这两天事情比较少,这里再分享一个简单好用的ZSL算法
Semantic Autoencoder for Zero Shot Learning
之前也写过几篇博客简单描述了几种基本的ZSL算法
DeepLearning | Relational Knowledge Transfer for Zero Shot Learning(论文、算法、数据集、代码)
DeepLearning | Zero Shot Learning 零样本学习(扩展内容、模型、数据集)
DeepLearning | Zero Shot Learning 零样本学习
这篇博客会描述SAE方法的思想和理论解释,在文章的最后会给出算法复现的python代码
一、 Introduction
我们先明确一下符号标记 表示数据, 表示数据的属性标签, 表示数据的标签。
在之前的几篇博客中,我们反复提到了直接属性预测(DAP)这一经典的ZSL方法,今天我们还是用它来引出SAE。DAP先用 训练多个学习器预测 ,在测试阶段,用训练好的学习器预测测试样本,再对着属性表进行近邻搜索确定标签 。
DAP存在着一些缺点,如没有办法克服域偏移的问题,训练很多学习器也是一件费时的事。
那么我们为什么不直接预测所有的属性呢?这是因为如果直接用1个网络同时预测所有的属性,会造成该网络学习得到已知类别属性的固有模式,而不具体的细分属性,这样一来,使用属性嵌入的意义就不大了,还是没有办法预测未知类别。
Semantic autoencoder(SAE)则为我们提供了另一种思路,它在普通的自编码网络上加上了一个约束,这个约束使得编码后得到的属性包含了更多数据样本本身的特点,从而使得模型可以识别未知类别
二、Approach
我们先来看一下普通的自编码器模型
这一模型很好理解,即 经过两次映射 和 后输出 本身,即通过一次映射 编码,第二次映射 解码
我们再来看一下SAE的自编码模型
相比于普通的自编码器,SAE做出了两点变化,一是要求 = ,这是为了方便后面的优化求解,二是增加了线性约束,即
该模型可以图解如下:
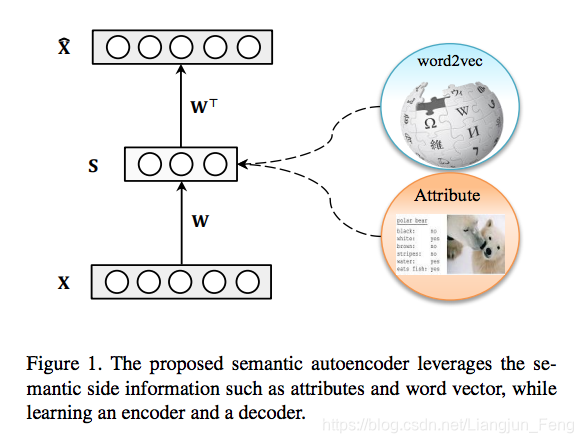
仔细研究该模型,可以发现,SAE其实要求所求得的
具有两重性质
- 在经过 映射之后可以通过 还原,即 还包含 的所有信息
- 应当尽可能的逼近
这两条性质,使得映射后得到的
具有较好的类别区分性质,这是普通的自编码器做不到的。
该模型的求解也十分简单,通过拉格朗日乘子法,并求导可以但模型转化为Sylvester等式的形式
其中 , ,
该等式可以通过python 库里的Sylvester求解器直接求解, 要注意,SAE最后用于判断属性和类别远近的距离是cos距离而不是欧式距离,这会很大程度上影响模型精度
三、算法复现
AwA2的数据链接在这里:DeepLearning | AWA2 图像数据集预处理
AwA和其他数据链接在这里:https://blog.csdn.net/qq_38451119/article/details/81624468
python源代码在这里:https://github.com/LiangjunFeng/Implement-of-ZSL-algorithms
