用前一轮弱学习器的结果来更新后一个弱学习器的训练权重。
AdaBoost算法流程:
1.如何计算误差率
2.弱学习器权重系数α
3.更新样本权重D
4.使用哪种结合策略

Adaboost损失函数
第k-1轮和第k轮的强学习器为:
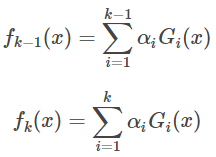
可以得到:
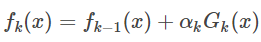
因为分类Adaboost损失函数为指数函数(指数函数可以明确表示数据分类正确or错误的情况),所以其损失函数如下
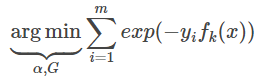
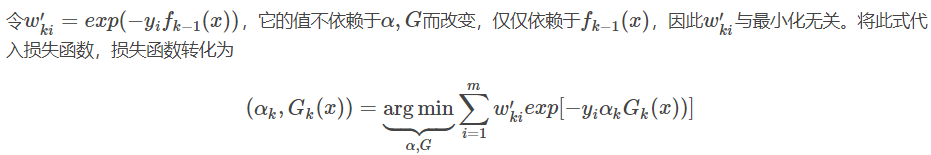
I(x=y)为指示函数。
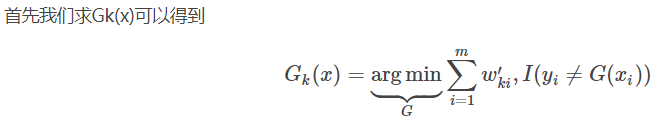

Adaboost分类算法
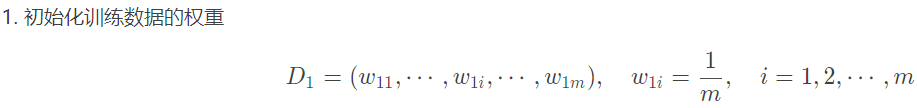

3.计算弱分类器Gk(x)在训练集上的分类误差率为;
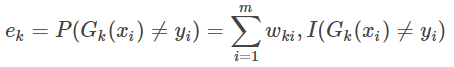
4.第k个弱分类器Gk(x)的权重系数为:
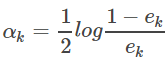
二分类问题的权重系数中,可以看出如果分类误差率e越大,则对应的弱分类器的权重系数α越小,即误差率小的弱分类器权重系数越大。
5.更新训练数据的权重
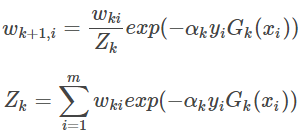

6.结合策略

Adaboost回归算法

5.计算第k弱回归器的误差率和权重系数
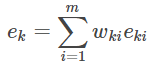
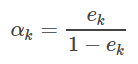

上面是别人详细的公式推导。对于AdaBoost要记住:
- 模型:加法模型,即将多个弱分类器加权求和来求得最后的结果。
- 目标函数是指数函数。
- 学习算法是前向分步算法,即后一个弱学习器训练数据的权重通过前一个弱学习器更新。
这里涉及到弱分类器的权重a(根据误差率计算得到),还有被分类错误的样本权重。分类:误差率,回归:均方误差。
AdaBoost算法优缺点

提升树
提升树是以CART为树模型的加法模型,不断拟合残差以逼近真实值。
举个例子:

提升树算法

这里经验风险极小化,针对不同的问题,采用不同的损失函数。回归问题使用平方误差损失函数,分类问题使用指数损失函数。一般决策问题使用一般损失函数。
回归问题提升树使用以下前向分步算法:
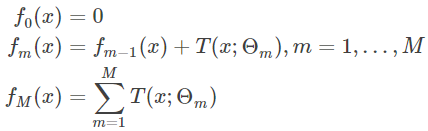
对于回归问题,根据真实值和最后一棵树的平方误差最小化,求解第M棵树参数θ。最后化简公式得到(r-T)^2最小化,即最后一棵树拟合前一棵树的残差,使其最小化。

回归提升树流程

提升树与AdaBoost算法
AdaBoost算法使用的是前向分步算法,即利用前一轮弱学习器的误差率更新训练数据的权重;
提升树使用的也是前向分步算法,弱学习器只用树模型(一般是CART)
提升树优缺点
对于回归提升树,只需简单地拟合当前模型的残差。

梯度提升树
GBRT是一种适用于具有任意阶可导损失函数的提升方法。
梯度提升
提升树利用加法模型与前向分步算法实现学习的优化过程。当损失函数是平方损失和指数损失函数时,每一步优化是很简单的。但对一般损失函数而言,往往每一步优化并不那么容易。一般损失函数
对这一问题,Friedman提出了梯度提升树算法,这是利用最速下降的近似方法,其关键是利用损失函数的负梯度作为提升树算法中的残差的近似值。

GBDT算法原理

GBDT回归计算案例
数据展示:
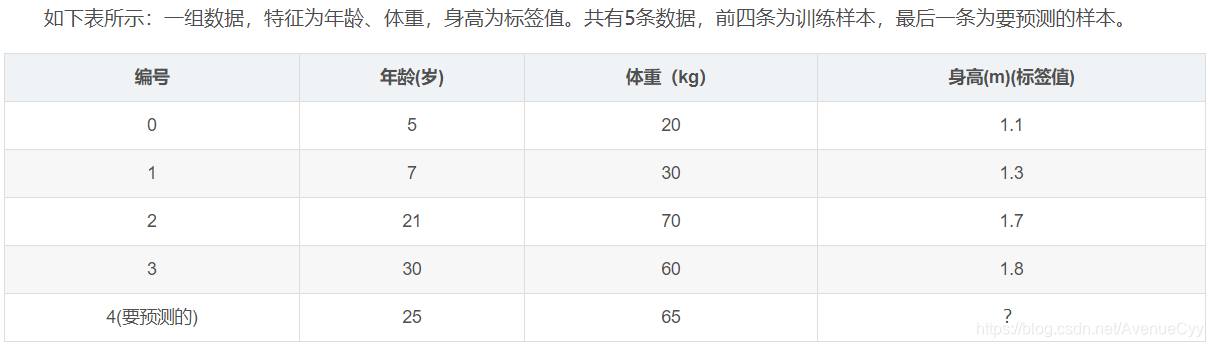
参数设置:

1.初始化弱学习器:

2.对迭代轮数m=1,2,…,M:
根据第一步初始化的弱学习器,计算要拟合的残差值。
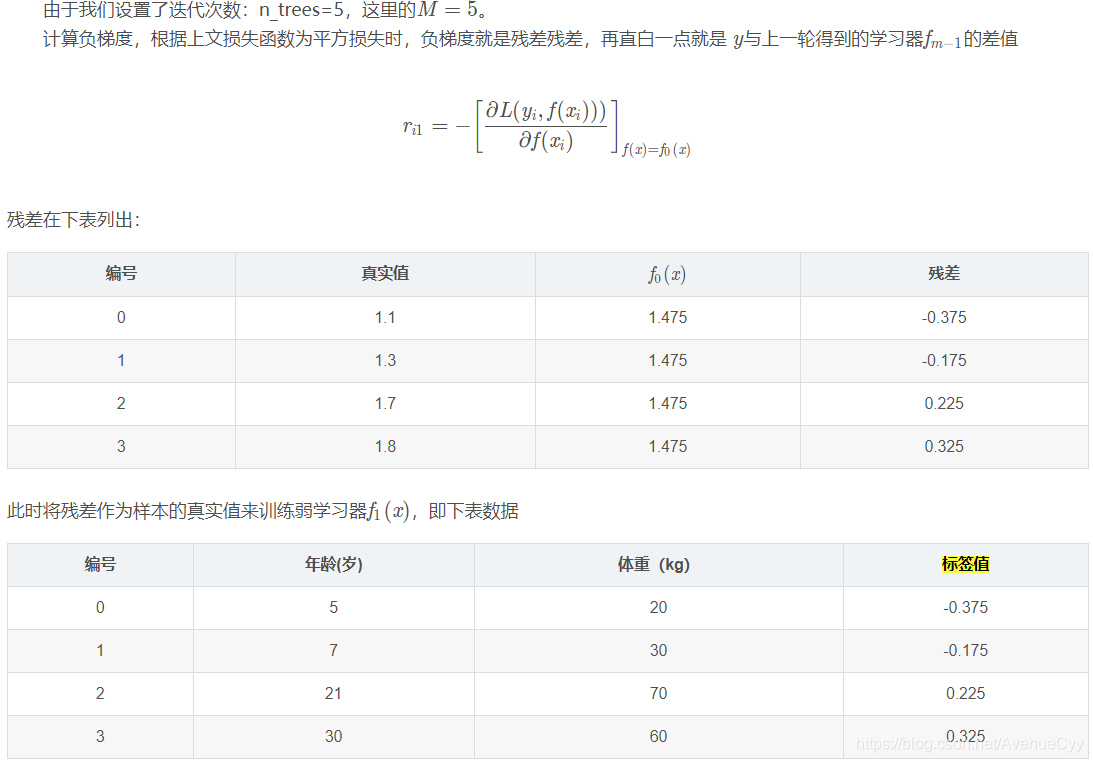
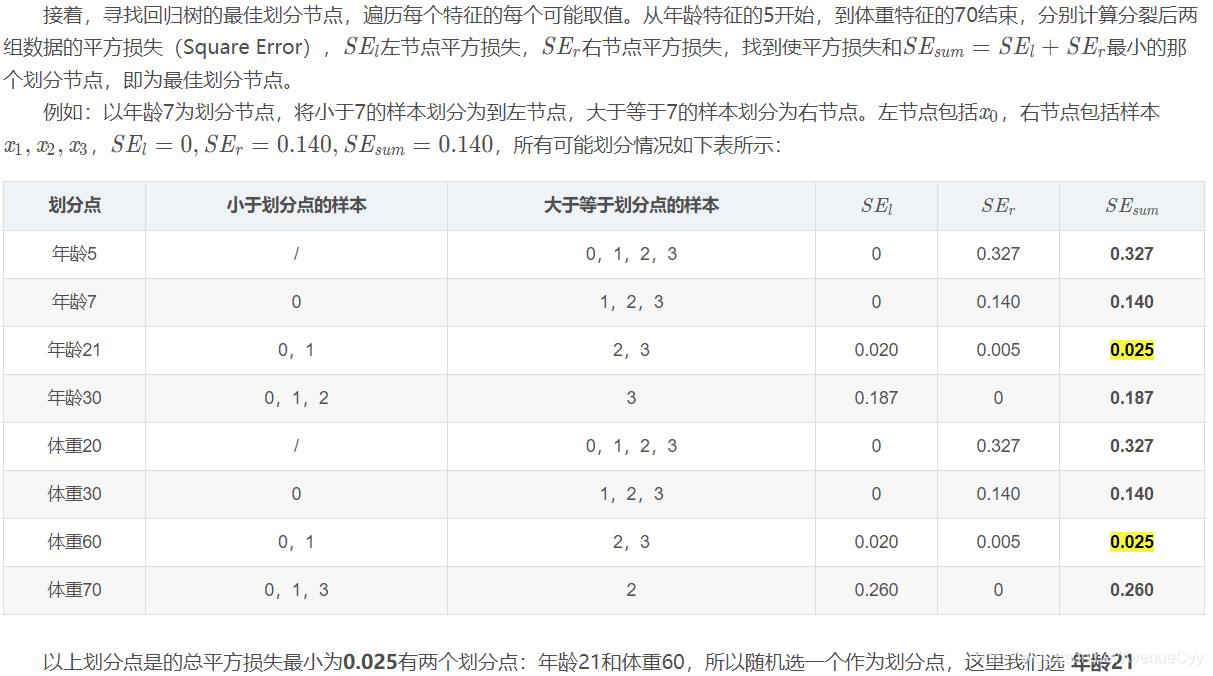
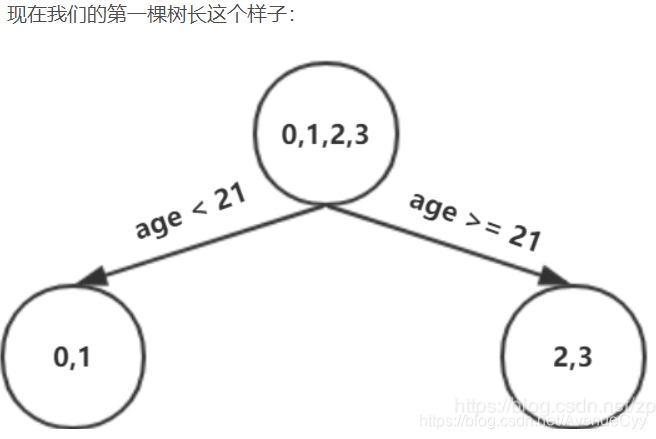
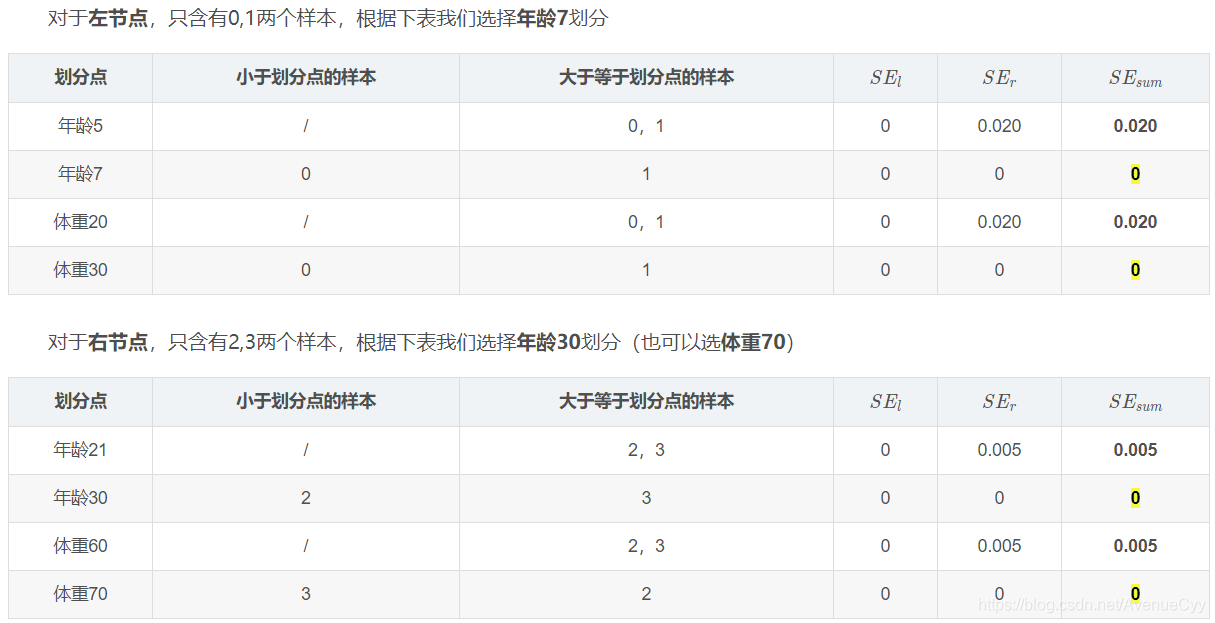
由于设置的最大深度为3,现在树的深度只有2,需要再进行一次划分,这次划分要对左右两个节点分别进行划分。
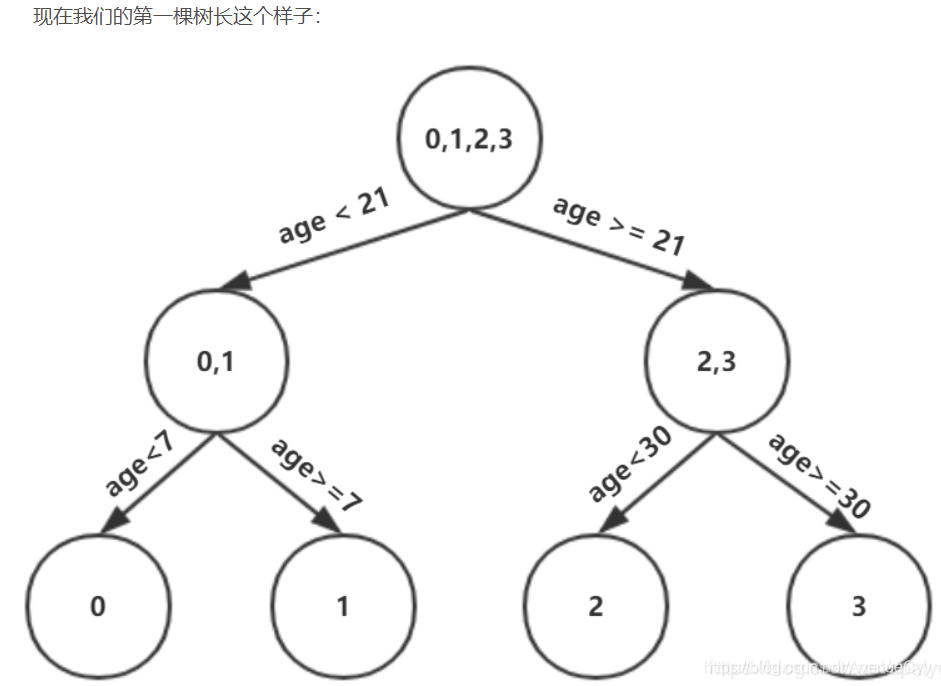
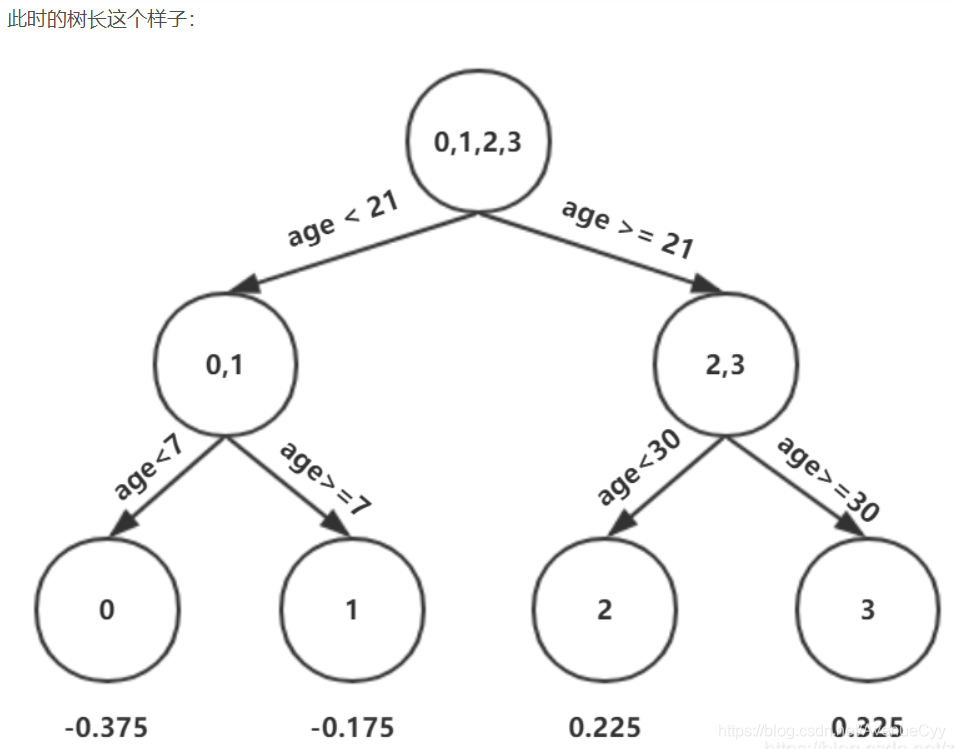
第一棵树对之前计算的残差拟合结果。

求出树的预测值。
学习率:

因为迭代次数为5,因此生成5棵不同的树。
将这5棵树进行整合,得到最后的模型
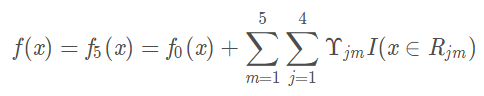

GBDT分类计算案例

GBDT和提升树的区别是残差使用梯度替代,而且每个基学习器有对应的参数权重。
梯度提升树优缺点
对于这个缺点,可用Xgboost来解决。

参考文献
https://blog.csdn.net/weixin_46032351/article/list/3
https://weizhixiaoyi.com/category/jqxx/2/
https://blog.csdn.net/u012151283/article/details/77622609
https://blog.csdn.net/zpalyq110/article/details/79527653
