前言
数据探测和稳健估计均可以探测出粗差,但是数据探测仅仅在数据中仅一个观测量含有粗差时好用,如果想要检验多个粗差,需要逐步剔除已检验粗差,再继续检验。而稳健估计在处理包含有多个粗差时有一定优势。
稳健估计
稳健估计分为三大类:M估计,R估计,L估计,M估计最常用,它是一种广义的极大似然估计,有分为选权迭代法和P范数最小法。
M估计的准则
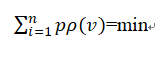
其中ρ为M估计的函数,p为权
M估计的稳健性与ρ的选择有关,当ρ=v**2时,即为最小二乘估计,它并不具有抗差性。
选取不同的ρ函数,会得出不同的M估计,因此M估计不是一个估计,而是一类估计。
选权迭代法
流程:
(1)建立数学模型:V=BX-L
(2)按照最小二乘法求解参数估计值及其残差:X=inv(N)*w,V=BX-L
(3)由V求解观测值的等价权矩阵P_,应用抗差最小二乘(P_代替P)进行迭代计算,直到ΔX<=η,η为迭代停止条件
(4)最后计算出X,V,权函数ρ
几种常用的选权迭代法
Huber,Hampel,丹麦法,IGG,一次范数最小法,P范数最小法,相关等价权法。
其中P范数最小法
ρ函数:
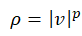
权因子:
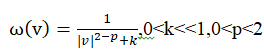
python实现
输入数据
import numpy as np
np.set_printoptions(suppress=True) # 抑制科学记数法
# B,L,P矩阵
B = np.array([0, 1, 0, -1, 1, 0, -1, 0, -1, 1]).reshape(5, 2)
L = np.array([0, -1, 0, 4, 8])
P = np.array([2, 2, 2, 2, 1])
P = np.diag(P)
计算X,V
def cal_canshu(B, P, L):
N = np.dot(B.T, P).dot(B)
W = np.dot(B.T, P).dot(L)
inv_N = np.linalg.inv(N)
X = inv_N.dot(W)
V = B.dot(X) - L
return X, V
# 由初始权阵计算X,V
X, V = cal_canshu(B, P, L)
# print(X,V)
计算第一次的w
# 选权迭代:P范最小法
m = 1.5
k = 0.0002
yita = 0.000001 # 终止循环条件
yita_array = np.array([yita] * 2)
w = [] # 权因子矩阵
for v in V:
w_v = (abs(v) ** (2 - m) + k) ** -1
w.append(w_v)
P_ = P * w # 更新权阵
# print(P_)
计算更新之后X,V
# 计算更新权阵之后的X,V
X_, V_ = cal_canshu(B, P_, L)
选权迭代
delta = abs(X_ - X)
delta[0] = round(delta[0], 7)
delta[1] = round(delta[1], 7) # 保留7位小数
while all(delta >= yita_array): # 这里注意如果要比较矩阵大小,需选择all(所有因子)/any(一个及以上)进行比较
w_v = []
for i in V_:
w_a = (abs(i) ** (2 - m) + k) ** (-1)
w_v.append(w_a)
# print(w_v)
X = X_
P_ = P_ * w_v # 更新权阵
X_, V_ = cal_canshu(B, P_, L)
delta = abs(X_ - X)
delta[0] = round(delta[0], 7)
delta[1] = round(delta[1], 7) # 保留7位小数
查看ρ函数
ρ = []
for i in V_:
ρ.append([abs(i) ** m])
print(ρ, X_)
结果
[[0.9999999999960162], [4.328242386676566e-18], [7.999999908958161], [5.28663897358714e-12], [5.196152501558078]] [-3.99999997 1. ]
从步骤可以看出,该方法关键是确定等价权,权函数是一个在平差过程中随改正数变化的量,经过多次迭代,含有粗差的异常观测的权函数接近0
**权函数不是权阵,异常值的权会变大(L2,L4)
