参考:https://www.cnblogs.com/bigsai/p/14080846.html
一、分治算法介绍
分治算法是用了分治思想的一种算法,什么是分治?
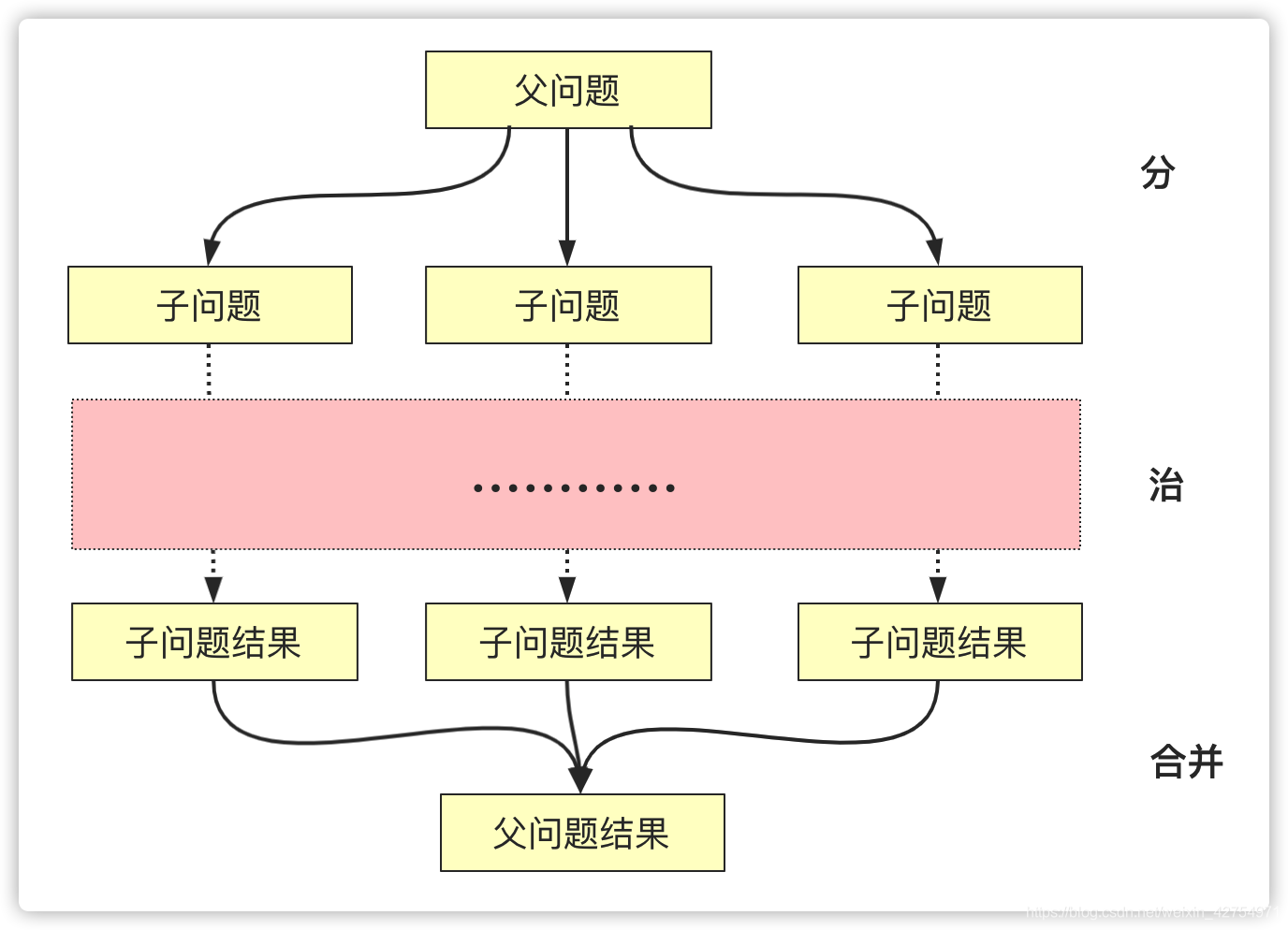
分治,字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并
将父问题分解为子问题同等方式求解,这和递归的概念很吻合,所以在分治算法通常以递归的方式实现(当然也有非递归的实现方式)。分治算法的描述从字面上也很容易理解,分、治其实还有个合并的过程:
- 分(Divide):递归解决较小的问题(到终止层或者可以解决的时候停下)
- 治(Conquer):递归求解,如果问题够小直接求解。
- 合并(Combine):将子问题的解构建父类问题
一般分治算法在正文中分解为两个即以上的递归调用,并且子类问题一般是不相交的(互不影响)。当求解一个问题规模很大很难直接求解,但是规模较小的时候问题很容易求解并且这个问题并且问题满足分治算法的适用条件,那么就可以使用分治算法。
二、采用分治算法解决的问题需要满足那些条件(特征)
- 1 . 原问题规模通常比较大,不易直接解决,但问题缩小到一定程度就能较容易的解决。
- 2 . 问题可以分解为若干规模较小、求解方式相同(似)的子问题。且子问题之间求解是独立的互不影响。
- 3 . 合并问题分解的子问题可以得到问题的解。
你可能会疑惑分治算法和递归有什么关系?其实分治重要的是一种思想,注重的是问题分、治、合并的过程。而递归是一种方式(工具),这种方式通过方法自己调用自己形成一个来回的过程,而分治可能就是利用了多次这样的来回过程。
三、LeetCode实例
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
int i=1;
if(l1==NULL){
return l2;
}
if(l2==NULL){
return l1; //第五层进行返回 l1=4
}
struct ListNode *l3=NULL;
if(l1->val<l2->val){
l3=l1; //第二层:l3=1->2>4 //第三层l3=2->4
//从第四层回到第三层 l3=2->3->4->4
//再从第二层回到第二层l3=1->2->3->4->4
l3->next=mergeTwoLists(l1->next, l2);//第二层 l1=2->4 第三层 l1=4
}
else{
l3=l2;//l3指向l2 //第一层l3= 1->3->4(1开始) 第四层l3=3->4 第五层l3=4
l3->next=mergeTwoLists(l1,l2->next); //第一层:l2= 3->4 第四层l2=4 第五层l2=null;
//从第五层开始返回l3->next=4 第五层l3=4->4
//再回到第四层的l3->next=3->4->4
}
return l3;
}
采用C的递归思想进行解决,看注释,一层一层递归即可