前言
对深度学习抱有很大的好奇,本来打算直接上手TensorFlow的,鉴于自己还是个小白,还是从简单的keras慢慢坑起,先入个门.通过这次学习,一直使用Pycharm的我发现这种项目适合使用jupyter notebook.jupyter将程序分成多个单元格解释执行,训练一次模型,就可以添加更多单元格程序对结果进行分析.
源码
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
import matplotlib.pyplot as plt
import pandas as pddef plot_image_index(images,labels,prediction,indexs):
"""
:param images: 点阵像素点图像
:param labels: 图像真实值
:param indexs: 索引列表
:return:
"""
fig = plt.gcf() # 实例化图形
fig.set_size_inches(15, 15) # 设定图形大小
i=0
for index in indexs:
i+=1
if i>25:
break
ax = plt.subplot(5, 5, i) # 建立sub_graph子图
ax.imshow(images[index], cmap="binary") # 画出子图
title = str(index)+":label=" + str(labels[index]) # 设置子图title变量用以显示标签字段
if len(prediction) > 0: # 如果传入预测结果
title += ",predict=" + str(prediction[index]) # 设置标题加入预测结果
ax.set_title(title, fontsize=10) # 设置子图标题
ax.set_xticks([]) # 设置不显示刻度
ax.set_yticks([])
plt.show()def images_labels_prediction(images, labels, prediction, index, num=10):
"""
:param images: 点阵像素点图像列表
:param labels: 图像对应真实值
:param prediction: 预测结果
:param index: 数据开始索引
:param num: 显示数据项数
:return:
"""
if num > 25:
num = 25
fig = plt.gcf() # 实例化图形
fig.set_size_inches(15, 15) # 设定图形大小
for i in range(0, num):
ax = plt.subplot(5, 5, 1 + i) # 建立sub_graph子图,为5行5列
ax.imshow(images[index], cmap="binary") # 画出子图
title = "label=" + str(labels[index]) # 设置子图title变量用以显示标签字段
if len(prediction) > 0: # 如果传入预测结果
title += ",predict=" + str(prediction[index]) # 设置标题加入预测结果
ax.set_title(title, fontsize=10) # 设置子图标题
ax.set_xticks([]) # 设置不显示刻度
ax.set_yticks([])
index += 1
plt.show()def show_train_history(train_history, mode="acc"):
"""
:param train_history: 训练历史
:param mode: 可视化模式,acc/loss->准确率或失败率
:return:
"""
plt.plot(train_history.history[mode])
plt.plot(train_history.history["val_" + mode])
plt.title("Train History")
plt.ylabel(mode)
plt.xlabel("Epoch")
plt.legend(["train", "validation"], loc="upper left")
plt.show()def image_reshape_float(image):
"""
:param image:数字图像特征值
:return: 数字图像一维向量标准化后的值
"""
shape = image.shape
return image.reshape(shape[0], shape[1] * shape[2]).astype("float32") / 255def label2_one_hot(label):
"""
:param label:数字集合
:return: 数字进行One-Hot Encoding
"""
return np_utils.to_categorical(label)(train_image, train_label), (test_image, test_label) = mnist.load_data()
# images_labels_prediction(train_image, train_label, [], 0,25)
train_x = image_reshape_float(train_image)
test_x = image_reshape_float(test_image)
train_y = label2_one_hot(train_label)
test_y = label2_one_hot(test_label)model = Sequential()
# 定义相对输出层为256,激活函数为relu,初始权重与偏差使用normal distribution正态分布随机数
model.add(Dense(units=256, activation="relu", kernel_initializer="normal", input_dim=784))
# 定义相对输出层为10,激活函数为softmax,初始权重与偏差使用normal distribution正态分布随机数,输入层自动
model.add(Dense(units=10, activation="softmax", kernel_initializer="normal"))
print(model.summary())# 优化器使用adam可以更快收敛,提高准确率,损失函数使用cross_entropy(交叉熵),评估方式设置为准确率
model.compile("adam", "categorical_crossentropy", ["accuracy"])
# 训练数据x为图像特征值,y为图像真实值;每批次项数为200;训练周期epochs;verbose显示训练过程;验证比例为0.2
train_history = model.fit(x=train_x, y=train_y, batch_size=200, epochs=20, verbose=2, validation_split=0.2)"""
可以在图中看出,训练数据准确度比验证准确度要高,有明显的过度拟合现象
"""
show_train_history(train_history)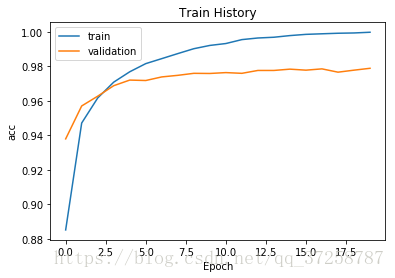
scores = model.evaluate(test_x, test_y)
print("acc:", scores[1])prediction=model.predict_classes(test_x)
images_labels_prediction(test_image, test_label, prediction, 340)# 使用pd.crosstab建立混淆矩阵.args:测试图像真实值;机器预测结果;设置行名与列名
"""
对角线为预测准确项.
可以看出,这次训练5被误判为3的概率比较高
"""
pd.crosstab(test_label,prediction,rownames=["label"],colnames=["predict"])
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| predict | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| label | ||||||||||
| 0 | 971 | 1 | 1 | 0 | 1 | 2 | 2 | 1 | 1 | 0 |
| 1 | 0 | 1124 | 4 | 0 | 0 | 1 | 2 | 1 | 3 | 0 |
| 2 | 4 | 2 | 1011 | 3 | 1 | 0 | 1 | 4 | 6 | 0 |
| 3 | 0 | 0 | 3 | 991 | 0 | 3 | 0 | 5 | 4 | 4 |
| 4 | 1 | 1 | 2 | 1 | 961 | 0 | 4 | 3 | 0 | 9 |
| 5 | 3 | 0 | 0 | 12 | 1 | 863 | 4 | 2 | 4 | 3 |
| 6 | 7 | 3 | 2 | 1 | 4 | 3 | 934 | 0 | 4 | 0 |
| 7 | 0 | 4 | 6 | 4 | 0 | 0 | 0 | 1006 | 2 | 6 |
| 8 | 4 | 1 | 2 | 8 | 3 | 2 | 1 | 2 | 948 | 3 |
| 9 | 2 | 5 | 0 | 4 | 5 | 2 | 1 | 3 | 2 | 985 |
df=pd.DataFrame({"label":test_label,"predict":prediction})
indexs=df[(df.label==5)&(df.predict==3)].index.tolist()
plot_image_index(test_image,test_label,prediction,indexs)
#后续优化def model_exe(model):
print(model.summary())
#编译模型
# 优化器使用adam可以更快收敛,提高准确率,损失函数使用cross_entropy(交叉熵),评估方式设置为准确率
model.compile("adam", "categorical_crossentropy", ["accuracy"])
#模型训练
# 训练数据x为图像特征值,y为图像真实值;每批次项数为200;训练周期epochs;verbose显示训练过程;验证比例为0.2
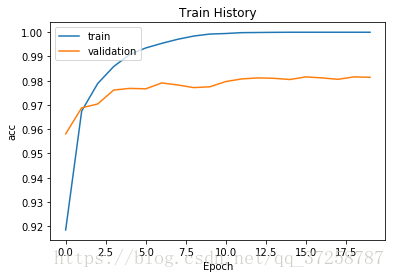
train_history = model.fit(x=train_x, y=train_y, batch_size=200, epochs=20, verbose=2, validation_split=0.2)
"""
可以在图中看出,过度拟合现象显著改善
"""
show_train_history(train_history)
scores = model.evaluate(test_x, test_y)
print("acc:", scores[1])#将隐藏层由256改为1024个model = Sequential()
# 定义相对输出层为1024,激活函数为relu,初始权重与偏差使用normal distribution正态分布随机数
model.add(Dense(units=1024, activation="relu", kernel_initializer="normal", input_dim=784))
# 定义相对输出层为10,激活函数为softmax,初始权重与偏差使用normal distribution正态分布随机数,输入层自动
model.add(Dense(units=10, activation="softmax", kernel_initializer="normal"))
"""
可以在图中看出,过度拟合现象更加明显
"""
model_exe(model)_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_30 (Dense) (None, 1024) 803840
_________________________________________________________________
dense_31 (Dense) (None, 10) 10250
=================================================================
Total params: 814,090
Trainable params: 814,090
Non-trainable params: 0
_________________________________________________________________
None
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
- 6s - loss: 0.2871 - acc: 0.9185 - val_loss: 0.1450 - val_acc: 0.9581
Epoch 2/20
- 5s - loss: 0.1158 - acc: 0.9675 - val_loss: 0.1096 - val_acc: 0.9688
Epoch 3/20
- 5s - loss: 0.0734 - acc: 0.9789 - val_loss: 0.0972 - val_acc: 0.9704
Epoch 4/20
- 5s - loss: 0.0505 - acc: 0.9859 - val_loss: 0.0795 - val_acc: 0.9762
Epoch 5/20
- 5s - loss: 0.0344 - acc: 0.9908 - val_loss: 0.0763 - val_acc: 0.9768
Epoch 6/20
- 5s - loss: 0.0254 - acc: 0.9935 - val_loss: 0.0751 - val_acc: 0.9767
Epoch 7/20
- 5s - loss: 0.0186 - acc: 0.9954 - val_loss: 0.0721 - val_acc: 0.9791
Epoch 8/20
- 5s - loss: 0.0129 - acc: 0.9971 - val_loss: 0.0725 - val_acc: 0.9783
Epoch 9/20
- 5s - loss: 0.0087 - acc: 0.9984 - val_loss: 0.0771 - val_acc: 0.9772
Epoch 10/20
- 5s - loss: 0.0060 - acc: 0.9993 - val_loss: 0.0724 - val_acc: 0.9775
Epoch 11/20
- 5s - loss: 0.0047 - acc: 0.9995 - val_loss: 0.0732 - val_acc: 0.9797
Epoch 12/20
- 5s - loss: 0.0031 - acc: 0.9998 - val_loss: 0.0705 - val_acc: 0.9808
Epoch 13/20
- 5s - loss: 0.0021 - acc: 0.9999 - val_loss: 0.0707 - val_acc: 0.9812
Epoch 14/20
- 5s - loss: 0.0015 - acc: 1.0000 - val_loss: 0.0724 - val_acc: 0.9810
Epoch 15/20
- 5s - loss: 0.0011 - acc: 1.0000 - val_loss: 0.0735 - val_acc: 0.9805
Epoch 16/20
- 5s - loss: 9.7751e-04 - acc: 1.0000 - val_loss: 0.0731 - val_acc: 0.9816
Epoch 17/20
- 5s - loss: 8.6517e-04 - acc: 1.0000 - val_loss: 0.0740 - val_acc: 0.9812
Epoch 18/20
- 5s - loss: 7.1391e-04 - acc: 1.0000 - val_loss: 0.0757 - val_acc: 0.9806
Epoch 19/20
- 5s - loss: 5.5890e-04 - acc: 1.0000 - val_loss: 0.0764 - val_acc: 0.9816
Epoch 20/20
- 5s - loss: 4.4076e-04 - acc: 1.0000 - val_loss: 0.0780 - val_acc: 0.9814
10000/10000 [==============================] - 1s 64us/step
acc: 0.9825
#加入Dropout功能model = Sequential()
# 定义相对输出层为1024,激活函数为relu,初始权重与偏差使用normal distribution正态分布随机数
model.add(Dense(units=1024, activation="relu", kernel_initializer="normal", input_dim=784))
model.add(Dropout(0.5))#加入dropout功能
# 定义相对输出层为10,激活函数为softmax,初始权重与偏差使用normal distribution正态分布随机数,输入层自动
model.add(Dense(units=10, activation="softmax", kernel_initializer="normal"))
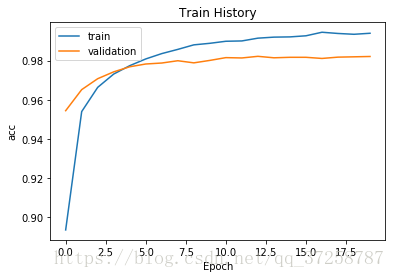
"""
可以在图中看出,过度拟合现象显著改善
"""
model_exe(model)_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_25 (Dense) (None, 1024) 803840
_________________________________________________________________
dropout_4 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_26 (Dense) (None, 10) 10250
=================================================================
Total params: 814,090
Trainable params: 814,090
Non-trainable params: 0
_________________________________________________________________
None
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
- 5s - loss: 0.3560 - acc: 0.8936 - val_loss: 0.1629 - val_acc: 0.9544
Epoch 2/20
- 5s - loss: 0.1591 - acc: 0.9540 - val_loss: 0.1178 - val_acc: 0.9652
Epoch 3/20
- 5s - loss: 0.1150 - acc: 0.9663 - val_loss: 0.0964 - val_acc: 0.9708
Epoch 4/20
- 5s - loss: 0.0894 - acc: 0.9731 - val_loss: 0.0854 - val_acc: 0.9743
Epoch 5/20
- 5s - loss: 0.0729 - acc: 0.9774 - val_loss: 0.0752 - val_acc: 0.9768
Epoch 6/20
- 5s - loss: 0.0628 - acc: 0.9808 - val_loss: 0.0728 - val_acc: 0.9783
Epoch 7/20
- 5s - loss: 0.0537 - acc: 0.9836 - val_loss: 0.0686 - val_acc: 0.9788
Epoch 8/20
- 5s - loss: 0.0477 - acc: 0.9857 - val_loss: 0.0703 - val_acc: 0.9799
Epoch 9/20
- 5s - loss: 0.0398 - acc: 0.9880 - val_loss: 0.0667 - val_acc: 0.9788
Epoch 10/20
- 5s - loss: 0.0366 - acc: 0.9888 - val_loss: 0.0660 - val_acc: 0.9801
Epoch 11/20
- 5s - loss: 0.0327 - acc: 0.9899 - val_loss: 0.0618 - val_acc: 0.9815
Epoch 12/20
- 6s - loss: 0.0307 - acc: 0.9900 - val_loss: 0.0639 - val_acc: 0.9813
Epoch 13/20
- 5s - loss: 0.0284 - acc: 0.9914 - val_loss: 0.0650 - val_acc: 0.9822
Epoch 14/20
- 5s - loss: 0.0249 - acc: 0.9920 - val_loss: 0.0629 - val_acc: 0.9814
Epoch 15/20
- 5s - loss: 0.0239 - acc: 0.9921 - val_loss: 0.0631 - val_acc: 0.9817
Epoch 16/20
- 5s - loss: 0.0229 - acc: 0.9926 - val_loss: 0.0672 - val_acc: 0.9817
Epoch 17/20
- 5s - loss: 0.0177 - acc: 0.9945 - val_loss: 0.0683 - val_acc: 0.9811
Epoch 18/20
- 5s - loss: 0.0189 - acc: 0.9938 - val_loss: 0.0645 - val_acc: 0.9818
Epoch 19/20
- 5s - loss: 0.0194 - acc: 0.9934 - val_loss: 0.0682 - val_acc: 0.9819
Epoch 20/20
- 5s - loss: 0.0187 - acc: 0.9939 - val_loss: 0.0649 - val_acc: 0.9821
10000/10000 [==============================] - 1s 64us/step
acc: 0.9814
#建立两个隐藏层# 模型框架
model = Sequential()
#输入层与隐藏层1
# 定义相对输出层为1024,激活函数为relu,初始权重与偏差使用normal distribution正态分布随机数
model.add(Dense(units=1024, activation="relu", kernel_initializer="normal", input_dim=784))
model.add(Dropout(0.5))#加入dropout功能
#隐藏层2
# 定义相对输出层为1024,激活函数为relu,初始权重与偏差使用normal distribution正态分布随机数
model.add(Dense(units=1024, activation="relu", kernel_initializer="normal"))
model.add(Dropout(0.5))#加入dropout功能
#输出层
# 定义相对输出层为10,激活函数为softmax,初始权重与偏差使用normal distribution正态分布随机数,输入层自动
model.add(Dense(units=10, activation="softmax", kernel_initializer="normal"))
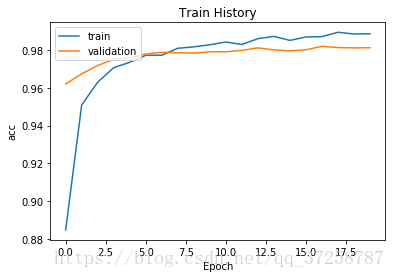
"""
可以在图中看出,过度拟合现象几乎消失,准确度保持稳定
"""
model_exe(model)_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_10 (Dense) (None, 1024) 803840
_________________________________________________________________
dropout_7 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_11 (Dense) (None, 1024) 1049600
_________________________________________________________________
dropout_8 (Dropout) (None, 1024) 0
_________________________________________________________________
dense_12 (Dense) (None, 10) 10250
=================================================================
Total params: 1,863,690
Trainable params: 1,863,690
Non-trainable params: 0
_________________________________________________________________
None
Train on 48000 samples, validate on 12000 samples
Epoch 1/20
- 12s - loss: 0.3644 - acc: 0.8847 - val_loss: 0.1293 - val_acc: 0.9621
Epoch 2/20
- 12s - loss: 0.1595 - acc: 0.9510 - val_loss: 0.1022 - val_acc: 0.9675
Epoch 3/20
- 12s - loss: 0.1200 - acc: 0.9631 - val_loss: 0.0862 - val_acc: 0.9719
Epoch 4/20
- 12s - loss: 0.0964 - acc: 0.9708 - val_loss: 0.0808 - val_acc: 0.9752
Epoch 5/20
- 12s - loss: 0.0836 - acc: 0.9736 - val_loss: 0.0810 - val_acc: 0.9759
Epoch 6/20
- 12s - loss: 0.0732 - acc: 0.9773 - val_loss: 0.0747 - val_acc: 0.9780
Epoch 7/20
- 12s - loss: 0.0688 - acc: 0.9774 - val_loss: 0.0713 - val_acc: 0.9789
Epoch 8/20
- 12s - loss: 0.0579 - acc: 0.9810 - val_loss: 0.0758 - val_acc: 0.9787
Epoch 9/20
- 12s - loss: 0.0552 - acc: 0.9818 - val_loss: 0.0737 - val_acc: 0.9785
Epoch 10/20
- 12s - loss: 0.0524 - acc: 0.9829 - val_loss: 0.0734 - val_acc: 0.9792
Epoch 11/20
- 12s - loss: 0.0491 - acc: 0.9844 - val_loss: 0.0777 - val_acc: 0.9792
Epoch 12/20
- 12s - loss: 0.0502 - acc: 0.9830 - val_loss: 0.0751 - val_acc: 0.9799
Epoch 13/20
- 12s - loss: 0.0427 - acc: 0.9861 - val_loss: 0.0698 - val_acc: 0.9813
Epoch 14/20
- 12s - loss: 0.0386 - acc: 0.9873 - val_loss: 0.0773 - val_acc: 0.9802
Epoch 15/20
- 12s - loss: 0.0437 - acc: 0.9852 - val_loss: 0.0794 - val_acc: 0.9797
Epoch 16/20
- 12s - loss: 0.0379 - acc: 0.9870 - val_loss: 0.0785 - val_acc: 0.9803
Epoch 17/20
- 12s - loss: 0.0386 - acc: 0.9872 - val_loss: 0.0729 - val_acc: 0.9821
Epoch 18/20
- 12s - loss: 0.0337 - acc: 0.9895 - val_loss: 0.0752 - val_acc: 0.9814
Epoch 19/20
- 12s - loss: 0.0344 - acc: 0.9886 - val_loss: 0.0789 - val_acc: 0.9813
Epoch 20/20
- 12s - loss: 0.0348 - acc: 0.9887 - val_loss: 0.0818 - val_acc: 0.9813
10000/10000 [==============================] - 1s 108us/step
acc: 0.9821
#总结:使用多层感知器模型可以通过加宽,加深来提高准确率,加入Dropout层改善过度拟合,准确率能达到0.98