1.前言
本文讲讨论tensorflow2.0中的自定义指标问题。官网地址:here
2. 背景
可以通过将 tf.keras.metrics.Metric 类子类化来轻松创建自定义指标。您将需要实现 4 个方法:
__init__(self),您将在其中为指标创建状态变量。update_state(self, y_true, y_pred, sample_weight=None),使用目标y_true和模型预测y_pred更新状态变量。result(self),使用状态变量来计算最终结果。reset_states(self),用于重新初始化指标的状态。
2.1 案例
这里还是以鸢尾花分类为例,结合逛网的文档,给出小修案例:
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import load_iris
x_data = load_iris().data # 特征,【花萼长度,花萼宽度,花瓣长度,花瓣宽度】
y_data = load_iris().target # 分类
class CategoricalTruePositives(tf.keras.metrics.Metric):
def __init__(self, name="categorical_true_positives", **kwargs):
super(CategoricalTruePositives, self).__init__(name=name, **kwargs)
self.true_positives = self.add_weight(name="ctp", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
y_pred = tf.reshape(tf.argmax(y_pred, axis=1), shape=(-1, 1))
print(y_pred)
print(y_true)
values = tf.cast(y_true, "int32") == tf.cast(y_pred, "int32")
values = tf.cast(values, "float32")
if sample_weight is not None:
sample_weight = tf.cast(sample_weight, "float32")
values = tf.multiply(values, sample_weight)
self.true_positives.assign_add(tf.reduce_sum(values)) # 自加操作,还有个assign_sub
def result(self):
return self.true_positives / 100
def reset_states(self):
# The state of the metric will be reset at the start of each epoch.
self.true_positives.assign(0.0)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(4, input_shape=(4,), activation='relu'))
model.add(tf.keras.layers.Dense(3, input_shape=(4,), activation='softmax'))
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=[CategoricalTruePositives(), 'mse'],
)
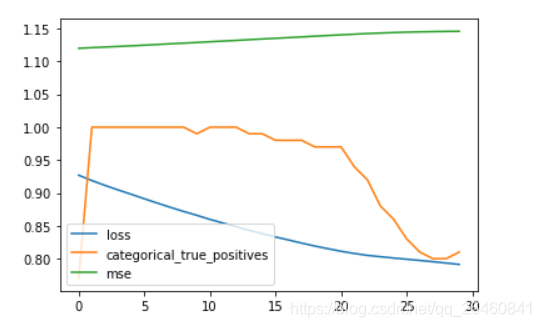
history = model.fit(x_data, y_data, batch_size=64, epochs=30)
for key in history.history.keys():
plt.plot(history.epoch, history.history[key])
plt.legend(history.history.keys())