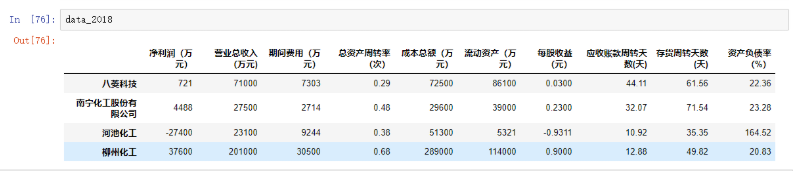
我们选取2018年的广西碳酸钙企业的数据,来判断那间企业在20189年更具有竞争力。我们来做主成分分析和因子分析。
下面是数据来源:
| 企业 | 净利润(万元) | 营业总收入(万元) | 期间费用(万元) | 总资产周转率(次) | 成本总额(万元) | 流动资产(万元) | 每股收益(元) | 应收账款周转天数(天) | 存货周转天数(天) | 资产负债率(%) |
|---|---|---|---|---|---|---|---|---|---|---|
| 八菱科技 | 721 | 71000 | 7303 | 0.29 | 72500 | 86100 | 0.0300 | 44.11 | 61.56 | 22.36 |
| 南宁化工股份有限公司 | 4488 | 27500 | 2714 | 0.48 | 29600 | 39000 | 0.2300 | 32.07 | 71.54 | 23.28 |
| 河池化工 | -27400 | 23100 | 9244 | 0.38 | 51300 | 5321 | -0.9311 | 10.92 | 35.35 | 164.52 |
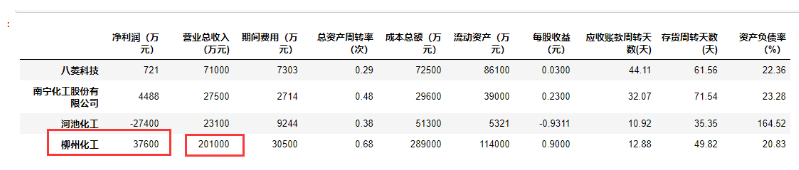
| 柳州化工 | 37600 | 201000 | 30500 | 0.68 | 289000 | 114000 | 0.9000 | 12.88 | 49.82 | 20.83 |
想到主成分分析和因子分析,都会使用SPSS做。但是由于,我的SPPS上个月删掉了,占用1.5g内存,而且没有破解。这次,我用最不怎么熟悉的Stata来做主成分分析和因子分析。
主成分分析
在实际生活工作中,往往会出现所搜集的变量之间存在较强相关关系的情况。如果直接利用数据进行分析,不仅会使模型变得复杂,而且会带来多重线性的问题。主成分分析方法提供了解决这一问题的办法。
我们创建上面数据为2018年碳酸钙企业,通过Stata导入xlsx,注意:必须选择:将第一行作为变量名,不然你无法选择列名,一开始我以为列名不能有中文和括号,结果浪费我好多时间。

主成分在stata中的命令就是 pca ,其实了解sklearn就知道PCA(Principal Component Analysis),就是降维抽取维度。
用Stata真的不需要记住什么命令,明明可以找得到,不会一个help(pca)命令就欧克。


在Results界面中给出了分析结果
. pca 净利润万元 营业总收入万元 期间费用万元 总资产周转率次 成本总额万元 流动资产万元 每股收益
> 元 应收账款周转天数天 存货周转天数天 资产负债率
Principal components/correlation Number of obs = 4
Number of comp. = 3
Trace = 10
Rotation: (unrotated = principal) Rho = 1.0000
# 第一个表格给出了相关系数矩阵的特征值和比例,结果界面和SPSS类似,只是多了一个Difference列
--------------------------------------------------------------------------
Component | Eigenvalue Difference Proportion Cumulative
-------------+------------------------------------------------------------
Comp1 | 6.27881 3.19118 0.6279 0.6279
Comp2 | 3.08763 2.45408 0.3088 0.9366
Comp3 | .633554 .633554 0.0634 1.0000
Comp4 | 0 0 0.0000 1.0000
Comp5 | 0 0 0.0000 1.0000
Comp6 | 0 0 0.0000 1.0000
Comp7 | 0 0 0.0000 1.0000
Comp8 | 0 0 0.0000 1.0000
Comp9 | 0 0 0.0000 1.0000
Comp10 | 0 . 0.0000 1.0000
--------------------------------------------------------------------------
# STATA给出了所有特征值的特征向量,各列的数值平方之和等于1,不信你求Comp1的平方和
# 系数越大,说明主成份对该变量的代表性越大。SPSS比Stata没有 Unexplained 这一列
Principal components (eigenvectors)
----------------------------------------------------------
Variable | Comp1 Comp2 Comp3 | Unexplained
-------------+------------------------------+-------------
净利润万元 | 0.3900 0.1078 -0.1188 | 0
营业总收~元 | 0.3834 -0.1160 0.2365 | 0
期间费用万元 | 0.3417 -0.2835 0.1727 | 0
总资产周~次 | 0.3258 -0.1813 -0.6052 | 0
成本总额万元 | 0.3699 -0.2012 0.1573 | 0
流动资产万元 | 0.3564 0.1525 0.4544 | 0
每股收益元 | 0.3698 0.1969 -0.1850 | 0
应收账款~天 | -0.0694 0.5357 0.3637 | 0
存货周转~天 | 0.0564 0.5384 -0.3662 | 0
资产负债率 | -0.2634 -0.4271 0.0454 | 0
----------------------------------------------------------
SPSS比Stata没有 Unexplained 这一列。我们通过predict pc1 pc2 pc3 score命令就可以查看SPSS的界面如何
. predict pc1 pc2 pc3 score
(score assumed)
(extra variables dropped)
Scoring coefficients
sum of squares(column-loading) = 1
--------------------------------------------
Variable | Comp1 Comp2 Comp3
-------------+------------------------------
净利润万元 | 0.3900 0.1078 -0.1188
营业总收~元 | 0.3834 -0.1160 0.2365
期间费用万元 | 0.3417 -0.2835 0.1727
总资产周~次 | 0.3258 -0.1813 -0.6052
成本总额万元 | 0.3699 -0.2012 0.1573
流动资产万元 | 0.3564 0.1525 0.4544
每股收益元 | 0.3698 0.1969 -0.1850
应收账款~天 | -0.0694 0.5357 0.3637
存货周转~天 | 0.0564 0.5384 -0.3662
资产负债率 | -0.2634 -0.4271 0.0454
--------------------------------------------
下面我们来查看命令corr pc1 pc2 pc3 净利润万元 营业总收入万元 期间费用万元 总资产周转率次 成本总额万元 流动资产万元 每股收益元 应收账款周转天数天 存货周转天数天 资产负债率相关性矩阵

我们如何去除呢?加个comp(2) covariance
- com(#)指定最多只能有#个主成分
- covariance利用协方差矩阵,默认利用相关系数矩阵
命令pca 净利润万元 营业总收入万元 期间费用万元 总资产周转率次 成本总额万元 流动资产万元 每股收益元 应收账款周转天数天 存货周转天数天 资产负债率, comp(2) covariance

我们用命令 screeplot作为碎石图,英语不好的我连eigenvalues什么意思都不知道,查了下原来是特征值

我们在使用命令loadingplot画载荷图,选择出最具有成分的两个成分的作为相关图,我们从相关图就完全看出是什么元素决定成分了。

因子分析
下面我们做因子分析,做前,我先吹下什么是因子分析:
因子分析(factor analysis)是用少数的不可观察的潜变量表示多数可观察的相关的变量 。
就是今天你突然间要上大街要饭,我要找出原因,你为什么今天跑去大街要饭,还用想吗,还不是因为你没钱没房
金钱因子。
在Python中主要使用from sklearn.decomposition import FactorAnalysis和 pip install factor_analyzer。
今天用Stata,点点就ok了 ,敲什么代码,再说了我又不会敲。


命令:factor 净利润万元 营业总收入万元 期间费用万元 总资产周转率次 成本总额万元 流动资产万元 每股收益元 应收账款周转天数天 存货周转天数天 资产负债率

因子1是利润营收决定的,说到底就是钱,因子2就是你的碳酸钙什么时候可以周转出去,最快时间把钱要到手里。如果企业负债了,两个因子就是影响了。负债的企业还有什么竞争力,赶紧关门跑路。
一般昨晚因子,就需要预测,命令很简单predict f1

排名第一的就是净利润,企业就是要赚钱才有竞争力。这不是常识了,分析和没分析差不多,我还是干Spring,Django吧。
看看上面内容,没有代码怎么行?虽然是化工专业,照样敲码两不误。虽说我专业都快挂完了,心痛一秒钟。
下面是百度百科给因子分析模型定义的,我抄了下。
的一种统计方法,是一种降维技术. 做因子分析的前提是自变量 之间有相关关系. 这里的潜变量就是我们所求的因子 ,自变量 是因子 的表征。
因子分析模型是把原观测变量分解成公共因子和特殊因子两部分
其中 是原始变量标准化后的数据, 是公共因子, 是特殊因子。
因子分析的一般步骤
- 将原始数据标准化处理
- 计算相关矩阵
- 计算相关矩阵 的特征值$ r $和特征向量
- 确定公共因子个数
- 构造初始因子载荷矩阵 ,其中 为 的特征向量
- 建立因子模型
- 对初始因子载荷矩阵A进行旋转变换,旋转变换是使初始因子载荷矩阵结构简化,关系明确,使得因子变量更具有可解释性,如果初始因子不相关,可以用方差极大正交旋转,如果初始因子间相关,可以用斜交旋转,进过旋转后得到比较理想的新的因子载荷矩阵 .
- 将因子表示成变量的线性组合 ,其中的系数 可以通过最小二乘法得到.
- 计算因子得分
看看一般步骤,读取数据我就pass了


初始因子和Stata的结果一样

在Stata中我们没有旋转变换,

旋转变换的后的


答案是柳州化工,我听说柳州螺蛳粉,五菱。原来柳州的碳酸钙 ,用来干嘛,建房 遇到盐酸放出 ,是重要的碱性产品。
对了,如果想取出没用因子,只需要在Stata命令参数添加 pcf,

旋转更简单 rotate,搞定,如果报错 ssc install rotate安装下

Python代码如何设置,将确定公共因子个数解释度>=1 改为 >=0.8,这个就去除了没用因子
下面完整代码
import pandas as pd
import numpy as np
datafile = '2018年碳酸钙.xlsx'
data_2018 = pd.read_excel(datafile,index_col=0)
data_2018.head()
data_2018_mat=(data_2018-data_2018.mean())/data_2018.std()# 0均值规范化
data_2018_mat.corr()
import numpy.linalg as nlg #导入nlg函数 矩阵求逆
eig_value,eig_vector=nlg.eig(data_2018_mat.corr()) #计算特征值和特征向量
eig=pd.DataFrame() #利用变量名和特征值建立一个数据框
eig['names']=data_2018.columns#列名
eig['eig_value']= eig_value.real.astype('float64')#特征值 (复数的j都是0) 用real取出
for k in range(1,9): #确定公共因子个数
if eig['eig_value'][:k].sum()/eig['eig_value'].sum()>=0.8: #如果解释度达到80%, 结束循环
print(k)
break
from math import sqrt
col0=list(sqrt(eig_value[0].real)*eig_vector[:,0].real) #因子载荷矩阵第1列
col1=list(sqrt(eig_value[1].real)*eig_vector[:,1].real) #因子载荷矩阵第2列
col0 =[-l for l in col0]
col1 =[-l for l in col1]
A2018=pd.DataFrame([col0,col1]).T #构造因子载荷矩阵A
A2018.columns=['factor1','factor2'] #因子载荷矩阵A的公共因子
A2018.index = data_2018_mat.corr().index
A2018
h2018=np.zeros(10) #变量共同度,反映变量对共同因子的依赖程度,越接近1,说明公共因子解释程度越高,因子分析效果越好
D2018=np.mat(np.eye(10))#特殊因子方差,因子的方差贡献度 ,反映公共因子对变量的贡献,衡量公共因子的相对重要性
A2018=np.mat(A2018) #将因子载荷阵A矩阵化
for i in range(10):
a2018=A2018[i,:]*A2018[i,:].T #A的元的行平方和
h2018[i]=a2018[0,0] #计算变量X共同度,描述全部公共因子F对变量X_i的总方差所做的贡献,及变量X_i方差中能够被全体因子解释的部分
D2018[i,i]=1-a2018[0,0] #因为自变量矩阵已经标准化后的方差为1,即Var(X_i)=第i个共同度h_i + 第i个特殊因子方差
from numpy import eye, asarray, dot, sum, diag #导入eye,asarray,dot,sum,diag 函数
from numpy.linalg import svd #导入奇异值分解函数
def varimax(Phi, gamma = 1.0, q =20, tol = 1e-6): #定义方差最大旋转函数
p,k = Phi.shape #给出矩阵Phi的总行数,总列数
R = eye(k) #给定一个k*k的单位矩阵
d=0
for i in range(q):
d_old = d
Lambda = dot(Phi, R)#矩阵乘法
u,s,vh = svd(dot(Phi.T,asarray(Lambda)**3 - (gamma/p) * dot(Lambda, diag(diag(dot(Lambda.T,Lambda)))))) #奇异值分解svd
R = dot(u,vh)#构造正交矩阵R
d = sum(s)#奇异值求和
if d_old!=0 and d/d_old < 1 + tol: break
return dot(Phi, R)#返回旋转矩阵Phi*R
rotation_mat=varimax(A2018)#调用方差最大旋转函数
rotation_mat=pd.DataFrame(rotation_mat,columns=['factor1','factor2'],index=data_2018_mat.corr().index)#数据框化
rotation_mat
factor_score_2018=(data_2018_mat).dot(rotation_mat) #计算因子得分
factor_score_2018=pd.DataFrame(factor_score_2018)#数据框
factor_score_2018.columns=['利润因子','拿钱速度因子'] #对因子变量进行命名
factor_score_2018.index = data_2018.index
factor_score_2018
在除去没用因子,旋转的变换和Stata完全一样。

这是计算各因子的得分

各因子的计算原理

然而Stata计算总因子得分没有命令,计算公式:因子得分*因子方差的贡献率/累计方差贡献率作为权重。然后计算
方差百分比

八菱科技总因子得分: (0.6131* (-1.637494) + 0.3236 * 2.396507 )/ 0.9367
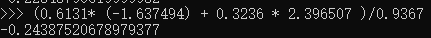
柳州化工总因子得分: (0.6131* (8.935557) + 0.3236 * 0.262321 )/ 0.9367

虽然,数据很少,而且我们我很容易看出柳州化工是行业的大佬,
Stata相对于SPSS,就是没有那个各因子得分,计算总因子得分变得非常困难,因此计算的时候,反而想下载SPSS,但是SPSS免费试用14天已过。又不知道哪里下载盗版的,反而使用Python从原理计算出因子得分。
使用SPSS比Stata更适合主成分分析和因子分析,但是Stata是一款医学研究的软件,提供了大量的统计分析

相对的SPSS的更全,比如生存,时间序列,甚至有时连Python深度模型跑出来的,还不如用Stata点一点,Stata虽然命令多,但是完全不需要记忆,在窗口中完全可以找到,或者一个 help(命令)查看示例。
而SPSS两款工具,SPSS Modeler和SPSS Statistics是SPSS中的“哼哈二将”,一个负责统计分析,一个负责挖掘。

还有不要老是敲代码,有时候工具点几点就ok,excel也是,不要老是跑动不动就pandas读取文件,然后一无所知,比如做个时间序列,keras跑深度学习写几十行代码以为自己很牛,却不知道有的人使用Stata点一点就完成。我们在完成需求的同时,应该寻找最佳的方案,比如一个excel就可以完成的,干嘛要打开jupyter notebook
我们还是干回爬虫,Spring和Djiango吧
