基于云实验平台的Linux&Hadoop常用操作
目录
Hadoop运行在Linux系统上,实践一些常用的Linux命令。熟悉常用的Linux操作和Hadoop操作。
一、腾讯云服务器
腾讯云(Tencent Cloud),又称腾讯云计算,是腾讯推出的云端运算服务,发布全球云服务版图,构建覆盖全球的数据中心节点,腾讯云为客户提供云服务器、云存储、云数据库和弹性web引擎等基础云服务。
进入腾讯云官网界面(任意浏览器搜索即可)
菜单→产业人才培养中心→动手实验室
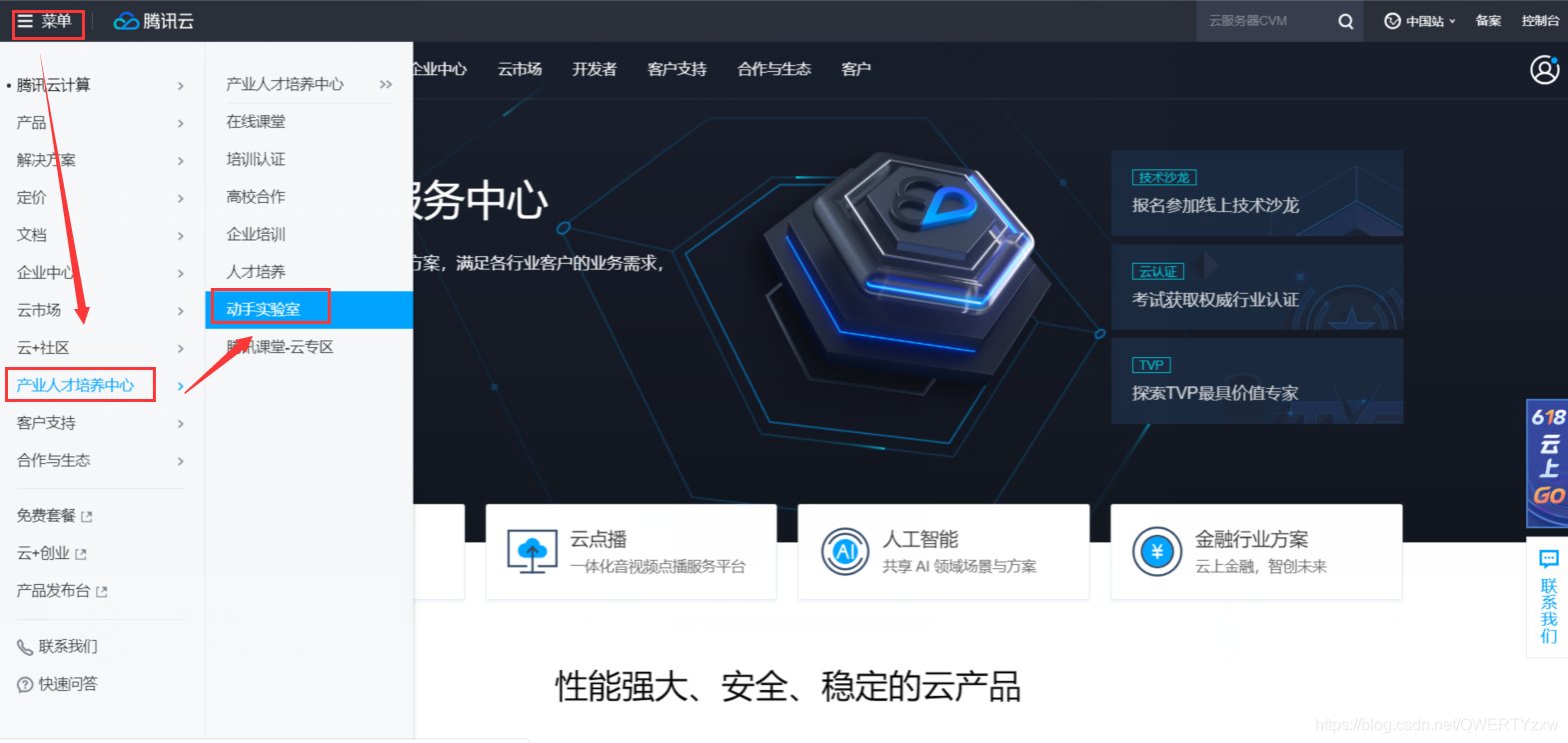
点击全部实验列表
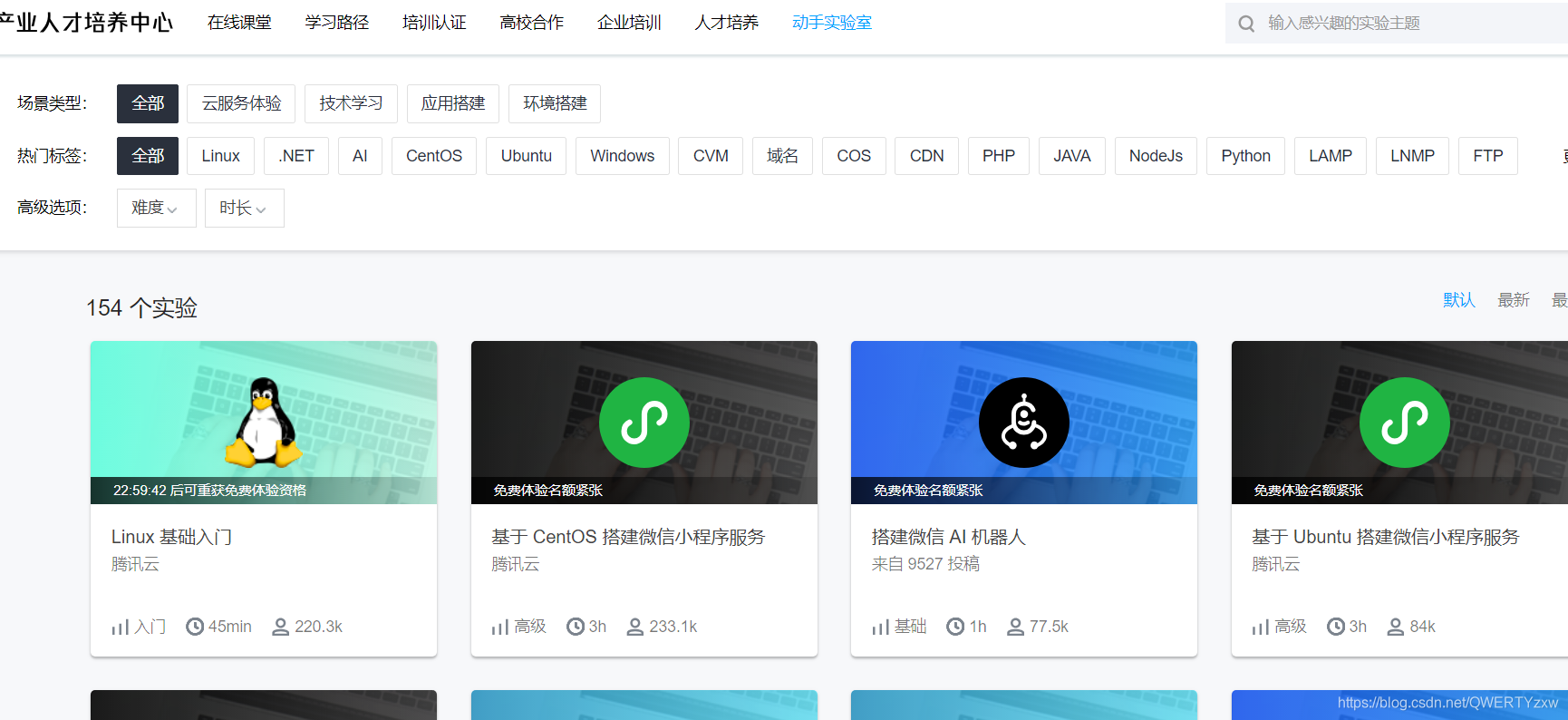
关于云服务器的购买,可根据需求自行选择。
二、Linux常用操作
1、目录操作
使用mkdir创建目录
mkdir $HOME/testFolder

使用cd切换到目录
cd $HOME/testFolder

使用cd …/切换到上一级目录
cd ../

使用mv命令移动目录
mv $HOME/testFolder /var/tmp

使用rm -rf 删除目录
rm -rf /var/tmp/testFolder

使用ls /etc查看当前目录下的所有文件以及文件夹
ls /etc
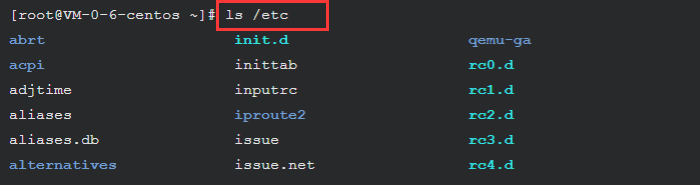
2、文件操作
使用touch创建文件
touch ~/testFile

执行 ls 命令, 可以看到刚才新建的 testFile 文件
ls ~

使用cp复制文件
cp ~/testFile ~/testNewFile

使用 rm 命令删除文件, 输入 y 后回车确认删除
rm ~/testFile

使用 cat 命令查看 .bash_history 文件内容
cat ~/.bash_history
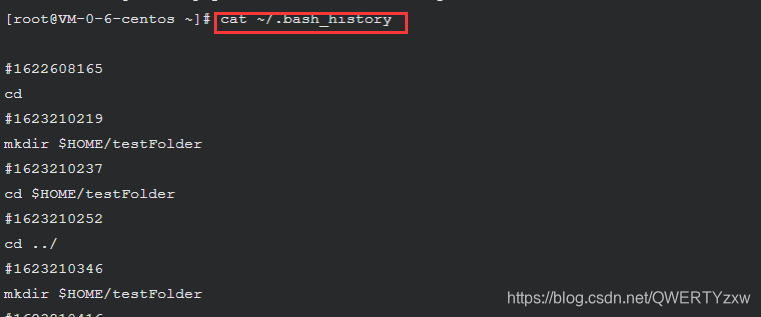
3、过滤、管道与重定向
过滤
过滤出 /etc/passwd 文件中包含 root 的记录
grep 'root' /etc/passwd

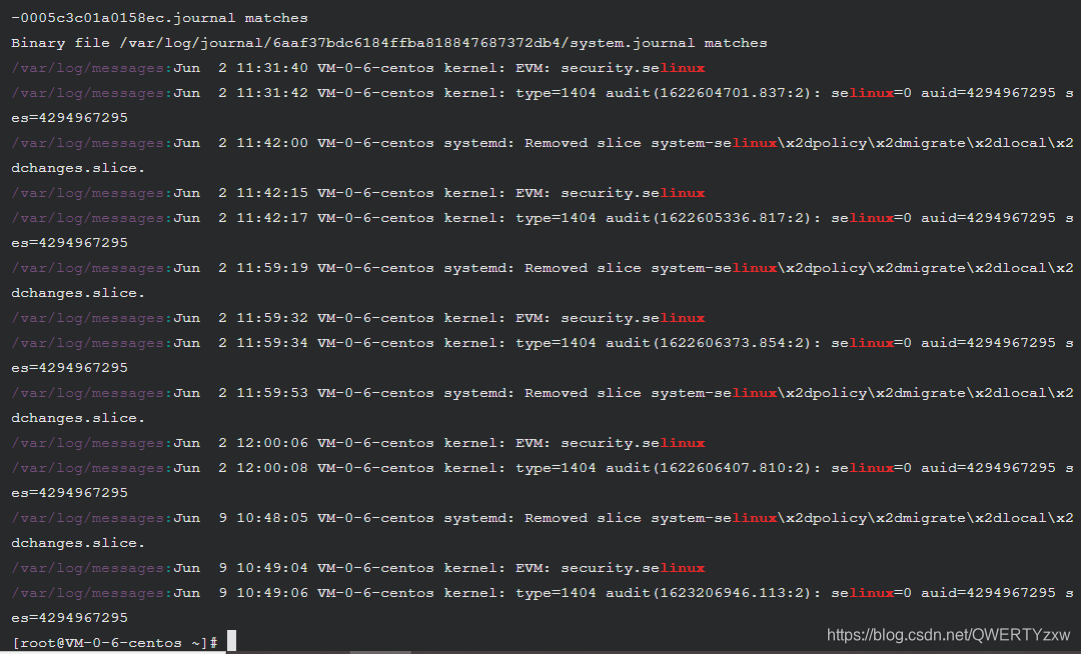
递归地过滤出 /var/log/ 目录中包含 linux 的记录
grep -r 'linux' /var/log/
管道
简单来说, Linux 中管道的作用是将上一个命令的输出作为下一个命令的输入, 像 pipe 一样将各个命令串联起来执行, 管道的操作符是 |
将 cat 和 grep 两个命令用管道组合在一起
cat /etc/passwd | grep 'root'

过滤出 /etc 目录中名字包含 ssh 的目录(不包括子目录)
ls /etc | grep 'ssh'

重定向
可以使用 > 或 < 将命令的输出重定向到一个文件中
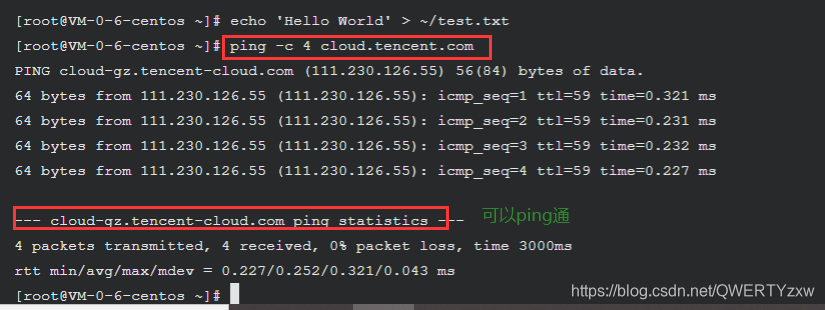
echo 'Hello World' > ~/test.txt

4、运维常用命令
对 cloud.tencent.com 发送 4 个 ping 包, 检查与其是否联通
ping -c 4 cloud.tencent.com
5、netstat命令
netstat 命令用于显示各种网络相关信息,如网络连接, 路由表, 接口状态等等
列出所有处于监听状态的tcp端口
netstat -lt

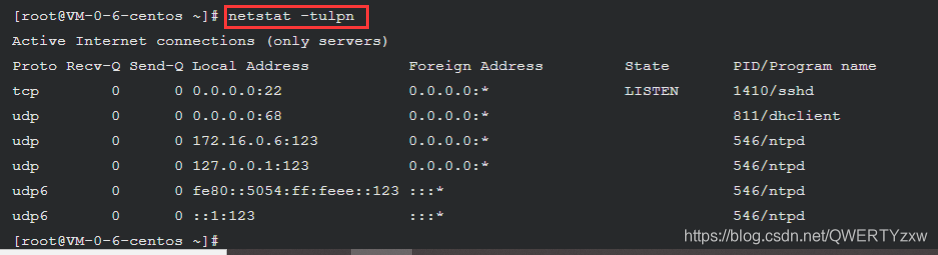
查看所有的端口信息, 包括 PID 和进程名称
netstat -tulpn
6、ps命令
过滤得到当前系统中的 ssh 进程信息
ps aux | grep 'ssh'

三、搭配Hadoop伪分布式环境
hadoop是一个由Apache基金会所开发的分布式系统基础架构。它可以使用户在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。hadoop的框架最核心的设计就是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。
1、创建用户
创建一个普通用户 hadoop
sudo useradd -m hadoop -s /bin/bash
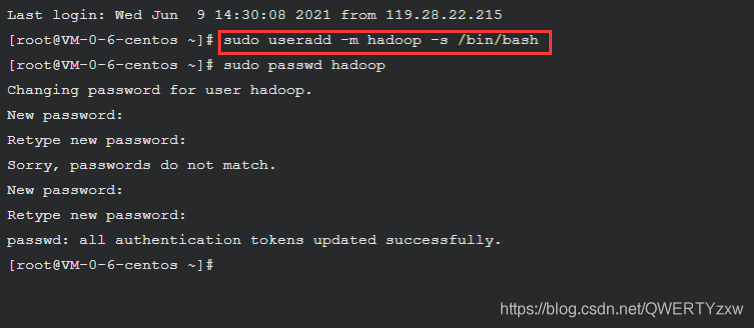
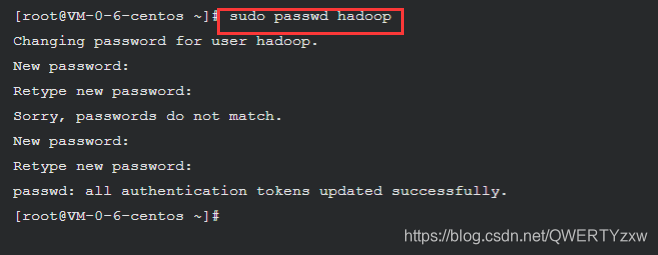
设置密码
sudo passwd hadoop
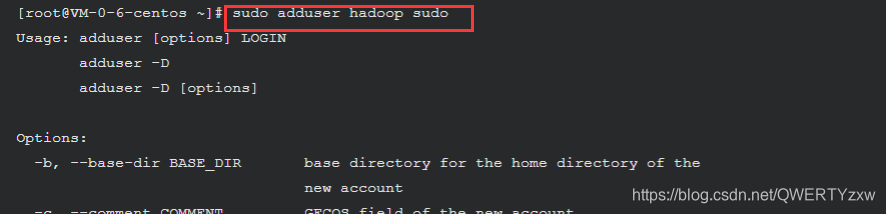
用户增加 sudo 管理员权限
sudo adduser hadoop sudo
2、安装ssh
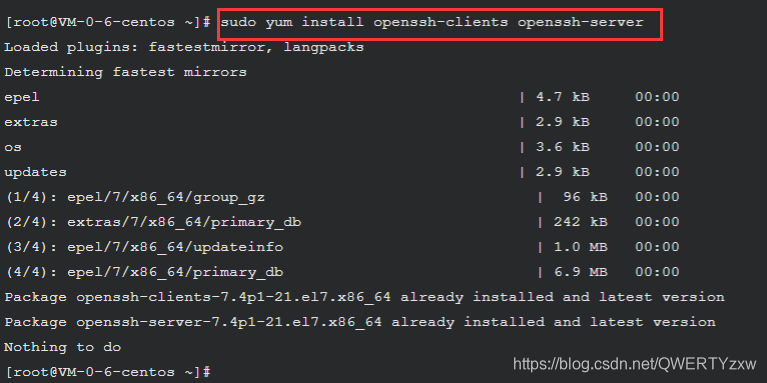
安装SSH
sudo yum install openssh-clients openssh-server
安装完成后,可以使用下面命令进行测试
ssh localhost

使用exit退出ssh
exit
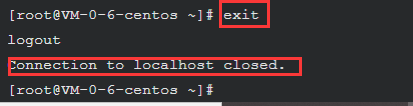
输入 root 账户的密码,如果可以正常登录,则说明SSH安装没有问题。测试正常后使用 exit 命令退出ssh。
3、安装java环境
使用 yum 来安装1.7版本 OpenJDK
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel

安装完成后,输入 java 和 javac 命令,如果能输出对应的命令帮助,则表明jdk已正确安装
java
javac
配置环境
编辑 ~/.bashrc,在结尾追加(保存)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk

保存文件后执行下面命令使 JAVA_HOME 环境变量生效
source ~/.bashrc

为了检测系统中 JAVA 环境是否已经正确配置并生效,可以分别执行下面命令
java -version
$JAVA_HOME/bin/java -version

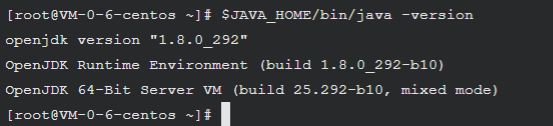
若两条命令输出的结果一致,且都为我们前面安装的 openjdk-1.8.0 的版本,则表明 JDK 环境已经正确安装并配置。
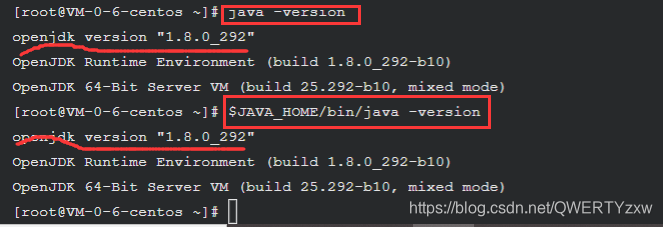
经比较,两种相同
4、安装Hadoop
下载Hadoop
本教程使用 hadoop-2.7 版本,使用 wget 工具在线下载(注:本教程是从清华大学的镜像源下载,如果下载失败或报错,可以自己在网上找到国内其他一个镜像源下载 2.7 版本的 hadoop 即可)
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz

下载完成

安装Hadoop
将 Hadoop 安装到 /usr/local 目录下
tar -zxf hadoop-2.7.4.tar.gz -C /usr/local

对安装的目录进行重命名,便于后续操作方便
cd /usr/local
mv ./hadoop-2.7.4/ ./hadoop

检查Hadoop是否已经正确安装
/usr/local/hadoop/bin/hadoop version
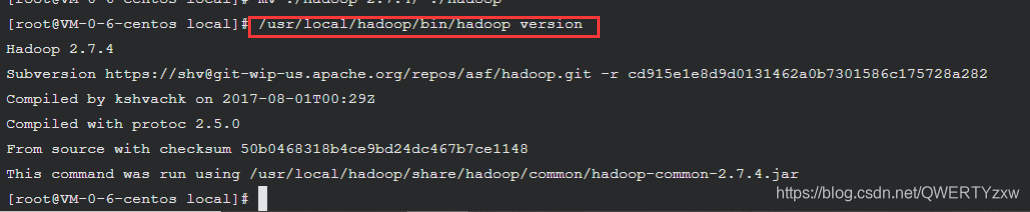
如果成功输出hadoop的版本信息,表明hadoop已经成功安装。
5、Hadoop伪分布式环境配置
Hadoop伪分布式模式使用多个守护线程模拟分布的伪分布运行模式。
设置 Hadoop 的环境变量
编辑 ~/.bashrc,在结尾追加如下内容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin

保存
使Hadoop环境变量配置生效
source ~/.bashrc

修改 Hadoop 的配置文件
Hadoop的配置文件位于安装目录的 /etc/hadoop 目录下,在本教程中即位于 /url/local/hadoop/etc/hadoop 目录下,需要修改的配置文件为如下两个
/usr/local/hadoop/etc/hadoop/core-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml
编辑 core-site.xml,修改节点的内容为如下所示:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>

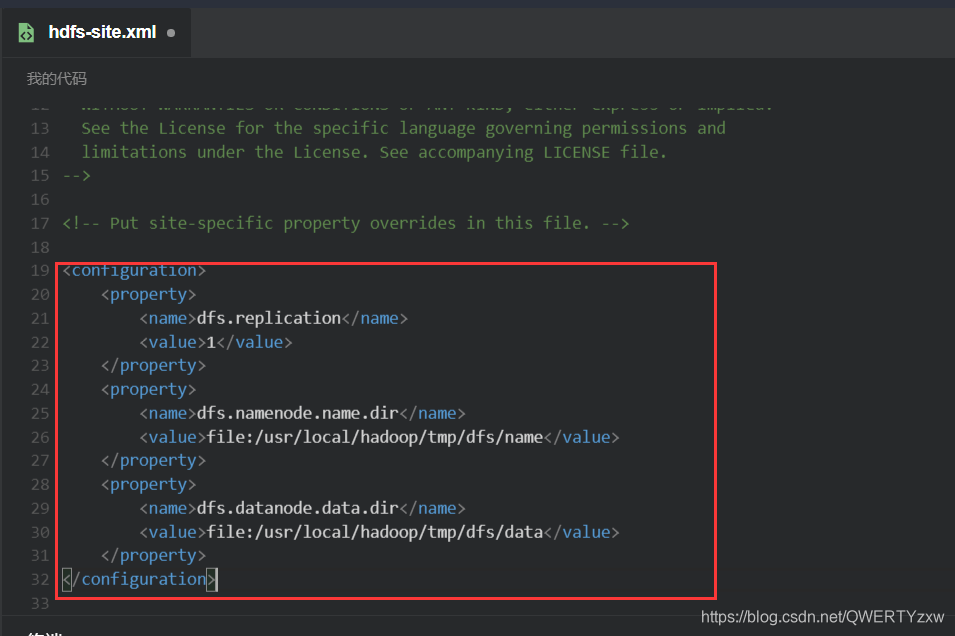
同理,编辑 hdfs-site.xml,修改节点的内容为如下所示:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
格式化 NameNode
/usr/local/hadoop/bin/hdfs namenode -format
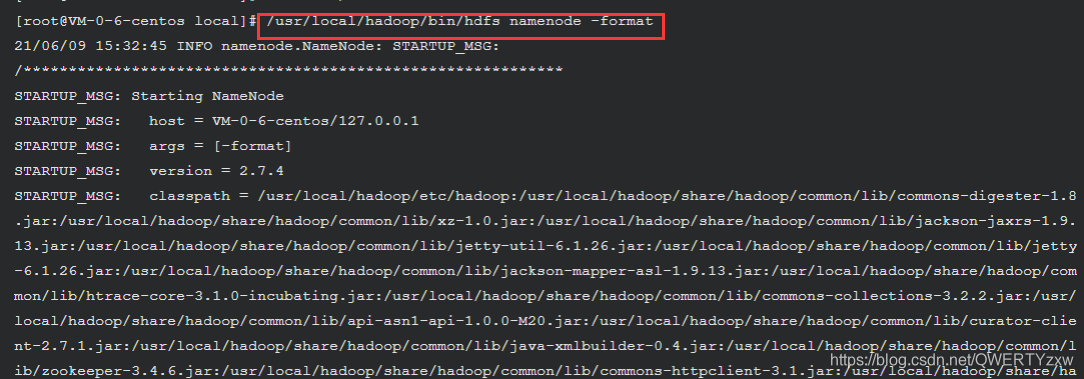
在输出信息中看到如下信息,则表示格式化成功:
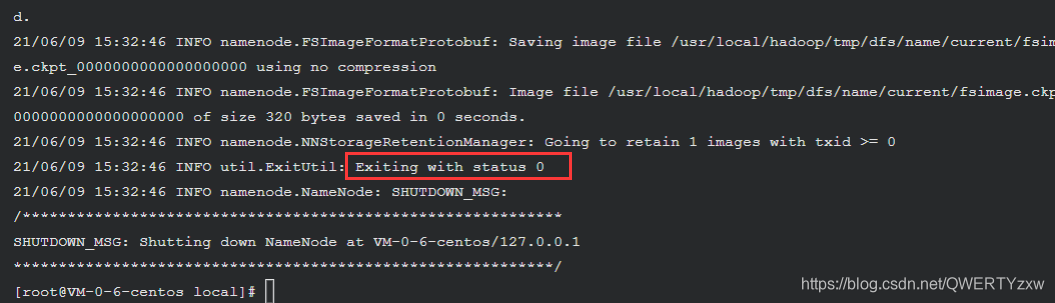
Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted.
Exiting with status 0
启动 NameNode 和 DataNode 守护进程
/usr/local/hadoop/sbin/start-dfs.sh
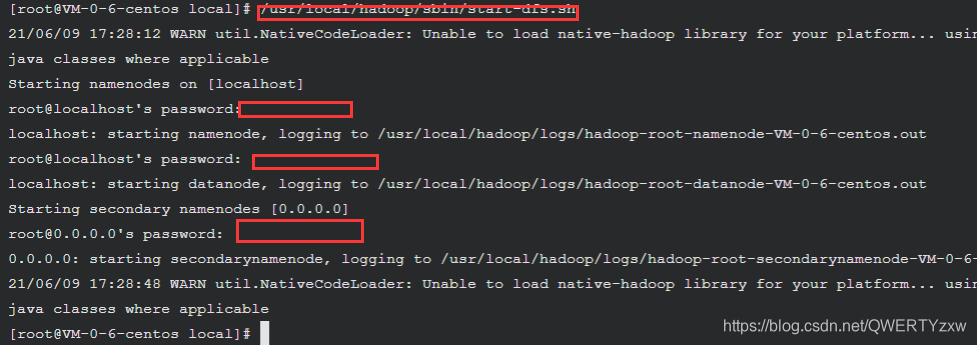
执行过程中会提示输入用户密码,输入 root 用户密码即可。另外,启动时ssh会显示警告提示是否继续连接,输入 yes 即可。
检查 NameNode 和 DataNode 是否正常启动
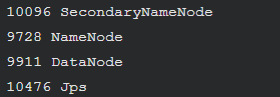
jps
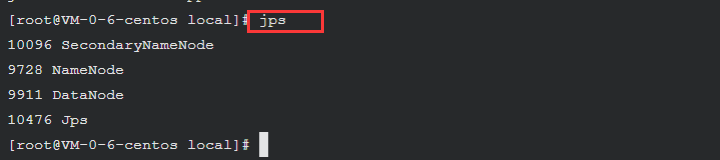
如果NameNode和DataNode已经正常启动,会显示NameNode、DataNode和SecondaryNameNode的进程信息
6、运行Hadoop伪分布式实例
Hadoop自带了丰富的例子,包括 wordcount、grep、sort 等。下面我们将以grep例子为教程,输入一批文件,从中筛选出符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数。
查看 Hadoop 自带的例子
Hadoop 附带了丰富的例子, 执行下面命令可以查看
cd /usr/local/hadoop
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar

在 HDFS 中创建用户目录
/usr/local/hadoop/bin/hdfs dfs -mkdir -p /user/hadoop

准备实验数据
本教程中,我们将以 Hadoop 所有的 xml 配置文件作为输入数据来完成实验。执行下面命令在 HDFS 中新建一个 input 文件夹并将 hadoop 配置文件上传到该文件夹下
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir /user/hadoop/input
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input

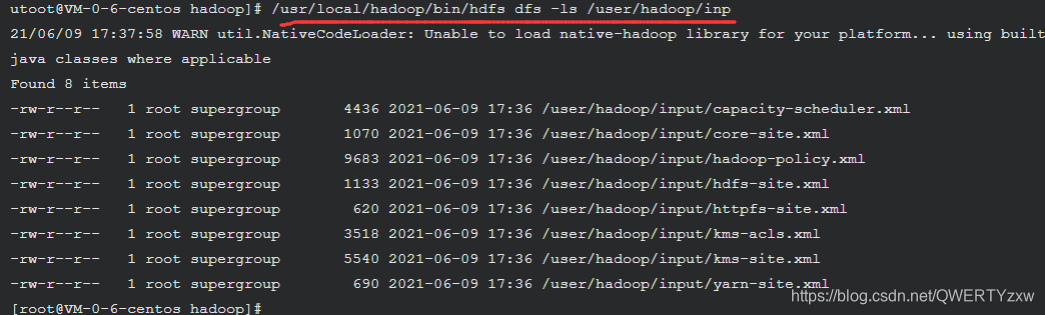
使用下面命令可以查看刚刚上传到 HDFS 的文件
/usr/local/hadoop/bin/hdfs dfs -ls /user/hadoop/input
运行实验
cd /usr/local/hadoop
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
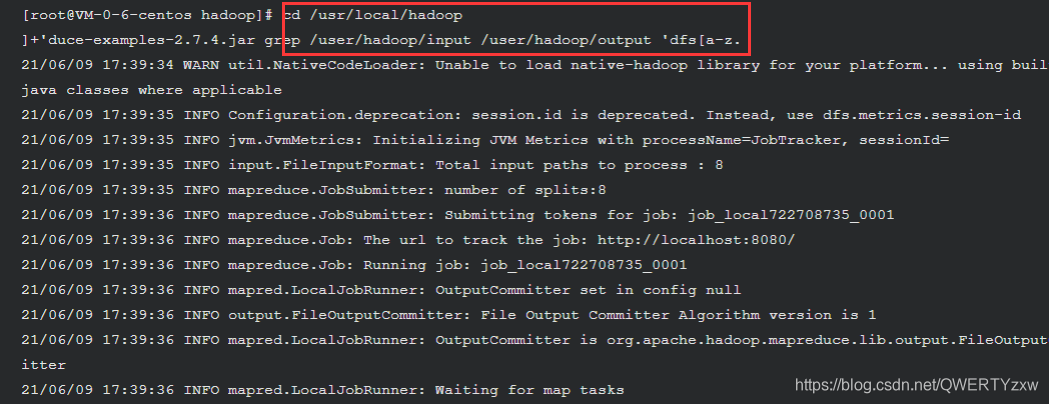
上述命令以 HDFS 文件系统中的 input 为输入数据来运行 Hadoop 自带的 grep 程序,提取其中符合正则表达式 dfs[a-z.]+ 的数据并进行次数统计,将结果输出到 HDFS 文件系统的 output 文件夹下
通过下面命令查看结果
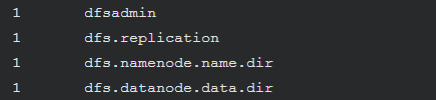
/usr/local/hadoop/bin/hdfs dfs -cat /user/hadoop/output/*

如果运行成功,可以看到如下结果
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
删除 HDFS 上的输出结果
/usr/local/hadoop/bin/hdfs dfs -rm -r /user/hadoop/output

运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录不能存在,否则会提示错误,因此在下次运行前需要先删除输出目录。
关闭 Hadoop 进程
/usr/local/hadoop/sbin/stop-dfs.sh

再起启动只需要执行下面命令
/usr/local/hadoop/sbin/start-dfs.sh
四、总结
本篇文章主要是对Linux和Hadoop的常用操作进行实践。