本文主要参考B站UP主春暖花开Abela讲解的SVM,对SVM的学习进行的整理。另外也推荐B站的白板推导,对数学公式讲解的更为细致。
最优化问题
在一定条件下,解决求函数的最大/最小值的问题。

拉格朗日乘子法
拉格朗日乘子法计算模型如下。k为约束条件的个数,hk(x)为约束条件。

相切的时候取极值,此时两个函数的梯度共线,所以两个函数分别求导后,应该是线性关系。
将有约束的问题转为无约束的问题,然后直接对无约束问题求导即可。

KKT算法
处理不等式约束时的数学模型。

利用KKT条件构建拉格朗日函数。

具体的KKT条件如下:
1.对于构建后的拉格朗日函数,对x求导后,式子结果为0.
2.不等式前的系数要大于等于0.

对偶问题
如果原来的优化问题不容易求解,那么可以通过对偶问题进行求解。先求最大值,再求最小值。在满足KKT条件的时候,这样就等价于对原始的f(x)求最小值。

关于为什么两者是等价的问题证明。

对偶问题的定义。原来是对w求最小值,先对a和b求最大,然后求w得最小。对偶问题后,正好反过来,先求w的最小,再求a,b的最大。

min(max())>=max(min()),举个例子,比如说房价。min(max())是在一堆高房价中找最小的,比如北京;max(min())是在一堆低房价中找最大的,比如十八线的县城。前者必定会>=后者。下面是严格的数学证明:

正常是d<=p,只有放KKT条件成立时,两者才相等。

支持向量机
一般用于解决二分类的模型。对于左边的图形,可以找到无数条线来求解,但对于虚线来说,当样本增加时,很容易就会判断错误。相反,实线的效果就会好很多。
而支持向量机就是为了找到最优分化的实线,使其到两边支持向量的距离最大化。(两类样本距离最大化。)
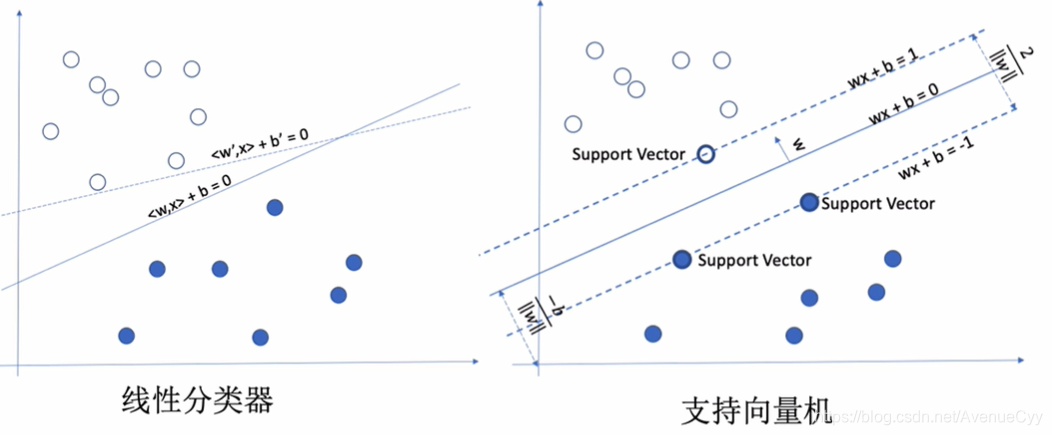
SVM数学模型
目的是求实线函数,也就是w和b,wx+b=0.
这里令两个类别的分割线分别为wx+b=1和wx+b=-1.这里的结果不为1也可以,如果为100,两边同时除以100,结果还是1,而另一边的w和b只是做了线性变换,不会影响结果。
两式相减求最大值。
利用余弦定理,两个向量的内积公式进行转换。
最后是让d1+d2的值取到最大即可。
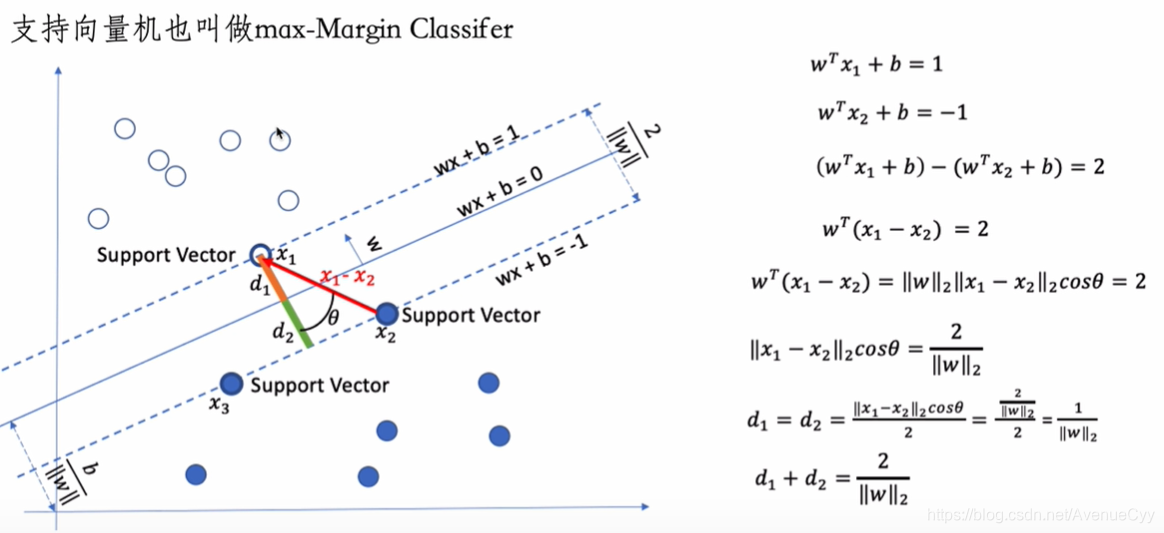
之前w在分母上,求最大,现在转为求w的最小值。
条件是真实结果和预测结果同号,即预测正确。
利用拉格朗日,转为无约束问题。

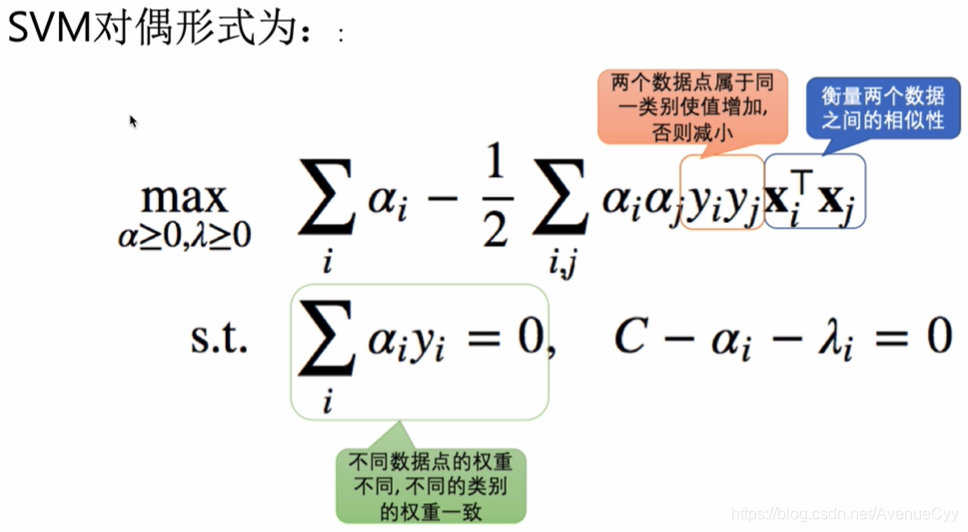
转为对偶问题进行计算。

最终计算的是支持向量上的样本点,别的不参与计算。

带有松弛变量的数学模型
以上的SVM是对完全可分的数据的,对于异常点却没有考虑。加入松弛变量可以规避异常点。
在某一个类别里,包含其他类别,此时必须放松限制。
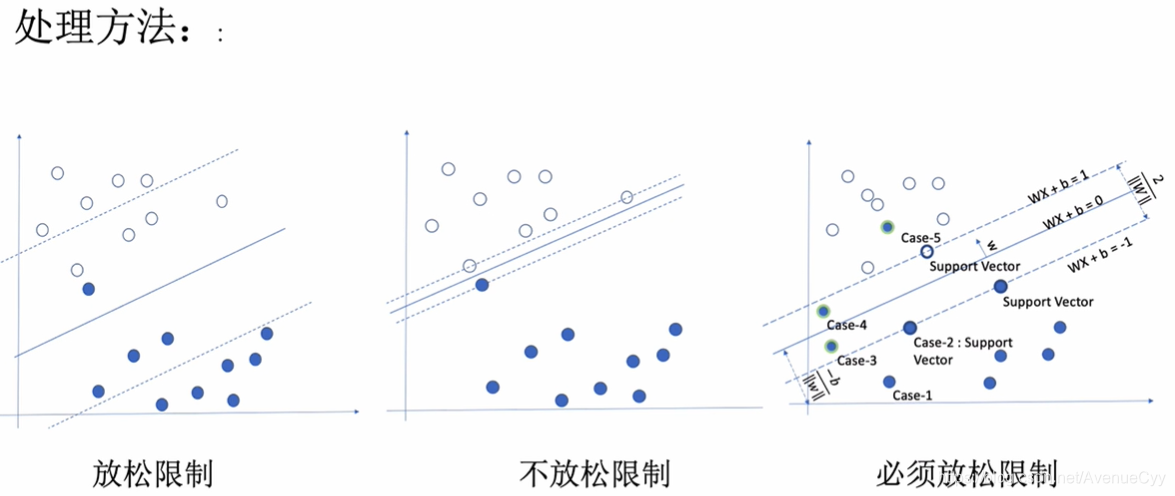
C是对松弛变量的惩罚,C越大,松弛变量越小,虚线的距离越小;C越小,松弛变量越大,虚线的距离越大。

分别求导,令其导数为0.

将求解的结果带回原式。
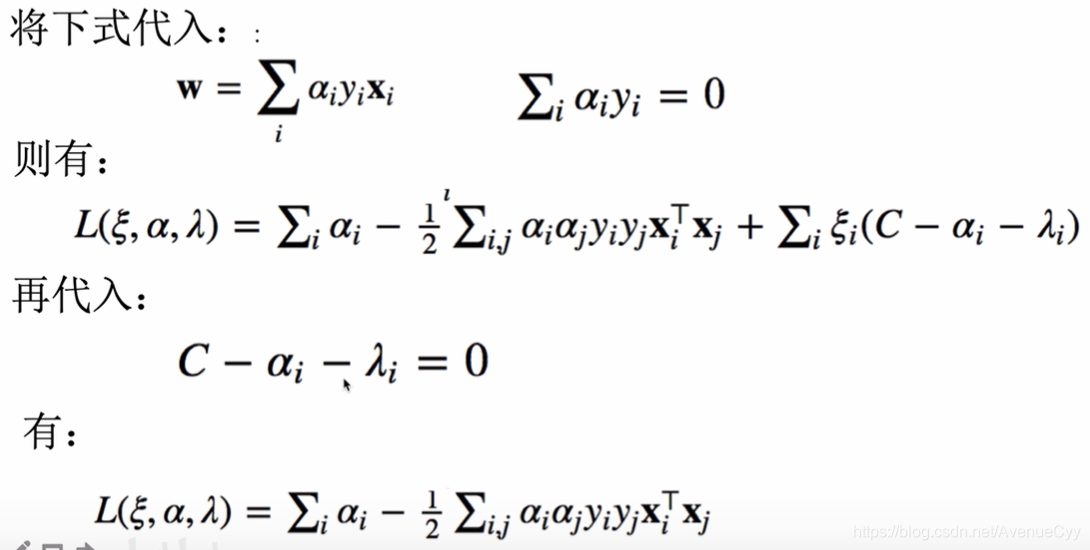
对偶形式与KKT条件。

核函数
对于线性不可分的样本,采用核函数。
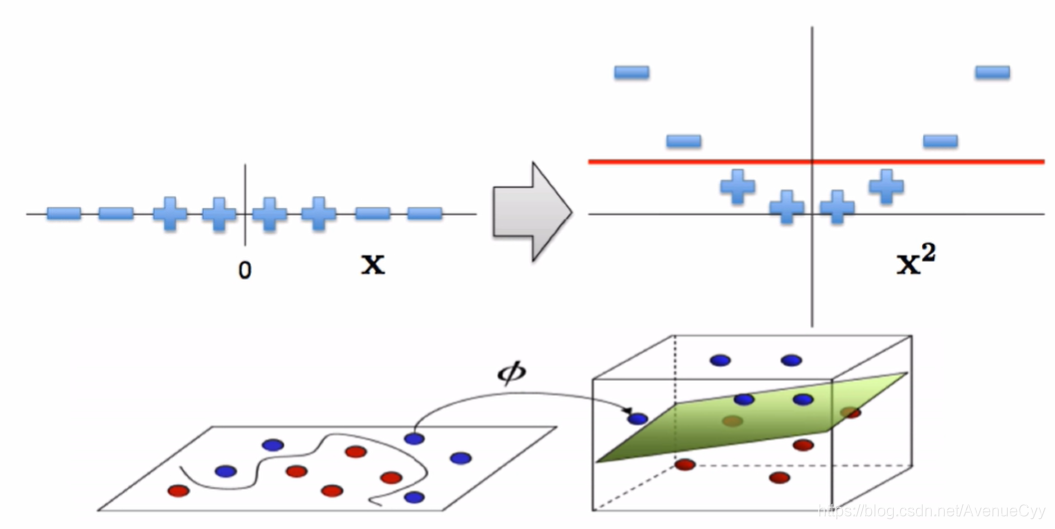
直接扩展到高维存在的问题:

换个方式来衡量两个数据的相似性。
添加核函数。

核函数的充要条件:

常见的核函数:
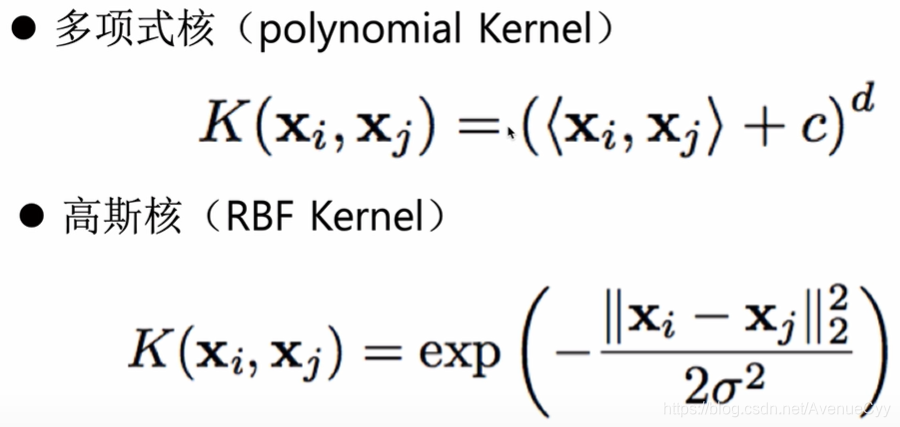

SMO算法求解SVM
先求y轴,再求x轴,再求y轴……固定一个变量,对另一个进行求解。


SMO选择两个变量,进行计算,其余变量不动。

因为其他变量固定,所以可看成常数

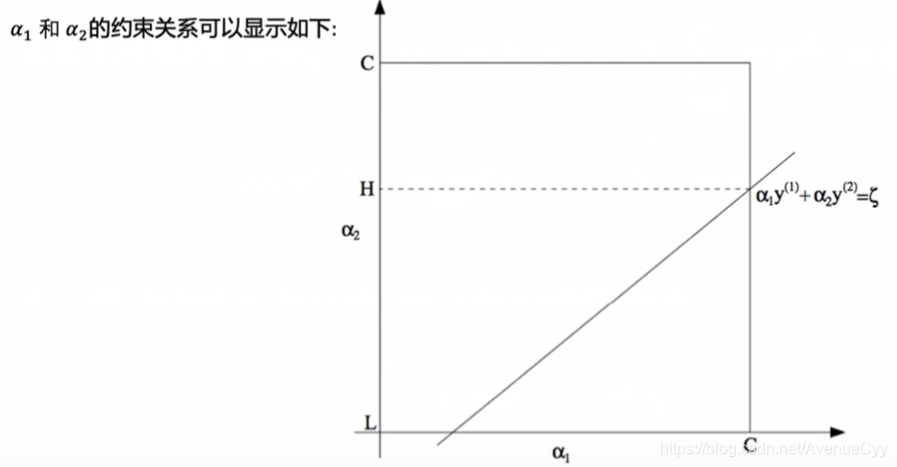

参数上下界证明:


SVM多类别样本分类
OVR
把整体样本看成两个类别,一个属于A,另外的属于非A,一个属于B,一个属于非B……这样在有K个类别时,需要建立K个SVM。判断哪个的概率最高,就判定为哪个类别。一般使用这个。

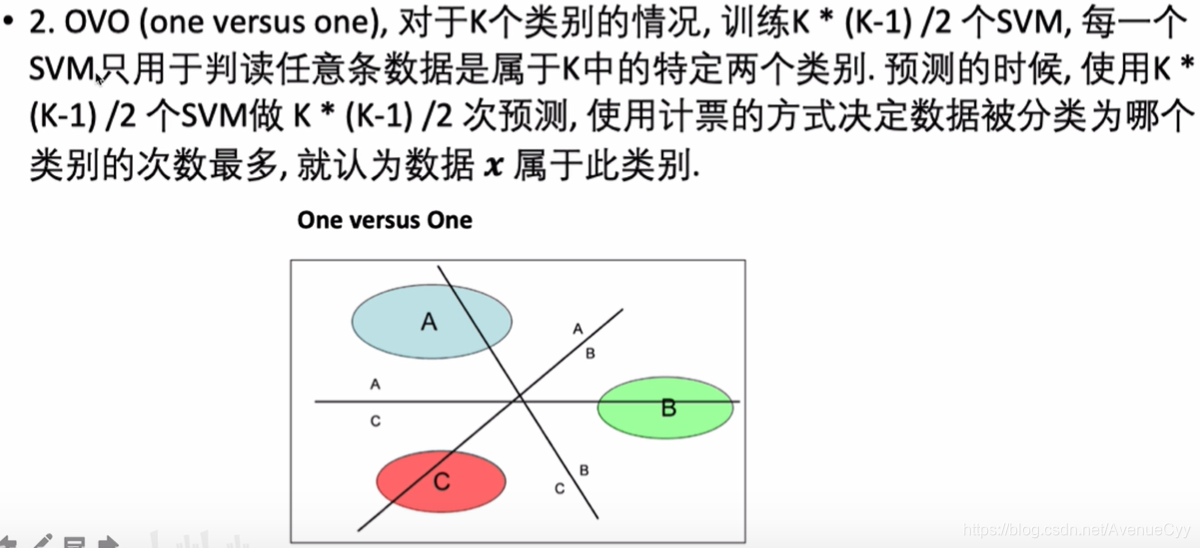
OVO
训练A和B,B和C,A和C这些分类器,进行分类。利用计票的方式来定数据属于哪个类别的次数最多,就判定数据属于哪个类别。
SVM的使用步骤
2.数据标准化,因为是用距离去度量的,因此要统一标准。

SVM的参数。

SVM优缺点
缺点还有一个是SVM的超参数对结果影响很大,因为超参数的调整直接影响的是支持向量的选择情况。一般C比gamma要大,C取1+以上的数,gamma取1-以下的数。

资料参考
https://www.bilibili.com/video/BV1ZE411p73x?p=7
