KNN简介
KNN是监督学习算法,其主要思想就是近朱者赤,近墨者黑。找出新样本与训练数据的最近的K个实例,哪个类别的个数多,就把该样本判定为哪一类。
下面用这个图进行下说明。如果选择离新样本最近的3个实例,那么圆被判定为三角,如果选择5个实例,那么则被判定为方块。
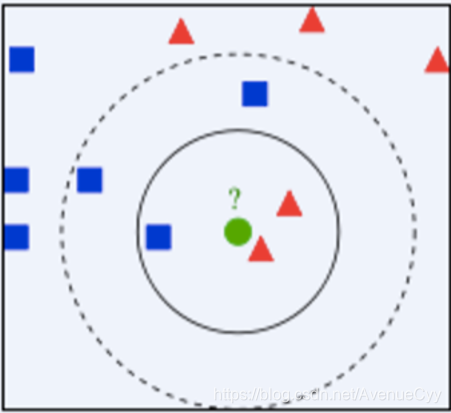
KNN工作原理
工作原理如下:
假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
- 计算新数据与样本数据集中每条数据的距离。
- 对求得的所有距离进行排序(从小到大,越小表示越相似)。
- 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
求 k 个数据中出现次数最多的分类标签作为新数据的分类。
KNN基本要素
通过上述原理的说明,可将主要参数归总为k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。
k值的选择
- 选择较小的K值,近似误差减小,估计误差增大,模型变得复杂。比较极端地想一下,如果K值等于1,那么就会拟合最近的样本,预测结果会对近邻的实例点分成敏感。如果邻近的实例点恰巧是噪声,预测就会出错,容易发生过拟合(容易受到训练数据的噪声而产生的过拟合的影响)。
- 选择较大的K值,近似误差增大,估计误差减小,模型会变得简单。这里比较极端地想一下,如果K值等于样本量,那么放入一个样本,直接统计样本类别个数,就可以得到该样本的所属类别,就不需要再调整K值,计算距离了,模型会变得很简单。
关于近似误差和估计误差:
- 近似误差关注训练集,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。
- 估计误差关注测试集,对未知数据的预测能力好,但对已知的训练样本将会出现较大偏差的预测。
在实际应用中,K值⼀般取⼀个比较小的数值。通常采用交叉验证法来选取最优的K值(经验规则:K一般低于训练样本数的平方根)。
距离度量
特征空间中两个实例点的距离可以反映出两个实例点之间的相似性程度。K近邻模型的特征空间 一般是N维实数向量空间,使用的距离可以是欧式距离,也可以是其他距离。
分类决策规则
多数表决,即由输入实例例的K个邻近的训练实例中的多数类决定输入实例的类。这样也是为了期望最大化。
KNN算法特点
- 优点:精度高、对异常值不敏感、无数据输入假定
- 缺点:计算复杂度高、空间复杂度高(因为需要计算所有点到该点的距离,即使有KD树会简化运算,但该方法的计算成本也比较高)
