在爬取网站过程中,通常会遇到局部动态刷新情况,当你点击“下一页”或某一页时,它的数据就进行刷新,但其顶部的URL始终不变。这种局部动态刷新的网站,怎么爬取数据呢?某网站数据显示如下图所示,当点击“第五页”之时,其URL始终不变,传统的网站爬取方法是无法拼接这类链接的,所以本篇文章主要解决这个问题。
本文主要采用Selenium爬取局部动态刷新的网站,获取“下一页”按钮实现自动点击跳转,再依次爬取每一页的内容。希望对您有所帮助,尤其是遇到同样问题的同学,如果文章中出现错误或不足之处,还请海涵~
一. Selenium爬取第一页信息
首先,我们尝试使用Selenium爬取第一页的内容,采用浏览器右键“审查”元素,可以看到对应的HTML源代码,如下图所示,可以看到,每一行工程信息都位于<table class="table table-hover">节点下的<tr>...</tr>中。
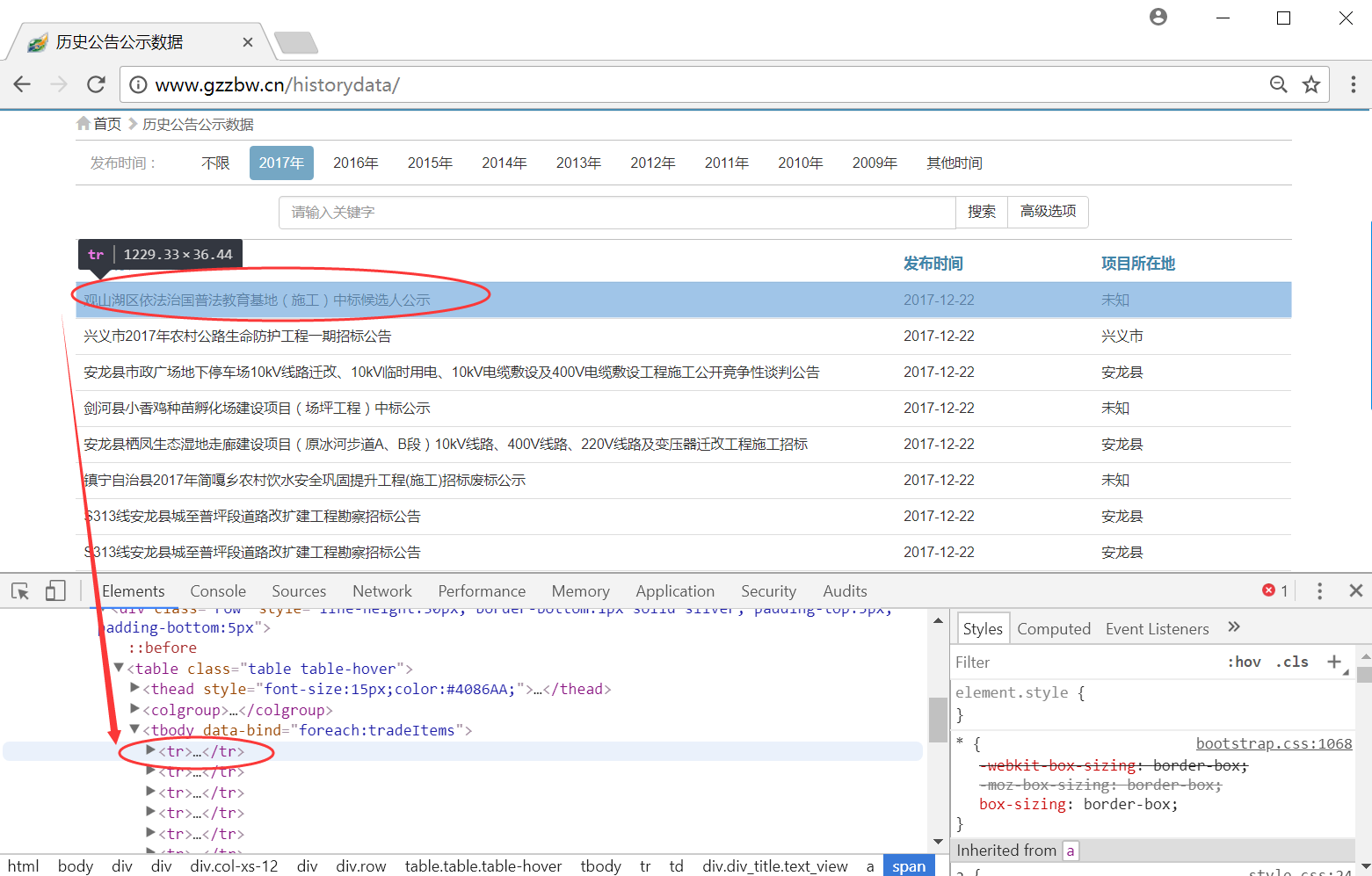
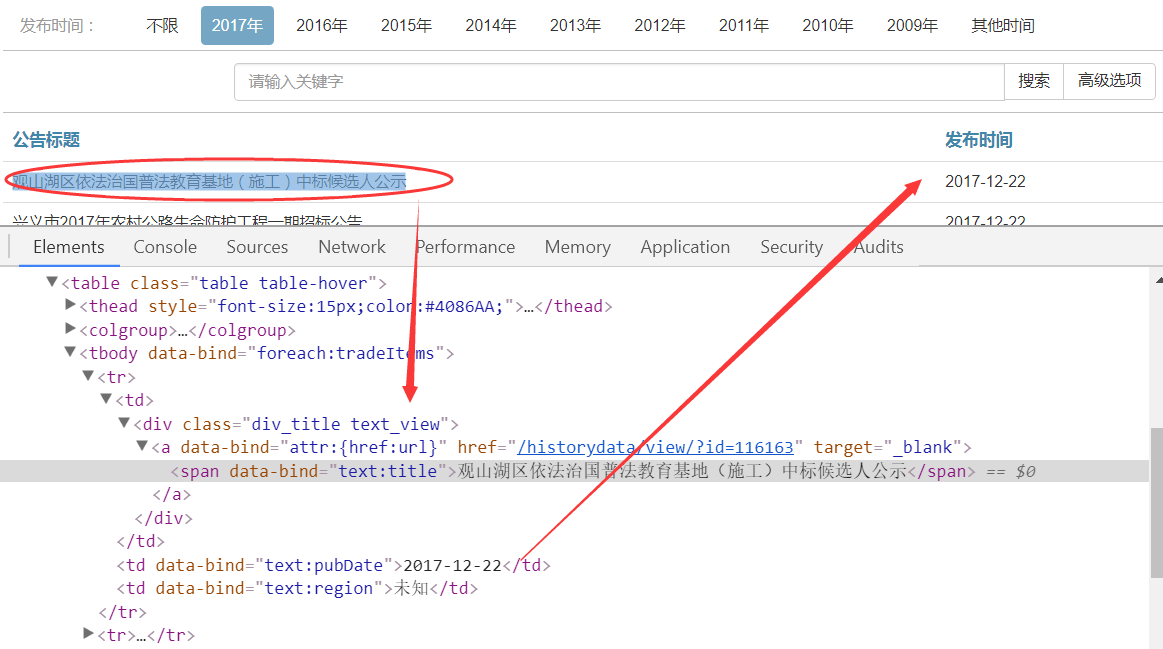
然后我们再展开其中一个<tr>...</tr>节点,看它的源码详情,如下图所示,包括公告标题、发布时间、项目所在地。如果我们需要抓取公告标题,则定位<div class="div_title text_view">节点,再获取标题内容和超链接。
完整代码如下:
# coding=utf-8
from selenium import webdriver
import re
import time
import os
print "start"
#打开Firefox浏览器 设定等待加载时间
driver = webdriver.Firefox()
#定位节点
url = 'http:/www.xxxx.com/'
print url
driver.get(url)
content = driver.find_elements_by_xpath("//div[@class='div_title text_view']")
for u in content:
print u.text
输出内容如下图所示:
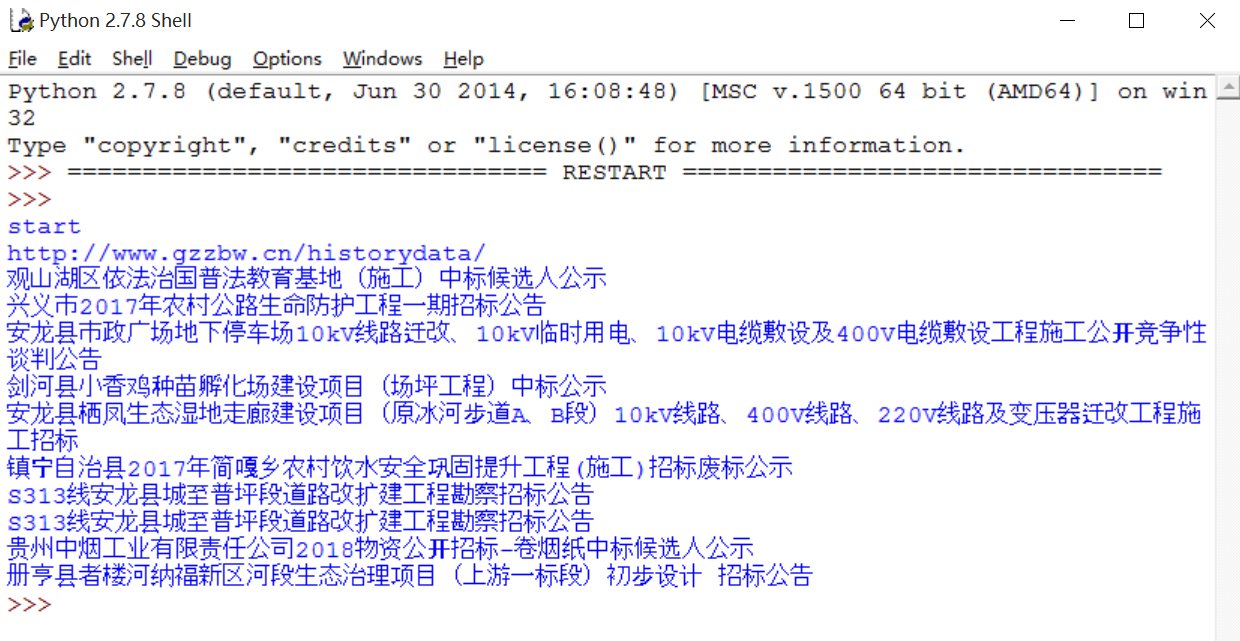
PS:由于网站安全问题,我不直接给出网址,主要给出爬虫的核心思想。同时,下面的代码我也没有给出网址,但思路一样,请大家替换成自己的局部刷新网址进行测试。
二. Selenium实现局部动态刷新爬取
接下来我们想爬取第2页的网站内容,其代码步骤如下:
1.定位驱动:driver = webdriver.Firefox()
2.访问网址:driver.get(url)
3.定位节点获取第一页内容并爬取:driver.find_elements_by_xpath()
4.获取“下一页”按钮,并调用click()函数点击跳转
5.爬取第2页的网站内容:driver.find_elements_by_xpath()
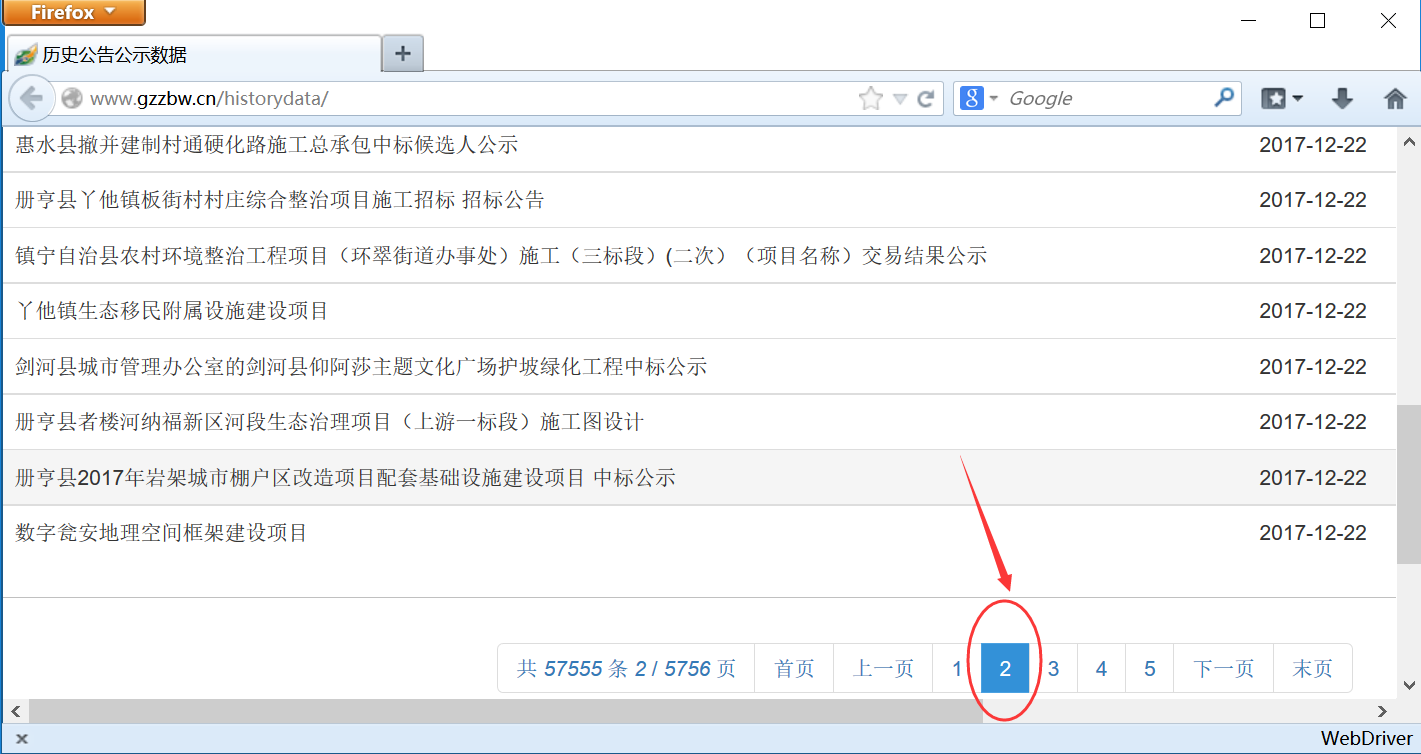
其核心步骤是获取“下一页”按钮,并调用Selenium自动点击按钮技术,从而实现跳转,之后再爬取第2页内容。“下一页”按钮的源代码如下图所示:
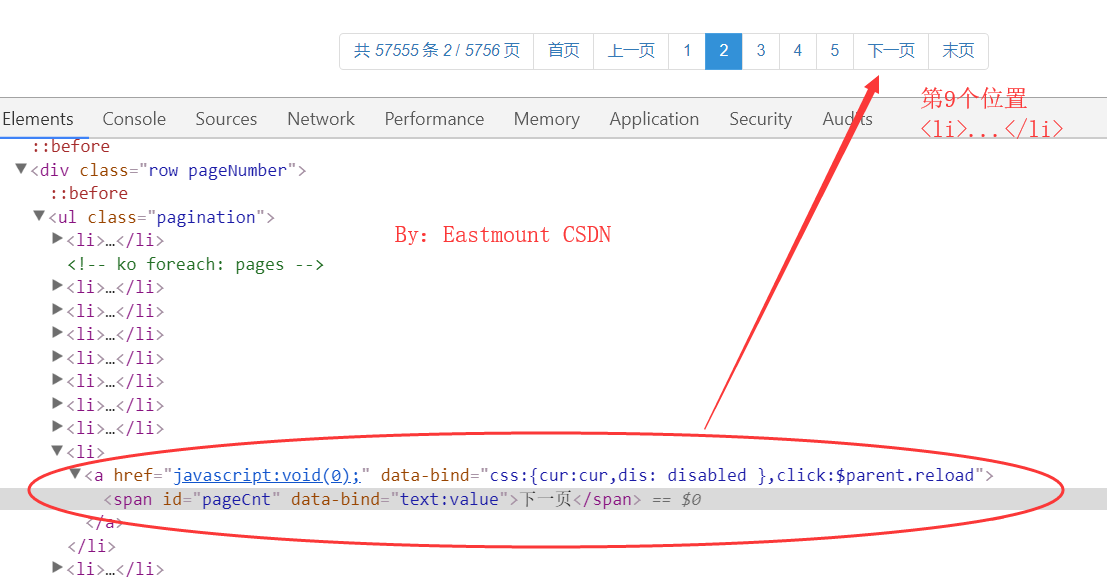
其中,“下一页”按钮始终在第9个<li>...</li>位置,则核心代码如下:
nextPage = driver.find_element_by_xpath("//ul[@class='pagination']/li[9]/a")
nextPage.click()
完整代码如下:
# coding=utf-8
from selenium import webdriver
import re
import time
import os
print "start"
driver = webdriver.Firefox()
url = 'http://www.XXXX.com/'
print url
driver.get(url)
#项目名称
titles = driver.find_elements_by_xpath("//div[@class='div_title text_view']")
for u in titles:
print u.text
#超链接
urls = driver.find_elements_by_xpath("//div[@class='div_title text_view']/a")
for u in urls:
print u.get_attribute("href")
#时间
times = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[2]")
for u in times:
print u.text
#地点
places = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[3]")
for u in places:
print u.text
#点击下一页
nextPage = driver.find_element_by_xpath("//ul[@class='pagination']/li[9]/a")
print nextPage.text
nextPage.click()
time.sleep(5)
#爬取第2页数据
content = driver.find_elements_by_xpath("//div[@class='div_title text_view']")
for u in content:
print u.text
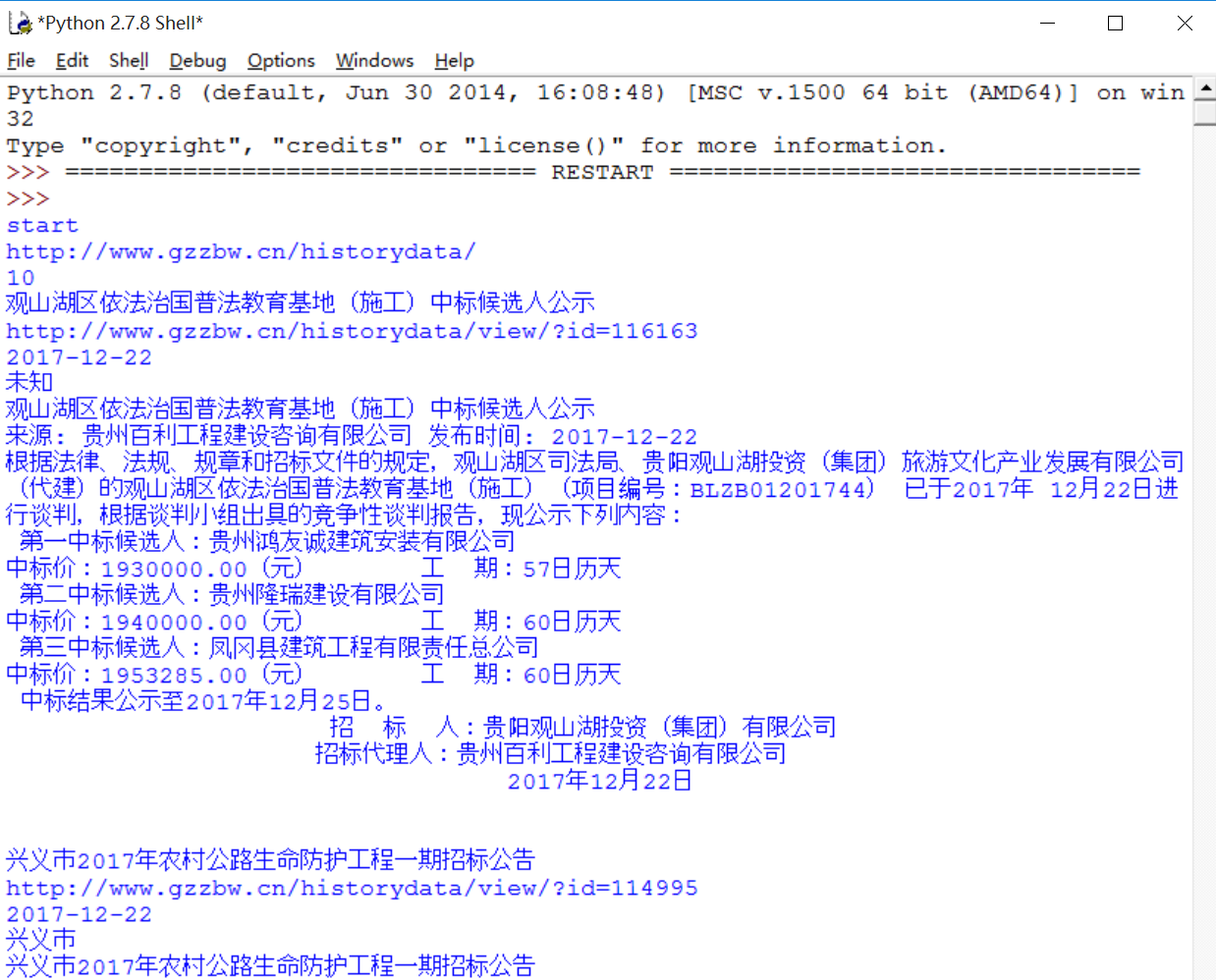
输出内容如下所示,可以看到第二页的内容也爬取成功了,并且作者爬取了公告主题、超链接、发布时间、发布地点。
>>> start http://www.xxxx.com/ 观山湖区依法治国普法教育基地(施工)中标候选人公示 兴义市2017年农村公路生命防护工程一期招标公告 安龙县市政广场地下停车场10kV线路迁改、10kV临时用电、10kV电缆敷设及400V电缆敷设工程施工公开竞争性谈判公告 剑河县小香鸡种苗孵化场建设项目(场坪工程)中标公示 安龙县栖凤生态湿地走廊建设项目(原冰河步道A、B段)10kV线路、400V线路、220V线路及变压器迁改工程施工招标 镇宁自治县2017年简嘎乡农村饮水安全巩固提升工程(施工)招标废标公示 S313线安龙县城至普坪段道路改扩建工程勘察招标公告 S313线安龙县城至普坪段道路改扩建工程勘察招标公告 贵州中烟工业有限责任公司2018物资公开招标-卷烟纸中标候选人公示 册亨县者楼河纳福新区河段生态治理项目(上游一标段)初步设计 招标公告 http://www.gzzbw.cn/historydata/view/?id=116163 http://www.gzzbw.cn/historydata/view/?id=114995 http://www.gzzbw.cn/historydata/view/?id=115720 http://www.gzzbw.cn/historydata/view/?id=116006 http://www.gzzbw.cn/historydata/view/?id=115719 http://www.gzzbw.cn/historydata/view/?id=115643 http://www.gzzbw.cn/historydata/view/?id=114966 http://www.gzzbw.cn/historydata/view/?id=114965 http://www.gzzbw.cn/historydata/view/?id=115400 http://www.gzzbw.cn/historydata/view/?id=116031 2017-12-22 2017-12-22 2017-12-22 2017-12-22 2017-12-22 2017-12-22 2017-12-22 2017-12-22 2017-12-22 2017-12-22 未知 兴义市 安龙县 未知 安龙县 未知 安龙县 安龙县 未知 册亨县 下一页 册亨县丫他镇板其村埃近1~2组村庄综合整治项目 册亨县者楼河纳福新区河段生态治理项目(上游一标段)勘察 招标公告 惠水县撤并建制村通硬化路施工总承包中标候选人公示 册亨县丫他镇板街村村庄综合整治项目施工招标 招标公告 镇宁自治县农村环境整治工程项目(环翠街道办事处)施工(三标段)(二次)(项目名称)交易结果公示 丫他镇生态移民附属设施建设项目 剑河县城市管理办公室的剑河县仰阿莎主题文化广场护坡绿化工程中标公示 册亨县者楼河纳福新区河段生态治理项目(上游一标段)施工图设计 册亨县2017年岩架城市棚户区改造项目配套基础设施建设项目 中标公示 数字瓮安地理空间框架建设项目 >>>Firefox成功跳转到第2页,此时你增加一个循环则可以跳转很多页,并爬取信息,详见第三个步骤。
三. Selenium爬取详情页面
上面爬取了每行公告信息的详情页面超链接(URL),本来我准备采用BeautifulSoup爬虫爬取详情页面信息的,但是被拦截了,详情页面如下图所示:

# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import re
import time
import os
print "start"
#打开Firefox浏览器
driver = webdriver.Firefox()
driver2 = webdriver.Firefox()
url = 'http://www.xxxx.com/'
print url
driver.get(url)
#项目名称
titles = driver.find_elements_by_xpath("//div[@class='div_title text_view']")
#超链接
urls = driver.find_elements_by_xpath("//div[@class='div_title text_view']/a")
num = []
for u in urls:
href = u.get_attribute("href")
driver2.get(href)
con = driver2.find_element_by_xpath("//div[@class='col-xs-9']")
#print con.text
num.append(con.text)
#时间
times = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[2]")
#地点
places = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[3]")
#输出所有结果
print len(num)
i = 0
while i<len(num):
print titles[i].text
print urls[i].get_attribute("href")
print times[i].text
print places[i].text
print num[i]
print ""
i = i + 1
#点击下一页
j = 0
while j<5:
nextPage = driver.find_element_by_xpath("//ul[@class='pagination']/li[9]/a")
print nextPage.text
nextPage.click()
time.sleep(5)
#项目名称
titles = driver.find_elements_by_xpath("//div[@class='div_title text_view']")
#超链接
urls = driver.find_elements_by_xpath("//div[@class='div_title text_view']/a")
num = []
for u in urls:
href = u.get_attribute("href")
driver2.get(href)
con = driver2.find_element_by_xpath("//div[@class='col-xs-9']")
num.append(con.text)
#时间
times = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[2]")
#地点
places = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[3]")
#输出所有结果
print len(num)
i = 0
while i<len(num):
print titles[i].text
print urls[i].get_attribute("href")
print times[i].text
print places[i].text
print num[i]
print ""
i = i + 1
j = j + 1
注意作者定义了一个while循环,一次性输出一条完整的招标信息,代码如下:
print len(num)
i = 0
while i<len(num):
print titles[i].text
print urls[i].get_attribute("href")
print times[i].text
print places[i].text
print num[i]
print ""
i = i + 1
输出结果如下图所示:
其中一条完整的结果如下所示:
观山湖区依法治国普法教育基地(施工)中标候选人公示
http://www.gzzbw.cn/historydata/view/?id=116163
2017-12-22
未知
观山湖区依法治国普法教育基地(施工)中标候选人公示
来源: 贵州百利工程建设咨询有限公司 发布时间: 2017-12-22
根据法律、法规、规章和招标文件的规定,观山湖区司法局、贵阳观山湖投资(集团)旅游文化产业发展有限公司(代建)的观山湖区依法治国普法
教育基地(施工)(项目编号:BLZB01201744) 已于2017年 12月22日进行谈判,根据谈判小组出具的竞争性谈判报告,现公示下列内容:
第一中标候选人:贵州鸿友诚建筑安装有限公司
中标价:1930000.00(元) 工 期:57日历天
第二中标候选人:贵州隆瑞建设有限公司
中标价:1940000.00(元) 工 期:60日历天
第三中标候选人:凤冈县建筑工程有限责任总公司
中标价:1953285.00(元) 工 期:60日历天
中标结果公示至2017年12月25日。
招 标 人:贵阳观山湖投资(集团)有限公司
招标代理人:贵州百利工程建设咨询有限公司
2017年12月22日
最后读者可以结合MySQLdb库,将爬取的内容存储至本地中。同时,如果您爬取的内容需要设置时间,比如2015年的数据,则在爬虫开始之前设置time.sleep(5)暂定函数,手动点击2015年或输入关键字,再进行爬取。也建议读者采用Selenium技术来自动跳转,而详情页面采用BeautifulSoup爬取。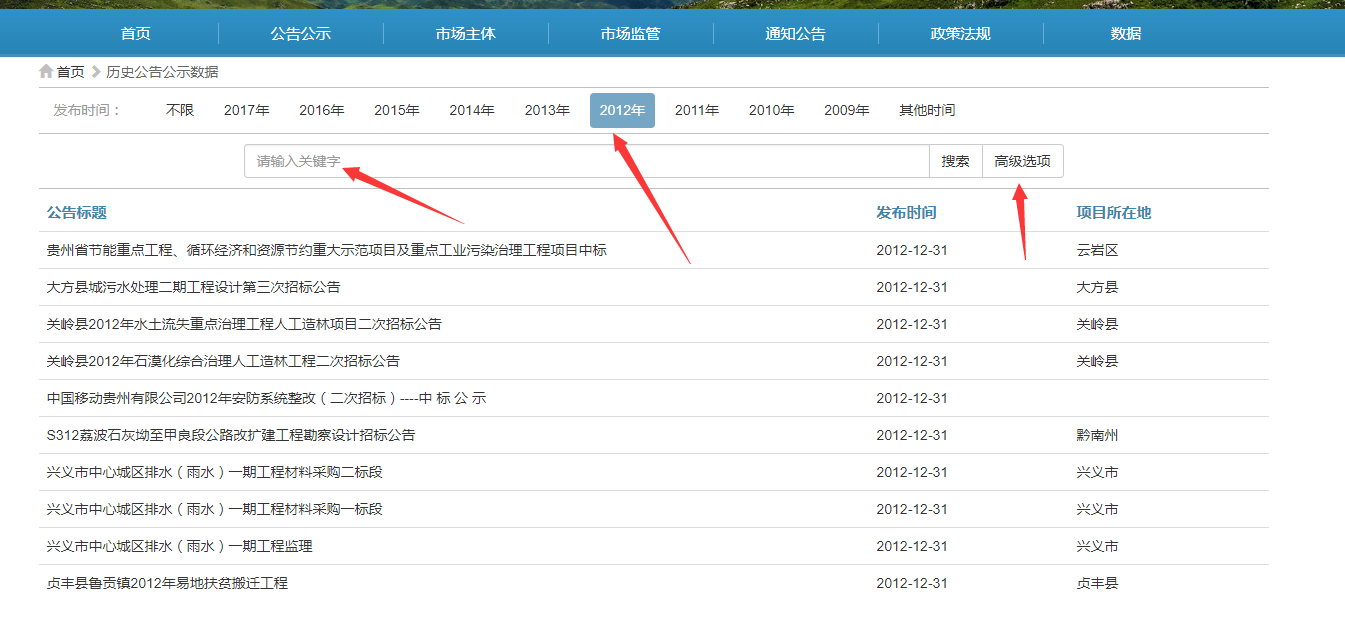
# coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
import re
import time
import os
import codecs
from bs4 import BeautifulSoup
import urllib
import MySQLdb
#存储数据库
#参数:公告名称 发布时间 发布地点 发布内容
def DatabaseInfo(title,url,fbtime,fbplace,content):
try:
conn = MySQLdb.connect(host='localhost',user='root',
passwd='123456',port=3306, db='20180426ztb')
cur=conn.cursor() #数据库游标
#报错:UnicodeEncodeError: 'latin-1' codec can't encode character
conn.set_character_set('utf8')
cur.execute('SET NAMES utf8;')
cur.execute('SET CHARACTER SET utf8;')
cur.execute('SET character_set_connection=utf8;')
#SQL语句 智联招聘(zlzp)
sql = '''insert into ztb
(title, url, fbtime, fbplace, content)
values(%s, %s, %s, %s, %s);'''
cur.execute(sql, (title,url,fbtime,fbplace,content))
print '数据库插入成功'
#异常处理
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
finally:
cur.close()
conn.commit()
conn.close()
print "start"
#打开Firefox浏览器
driver = webdriver.Firefox()
driver2 = webdriver.Firefox()
url = 'http://www.gzzbw.cn/historydata/'
print url
driver.get(url)
#项目名称
titles = driver.find_elements_by_xpath("//div[@class='div_title text_view']")
#超链接
urls = driver.find_elements_by_xpath("//div[@class='div_title text_view']/a")
num = []
for u in urls:
href = u.get_attribute("href")
driver2.get(href)
con = driver2.find_element_by_xpath("//div[@class='col-xs-9']")
#print con.text
num.append(con.text)
#时间
times = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[2]")
#地点
places = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[3]")
#输出所有结果
print len(num)
i = 0
while i<len(num):
print titles[i].text
print urls[i].get_attribute("href")
print times[i].text
print places[i].text
print num[i]
print ""
DatabaseInfo(titles[i].text, urls[i].get_attribute("href"), times[i].text,
places[i].text, num[i])
i = i + 1
#点击下一页
j = 0
while j<100:
nextPage = driver.find_element_by_xpath("//ul[@class='pagination']/li[9]/a")
print nextPage.text
nextPage.click()
time.sleep(5)
#项目名称
titles = driver.find_elements_by_xpath("//div[@class='div_title text_view']")
#超链接
urls = driver.find_elements_by_xpath("//div[@class='div_title text_view']/a")
num = []
for u in urls:
href = u.get_attribute("href")
driver2.get(href)
con = driver2.find_element_by_xpath("//div[@class='col-xs-9']")
num.append(con.text)
#时间
times = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[2]")
#地点
places = driver.find_elements_by_xpath("//table[@class='table table-hover']/tbody/tr/td[3]")
#输出所有结果
print len(num)
i = 0
while i<len(num):
print titles[i].text
print urls[i].get_attribute("href")
print times[i].text
print places[i].text
print num[i]
print ""
DatabaseInfo(titles[i].text, urls[i].get_attribute("href"), times[i].text,
places[i].text, num[i])
i = i + 1
print u"已爬取页码:", (j+2)
j = j + 1
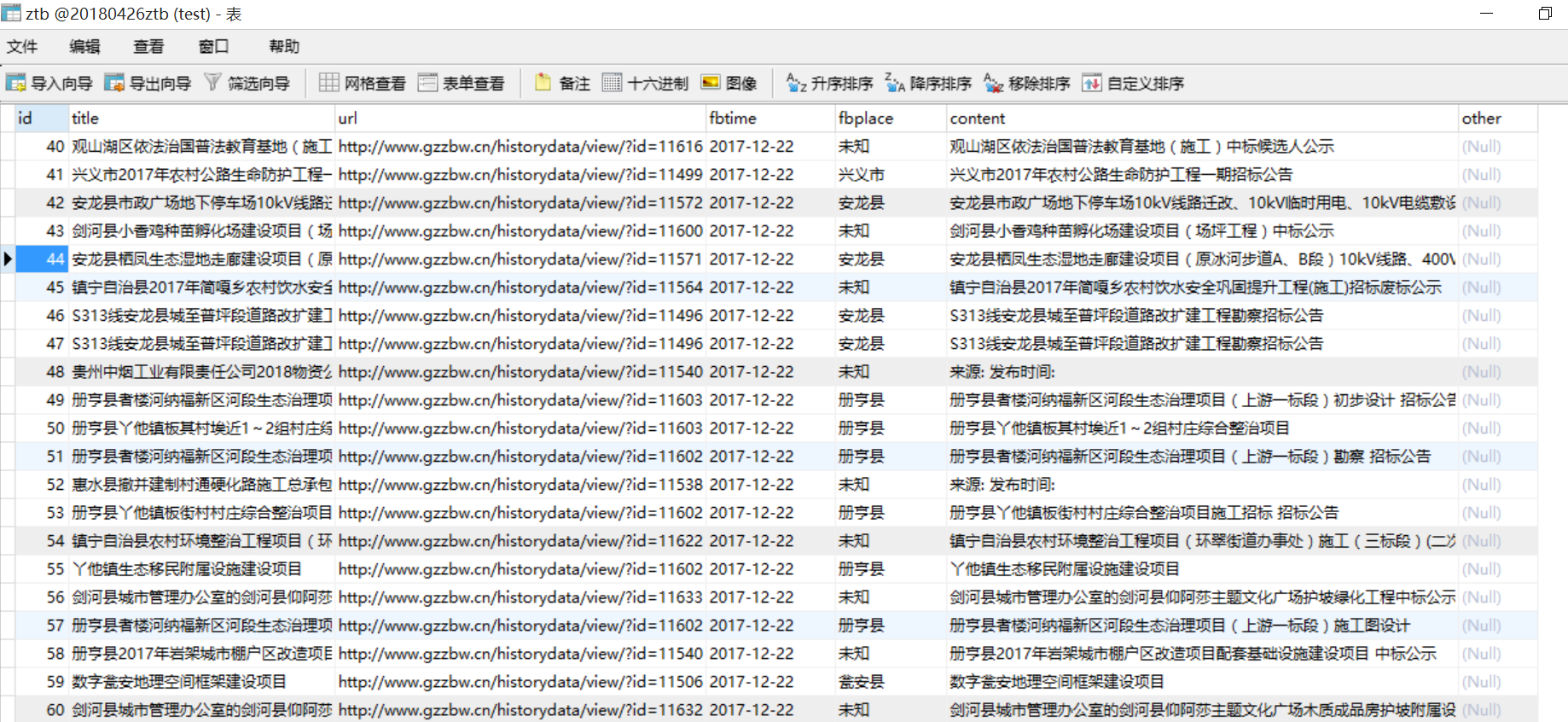
存储至数据库:
最后希望文章对您有所帮助,尤其是要爬取局部刷新的同学,
如果文章中出现错误或不足之处,还请海涵~
(By:Eastmount 2018-04-26 早上11点半 http://blog.csdn.net/eastmount/ )