一、分治算法
分治(divide and conquer)的全称为“分而治之”,从名称上看,分治算法主要由两部分构成:
- 分(divide):递归求解所有从原问题分解出来的相似子问题;
- 治(conquer):从子问题的解构建原问题的解。
也就是说,分治算法将原问题划分成若干个规模较小而结构与原问题相同或相似的子问题,然后递归求解所有子问题(如果存在子问题的规模小到可以直接解决,就直接解决它),最后合并所有子问题的解,即可得到原问题的解。
1.1 分治与减治
传统上,在函数正文中至少含有两个递归调用的例程叫做分治算法,而函数正文中只含一个递归调用的例程不是分治算法(可以称为减治算法)。对于函数中只包含一个递归调用的减治算法,在前篇博客:递推与递归中已经做过介绍,插入排序与希尔排序算法就可以称为减治算法。
减治算法一般只包含一个子问题(或者说只选取一部分子问题,而裁剪掉另一部分子问题),递归求解该子问题的解即可得到原问题的解(递推公式的作用)。
分治算法则先将原问题递归分解为多个子问题,再在递归中求解所有子问题的解,最后合并所有子问题的解即可得到原问题的解。需要指出的是,分治算法分解出的子问题应当是相互独立、没有交叉重叠的,如果存在两个子问题有交叉重叠部分,那么不应当使用分治算法解决。可以看出,分治算法是对递归算法的组合应用。
1.2 归并排序
说起分治算法,最先想到的一般是归并排序,“归并”可以理解为递归分解与合并两部分,正好对应分治算法的分与治两个过程。
递归分解数据序列,最常见的就是一分二、二分四、四分八…,直至分解到数据序列只剩下一个元素,不可再分,就到了递归边界。归并排序的递归分解过程也很清晰,递推公式就是前面说的一分二、二分四、四分八…这个过程,实际上就是左边界或右边界减半的过程,递归边界就是数据序列只剩下一个元素的情形,也即左右边界相等的情形。
递归分解过程中,跟前篇介绍希尔排序的递归分组不同的是,希尔排序对于增量序列中的每个增量只分解出一个子问题,而归并排序的递归分解,每次递归都会将原问题分解为两个子问题,所以在函数正文中需要两次递归调用,这也是前面介绍的分治算法与减治算法的区别。
归并排序的递归分解过程,主要是通过左边界或右边界减半实现的,那么参数就需要包含数据序列的首地址,左边界下标和右边界下标,下面给出递归分解过程的实现代码(数据合并部分暂略):
// algorithm\sort.c
void recursive_merge(int *data, int left, int right)
{
if(left >= right)
return;
int mid = left + (right - left) / 2;
recursive_merge(data, left, mid);
recursive_merge(data, mid + 1, right);
merge_data(data, left, mid, right);
}
接下来看被递归分解的数据序列如何合并?递归分解到只剩一个元素时,我们可以认为该数据序列是有序的。每次自顶向下递归调用时,原序列都被递归分解为两个子序列,在到达递归边界后,开始自底向上回归,每次回归都需要将两个有序子序列合并为一个有序子序列。所以,问题就转换为我们如何将两个有序子序列合并为一个有序序列?
两个有序子序列合并为一个有序序列,最简单的就是借助一个空数组,将两个有序子序列的首元素相互比较,较小的元素放入空数组,并将其所在子序列的指针移到下一个元素处,继续刚才的比较过程。直到其中一个子序列的元素比较完毕,将另一个子序列剩余的元素全部放到空数组中。最后,我们将存放在空数组中的有序序列依次放入原序列即可。将该过程举例图示如下:

按照上面的逻辑编写数据合并实现代码如下(两个子序列分别为data[left] – data[mid]与data[mid+1] – data[right]):
// algorithm\sort.c
void merge_data(int *data, int left, int mid, int right)
{
int *temp = malloc((right - left + 1) * sizeof(int));
int i = left, j = mid + 1, k = 0;
while(i <= mid && j <= right)
{
if(data[i] <= data[j])
temp[k++] = data[i++];
else
temp[k++] = data[j++];
}
while(i <= mid)
temp[k++] = data[i++];
while(j <= right)
temp[k++] = data[j++];
for(i = left, k = 0; i <= right; i++, k++)
data[i] = temp[k];
free(temp);
}
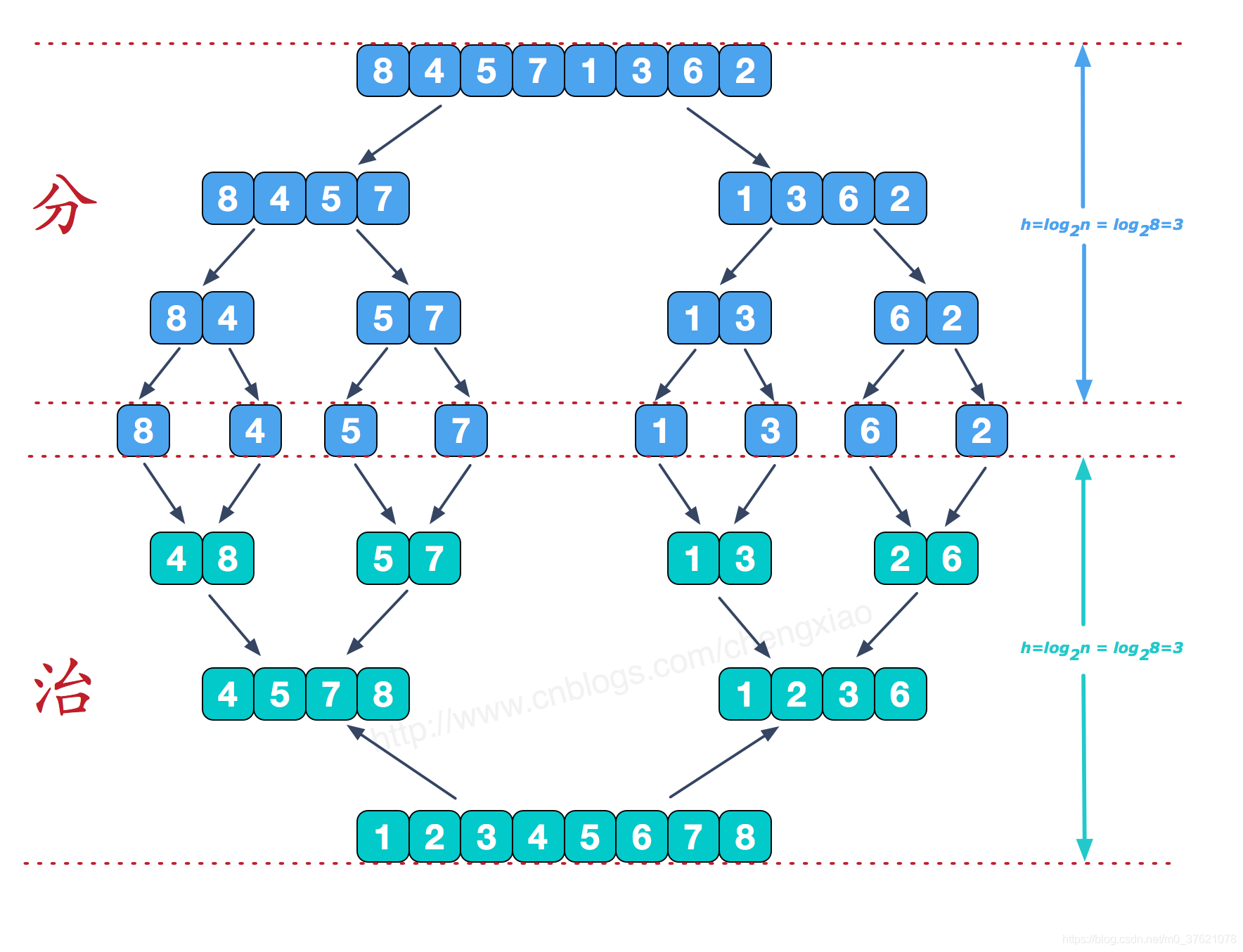
到这里递归分解与子序列合并两个过程都通过函数实现了,我们用一张图来说明归并排序的两个过程:
上面的函数还有点改进空间,内存的分配释放比较占用时间,上面子序列合并的实现函数merge_data中进行了空数组的分配与释放,该函数被多次调用就会降低归并排序的效率。我们可以先为其分配一个与原序列相同大小的空数组,在子序列合并函数merge_data中就可以省去内存的分配与释放操作过程,但需要增加一个参数用于传入临时数组的指针。优化后的归并排序实现代码如下:
// algorithm\sort.c
void merge_data(int *data, int *temp, int left, int mid, int right)
{
int i = left, j = mid + 1, k = 0;
while(i <= mid && j <= right)
{
if(data[i] <= data[j])
temp[k++] = data[i++];
else
temp[k++] = data[j++];
}
while(i <= mid)
temp[k++] = data[i++];
while(j <= right)
temp[k++] = data[j++];
for(i = left, k = 0; i <= right; i++, k++)
data[i] = temp[k];
}
void recursive_merge(int *data, int *temp, int left, int right)
{
if(left >= right)
return;
int mid = left + (right - left) / 2;
recursive_merge(data, temp, left, mid);
recursive_merge(data, temp, mid + 1, right);
merge_data(data, temp, left, mid, right);
}
为了方便调用,我们可以再对recursive_merge进行一层封装,只需要传入数据序列首地址及元素个数两个参数即可,封装函数实现代码如下:
// algorithm\sort.c
void merge_sort(int *data, int n)
{
int *temp = malloc(n * sizeof(int));
recursive_merge(data, temp, 0, n - 1);
free(temp);
}
从归并排序的实现过程看,递归分解过程N分N/2、再分N/4、…最后分到1,一共分割了log2N次(由2x = N得x = log2N);子序列合并过程比较排序加上数据拷贝,大概需要耗费2N时间,两者相乘得归并排序的时间复杂度为O(N * logN)(省略常数)。很显然,归并排序的时间复杂度比插入排序与希尔排序的时间复杂度更低,也即效率更高。
从归并排序算法的实现过程,可以更深的了解分治算法的原理与应用,下面再介绍一种更常用的分治算法 — 快速排序算法。
二、快速排序
快速排序也是一种分治算法,自然也可以分为自顶向下的递归分解与自底向上的子问题合并两部分。与归并排序不同的是,归并排序是在数据合并过程中由我们完成有序子序列的合并,快速排序则是在序列分解过程中由我们完成子序列分组。
在介绍希尔排序时,我们举了两万名学生先分班级,在各班级内先排出名次,再在不同班级相应名次间互相比较,比两万名学生放一块儿进行两两比较,效率高得多。这个例子同样适用于归并排序,先分解为有序子序列,再将多个有序子序列合并为一个有序序列,能大幅减少数据间的比较与交换次数,因此可以获得超越插入排序的执行效率。
快速排序与归并排序不同的是,快速排序按分数线分班,比如A班的所有学生能力都高于分数线level,B班的所有学生能力都低于分数线level,待A班与B班内的学生排序后,两班组合就是所有学生的排序,两班之间的学生不用再相互比较,这就能让计算机做更少的事儿,在某些情况下比归并排序获得更高的执行效率,这也是快速排序比归并排序更常用的原因。
从上面的分析可以看出,快速排序的关键是如何选择分界线并把数据按分界线分为小于分界线的子序列和大于分界线的子序列?理想情况下是取数据序列的中位数,能够通过分界线把数据序列分为元素个数相等的两个子序列,这种情况相比归并排序省去了额外数组的空间开销与数据拷贝的时间开销,应该能获得比归并排序更高的效率。糟糕情况下,分界线并没有把数据序列分隔开,此时退化为类似插入排序这种未分组的基础排序算法,效率甚至不如插入排序。快速排序分界线的选择,跟希尔排序增量序列的选择类似,都会对排序算法的运行效率或者时间复杂度产生很大的影响。
快速排序选择分界线比较常用的有以下三种方式:
- 选一个固定位置,比如a[left]:这种方法是最不可取的,原因非常简单,假设数组已经接近有序,那么选取a[left]作为分界线就很容易导致分治变得“无效”,因为a[left]很可能就是最小的元素;
- 随机选择一个位置,比如a[left + rand()%(right-left+1)]:这种方法可取,随机选择的位置虽然不是很好,但也不至于太糟,计算随机数耗费的时间稍微多一些;
- 三数取中法,比如选择a[left]、a[(left+right)/2]、a[right]大小排中间的那个:这种方法一般相比前两种更好,选择的分界线更接近中位数,而且省去了计算随机数的开销。
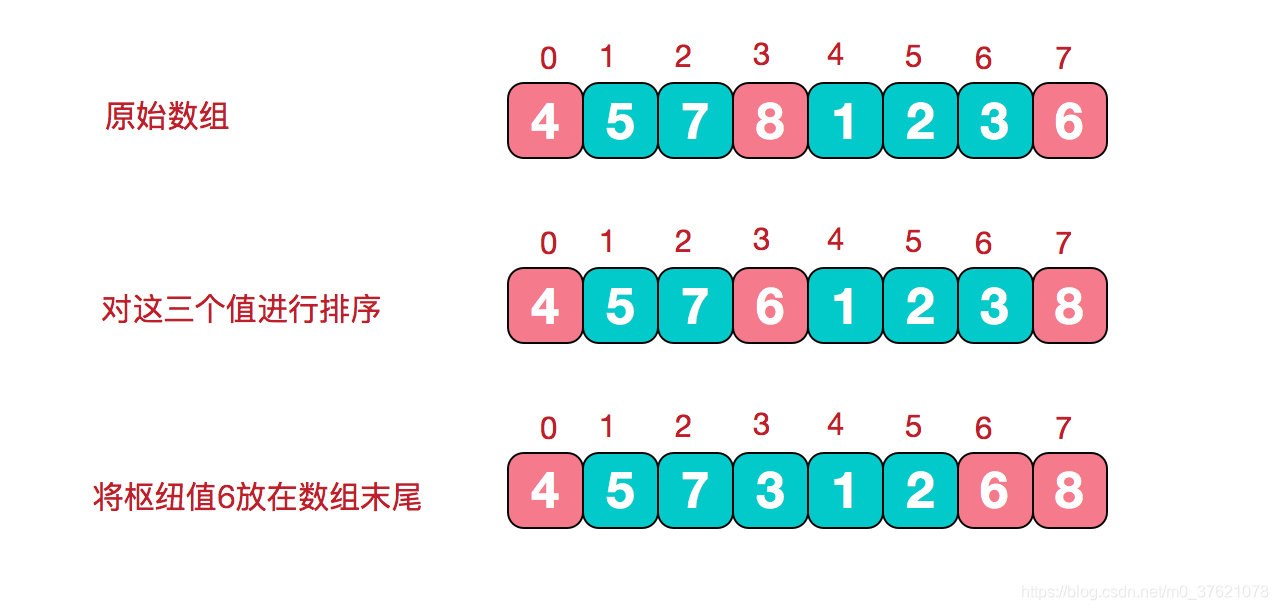
我们使用更优的三数取中法来选择分界线,要从三个元素中选出值处于中间的元素,最简单的方法是先将这三个元素排序,而且排序工作本身就能减少原数据序列的逆序数。三个元素排序后,选择中间元素作为分界线,为了方便后续分组,我们需要先把中间元素移到边上(比如倒数第二个元素,因排序后中间元素肯定不大于末尾元素),待原数据序列按分界线分为小于分界线与不小于分界线两组,再把中间元素移回到应该在的位置,便完成了元素分组,且以中间元素为分界线。该过程图示如下:
选择好分界线后,就要以枢纽值为分界,将数据序列分为小于枢纽值和不小于枢纽值两组,怎么划分呢?首先想到的是每个元素逐个与枢纽值相比较,小的放左边、大于等于的放右边,这种方法虽然简单,但效率有点低且需占用额外的空间。有没有更高效的序列划分方法呢?
回想下希尔排序比插入排序效率高的原因,序列元素执行远距离交换比执行相邻交换更高效(也即远距离元素交换一次能减少超过一个逆序数,相邻元素交换一次只能减少一个逆序数),我们利用这个技巧,可以很容易想到,使用两个游标(或理解为哨兵)分别从序列两端向中间进发,左边的游标停在第一个大于等于分界线的元素处,右边的游标停在第一个小于分界线的元素处,如果左右两个游标没有相遇,则交换两个游标指向的元素,直到两个游标相遇,便完成了元素分组。最后再把枢纽值放到左右游标相遇处,便完成了以枢纽值为分界线,左边的元素全部小于枢纽值,右边的元素全部大于等于枢纽值。该过程图示如下:

按照上面的逻辑编写选择枢纽值,并以枢纽值作为分界线将数据序列划分为左右两组的函数实现代码如下:
// algorithm\sort.c
int partition(int *data, int left, int right)
{
int mid = left + (right - left) / 2;
if(data[left] > data[mid])
swap_data(&data[left], &data[mid]);
if(data[left] > data[right])
swap_data(&data[left], &data[right]);
if(data[mid] > data[right])
swap_data(&data[mid], &data[right]);
swap_data(&data[mid], &data[right-1]);
int i = left + 1, j = right - 2, pivot = right - 1;
while (true)
{
while (data[i] < data[pivot])
i++;
while (j > left && data[j] >= data[pivot])
j--;
if(i < j)
swap_data(&data[i], &data[j]);
else
break;
}
if(i < right)
swap_data(&data[i], &data[pivot]);
return i;
}
void swap_data(int *a, int *b)
{
if(*a != *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
}
上面的函数实现代码中需要提醒的是,左右两个游标i和j要注意不能访问越界,i初值为left+1,条件data[i] < data[pivot]保证了i的值不会大于right-1;j初值为right-2,条件data[j] > data[pivot]可以保证j的值不会小于left(因为data[left] <=data[pivot] ),但我们不能把data[j] > data[pivot]作为判断条件,假如左右游标指向的元素都等于枢纽值且左右游标未相遇,就会导致左右游标不能前进而陷入死循环。解决方案之一是把条件判断式改为data[j] >= data[pivot],就可以解决该问题,但就不能保证游标访问不越界了(假如data[left] ==data[pivot]),需要再加上游标边界j > left。
实现了数据序列按分界线分割处理后,接下来就可以交给递归完成序列的后续处理了。递推公式类似于归并排序,将序列左右边界分割,跟归并排序的二等分不同的是,我们需要按照分界线划分,分界线的游标就是前面分割函数partition()的返回值i,以i为分界线将数据序列分割为左右两个子序列,这就是快速排序的递推公式。递归边界跟归并排序只剩一个元素的做法也略有不同,不管是三数取中还是按中位数分组,一般至少包含三个元素,我们就以少于三个元素的情形作为递归边界,假如剩下两个元素逆序则对其交换,否则直接返回即可。按照这个逻辑编写快速排序函数的实现代码如下:
// algorithm\sort.c
void quick_sort(int *data, int left, int right)
{
if(right - left <= 1)
{
if(right - left == 1 && data[left] > data[right])
swap_data(&data[left], &data[right]);
return;
}
int divide = partition(data, left, right);
quick_sort(data, left, divide - 1);
quick_sort(data, divide + 1, right);
}
可以看出,快速排序也有尾调用的特点,可以省去自底向上的回归过程,这也是快速排序比归并排序在工程中更常用、平均效率更高的原因之一。
快速排序的时间复杂度跟分界线或枢纽值的选择有很大关系,前面分析过了,最坏情况下分界线或枢纽值总是选成了该数据序列的最大值或最小值,此时快速排序蜕化成了选择排序,需要分割N-1次,所以最坏情况时间复杂度为O(N2);最好情况下分界线或枢纽值总是选成了该数据序列的中位数,每次都分为大小相等的两个子序列,需要分割logN次,所以最好情况时间复杂度为O(N * logN)。
快速排序平均情况下,分界线或枢纽值不会总选到该数据序列的中位数,但被分隔开的两个子序列,左边元素更多与右边元素更多的概率基本相等,多次分割平均起来可以接近最好情况,即平均情况时间复杂度也是O(N * logN)。虽然跟归并排序的平均时间复杂度相同,因为节省了额外的空间开销和数组元素复制开销,且省去了回归过程,在数据量较大时,快速排序平均比归并排序快两到三倍,因此快速排序比归并排序更常用。
在数据量较小或接近有序时,快速排序的效率还是比不上插入排序,因此在工程中,常把快速排序与插入排序的优点结合起来,避免快速排序陷入比较坏的情形,比如可以对快速排序再次进行如下封装:
// algorithm\sort.c
void quicksort(int *data, int n)
{
if(n < 15)
insert_sort(data, n, 1, 1);
else
quick_sort(data, 0, n - 1);
}
void insert_sort(int *data, int n, int k, int step)
{
if(k >= n)
return;
int i = k - step, temp = data[k];
while (i >= 0 && data[i] > temp)
{
data[i + step] = data[i];
i -= step;
}
data[i + step] = temp;
insert_sort(data, n, k + step, step);
}
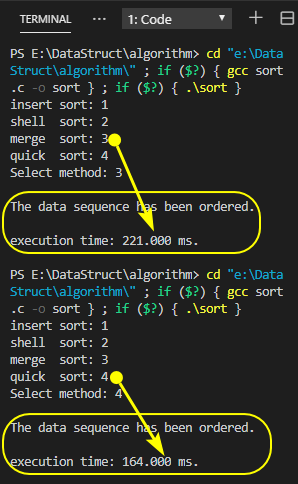
以一百万随机数序列排序为例,对比归并排序与快速排序的运行时间如下图示:
2.1 C标准库函数qsort
C语言标准库为排序算法只提供了一个接口函数,该排序函数在数据规模比较大时便是以快速排序算法实现的,由此可见快速排序的重要性。下面给出该接口函数的声明:
// <stdlib.h>
/* quick sort function api
*
* ptr: A pointer to an array to be sorted
* count: The number of elements in an array
* size: The byte size of each element of the array
* comp: Compare functions.
If the first parameter is less than the second, a negative integer value is returned;
if the first parameter is greater than the second, a positive integer value is returned;
if the two parameters are equal, zero is returned.
The signature of the comparison function should be equivalent to the following:
int CMP (const void *a, const void *b);
The function must not modify the objects passed to it, and must return consistent results
when comparing the same objects, regardless of their position in the array.
* return: Zero on success and non-zero if a run-time constraint violation is detected
*/
void qsort( void *ptr, size_t count, size_t size,
int (*comp)(const void *, const void *) );
C语言排序函数qsort的使用示例如下:
// algorithm\sort.c
#include <stdlib.h>
int compfunc(const void *a, const void *b)
{
const int arg1 = *(const int *)a;
const int arg2 = *(const int *)b;
if(arg1 < arg2)
return -1;
if(arg1 > arg2)
return 1;
return 0;
}
int main(void)
{
data = data_init(data, MAX_COUNT);
qsort(data, MAX_COUNT, sizeof(int), compfunc);
validate_data(data, MAX_COUNT);
free(data);
return 0;
}
三、二分查找
我们之所以对序列元素进行排序,其中一个重要原因是为了方便日后的查找,如果序列是无序的,查找某个元素是否存在就需要遍历整个序列,也即时间复杂度为O(N)。假如序列已经排好了顺序,从中间随机选择一个元素与我们要查找的目标元素值相比较,根据比较结果我们就可以知道应该向前查找还是向后查找,我们查阅字典就是使用类似的逻辑。
从归并算法可以了解,每次从序列中选择一个元素将序列分为左右两部分,如果每次将序列二等分,将原序列分割为只剩一个元素的序列需要的分割次数最少。二分查找算法也是使用类似的逻辑,每次选择序列中间的元素跟要查找的目标元素比较,假如原序列按非降序排列,中间元素值小于要查找的目标元素值,则从后一半序列中再去中间元素去比较,直到中间元素值与目标元素值相等,或者序列分割到尽头仍不相等,则返回结果。
二分查找虽然也是将原问题不断分解为小问题,但每次只选择其中一个小问题求解,也即原问题的解等价于被分解的其中一个小问题的解,不涉及所有子问题解的合并,所以算是减治算法。按照这个逻辑编写二分查找的实现代码如下:
// algorithm\search.c
int binary_search(int *data, int left, int right, int target)
{
if(left > right || target < data[left] || target > data[right])
return -1;
int mid = left + (right - left) / 2;
if(target < data[mid])
return binary_search(data, left, mid - 1, target);
else if(target > data[mid])
return binary_search(data, mid + 1, right, target);
else
return mid;
}
上面的函数查找序列中是否存在元素target,若不存在则返回-1,若存在则返回与元素target相等的元素下标(即在序列中的位置)。
假如序列中有重复的元素,也即等于要查找的目标元素值target的元素不止一个,上面的函数就返回第一个等于target的元素下标,该下标可能既不是序列中第一个等于target的元素下标,也不是最后一个等于target的元素下标。如果我们想返回序列中第一个等于target的元素下标该怎么办呢?
二分查找要返回第一个符合条件的元素下标,就不能在查找到符合条件的元素后直接返回了,而需要继续向前查找,直到分割到子序列的尽头为止。原先data[mid]等于目标值直接返回的分支就需要与大于目标值的分支合并(假如data[mid]等于目标值,则第一个符合条件的元素必然在[left, mid]区间内);增加递归边界即序列左右边界相等时,根据与目标值的比较结果返回。按照这个逻辑,修改二分查找的实现代码如下:
// algorithm\search.c
int binary_search(int *data, int left, int right, int target)
{
if(left > right || target < data[left] || target > data[right])
return -1;
if(left == right)
{
if(target == data[left])
return left;
else
return -1;
}
int mid = left + (right - left) / 2;
if(target <= data[mid])
return binary_search(data, left, mid, target);
else if(target > data[mid])
return binary_search(data, mid + 1, right, target);
}
上面的二分查找函数不仅可以判断序列中是否存在等于目标值的元素(不存在则返回-1),当遇到序列中多个元素均等于目标值时,可以返回序列中第一个等于目标值的元素下标。假如要返回序列中最后一个等于目标值的元素下标,只需要把原先data[mid]等于目标值直接返回的分支合并到小于目标值的分支(假如data[mid]等于目标值,则最后一个符合条件的元素必然在[mid, right]区间内)。
前面介绍的二分查找依赖的是顺序表结构,需要借助数组O(1)的随机访问效率才能实现,那么能否依赖链式表结构实现呢?不管是单向链表还是双向链表,随机访问的时间复杂度都是O(n),都无法实现O(logn)的二分查找效率。
还记得前面介绍的跳跃链表吗?通过构建多级索引层,也是可以实现O(logn)时间的二分查找的,只不过需要额外占用O(n)的内存空间,这是一个典型的以空间换时间的技巧。
跳表比数组实现的二分查找有什么优势呢?再回顾下顺序表与链式表的优缺点对比,很容易想到,跳表并不需要连续的内存地址空间,而且支持O(1)时间插入、删除一个数据,是一种高效的动态数据结构;数组则需要连续的内存地址空间,插入、删除一个数据需要O(n)时间,并不适合数据的动态更新,算是一种高效的静态数据结构。
3.1 查找第K大的元素值
二分查找借鉴归并排序的等分技巧可以快速完成在有序数据序列中查找某个目标元素的任务。很多时候,对大规模数据排序的成本比较高,如果只想知道数据的大概分布,比如该组数据的中位数是多少?前20%元素与后80%元素的分界线是多少?有没有可以不用排序就能达成任务的算法呢?
再回顾下快速排序的划分技巧,partition()正好可以实现将一组数据分割为两部分,并返回分界线的功能,我们可以借助快速排序的partition()函数,再结合二分查找的技巧,直接获得无序数据序列的第K个大的元素值。按照上述逻辑,在一个无序数据序列中查找第K大的元素值的实现代码如下:
// algorithm\search.c
int searth_Kth(int *data, int left, int right, int k)
{
if(right - left <= 1)
{
if(right - left == 1 && data[left] > data[right])
swap_data(&data[left], &data[right]);
if(left == k - 1)
return data[left];
else if(right == k - 1)
return data[right];
else
return -1;
}
int divide = partition(data, left, right);
if(divide > k - 1)
return searth_Kth(data, left, divide - 1, k);
else if(divide < k - 1)
return searth_Kth(data, divide + 1, right, k);
else
return data[k - 1];
}
由于前面快速排序是按照三数取中法进行的,对数据序列划分到只剩下两个元素时,需要在查找函数中特别处理。如果函数partition()中选择枢纽值使用了随机选择法,就可以在序列划分函数中处理只有一个元素的情况,可以省去在查找函数中的特别处理。
3.2 C标准库函数bsearch
C语言标准库也为二分查找提供了一个函数接口,该函数接口的声明如下:
// <stdlib.h>
/* binary search function api
*
* key: A pointer to the element to be searched
* ptr: A pointer to the array to verify
* count: The number of elements in an array
* size: The byte size of each element of the array
* comp: Compare functions.
If the first parameter is less than the second, a negative integer value is returned;
if the first parameter is greater than the second, a positive integer value is returned;
if the two parameters are equal, zero is returned.
The signature of the comparison function should be equivalent to the following:
int CMP (const void *a, const void *b);
The function must not modify the objects passed to it, and must return consistent results
when comparing the same objects, regardless of their position in the array.
* return: Points to a pointer that is equivalent to the *key,
and returns a null pointer when an element is not found.
*/
void* bsearch( const void *key, const void *ptr, size_t count, size_t size,
int (*comp)(const void*, const void*) );
需要指出的是,C标准库提供的函数bsearch只是返回查找到的元素指针,如果想获得元素下标,只需要将该指针所指地址减去序列首地址即可。
由于bsearch提供了供我们自定义的比较函数comp,我们还可以使用结构体作为序列元素,以结构体中的某一成员作为排序依据和查找目标,待查找到并返回与*key比较相等的指针后,就可以获得该元素的其它成员值。举例如下:
// algorithm\search.c
#include <stdlib.h>
#include <stdio.h>
struct data {
int nr;
char *value;
} dat[] = {
{1, "Foo"}, {2, "Bar"}, {3, "Hello"}, {4, "World"}
};
int data_cmp(const void *lhs, const void *rhs)
{
const struct data *const l = (const struct data *)lhs;
const struct data *const r = (const struct data *)rhs;
if (l->nr < r->nr)
return -1;
else if (l->nr > r->nr)
return 1;
else
return 0;
}
int main(void)
{
struct data key = { .nr = 3 };
struct data const *res = bsearch(&key, dat, sizeof(dat) / sizeof(dat[0]),
sizeof(dat[0]), data_cmp);
if(res)
printf("\nNo %d: %s\n", res->nr, res->value);
else
printf("\nNo %d not found\n", key.nr);
return 0;
}
上述自定义比较函数,用来进行结构体排序的方法,也可以用在前面介绍的qsort函数中,来实现结构体按某成员排序的目的(也可以在主排序成员相等时,再选择第二成员作为辅助排序依据)。
上面代码中const修饰符主要用于保护被修饰的变量,防止其被意外修改,也即被const修饰的变量就变成了只读变量。假如被const修饰的变量包含取值运算符*,需要区分const保护的是指针指向的值还是指针变量本身。如果const在取值运算符左侧则修饰的是指针指向的值,如果const在取值运算符右侧则修饰的是指针变量本身,如果想要同时保护指针指向的值和指针变量本身,则需要在取值运算符两侧都使用const修饰。
本章算法实现源码下载地址:https://github.com/StreamAI/ADT-and-Algorithm-in-C/tree/master/algorithm
