前言
并查集被很多OIer认为是最简洁而优雅的数据结构之一,主要用于解决一些元素分组的问题。它管理一系列不相交的集合,并支持两种操作:
- 合并(Union):把两个不相交的集合合并为一个集合。
- 查询(Find):查询两个元素是否在同一个集合中。
并查集的重要思想在于,用集合中的一个元素代表集合。我曾看过一个有趣的比喻,把集合比喻成帮派,而代表元素则是帮主。接下来我们利用这个比喻,看看并查集是如何运作的。
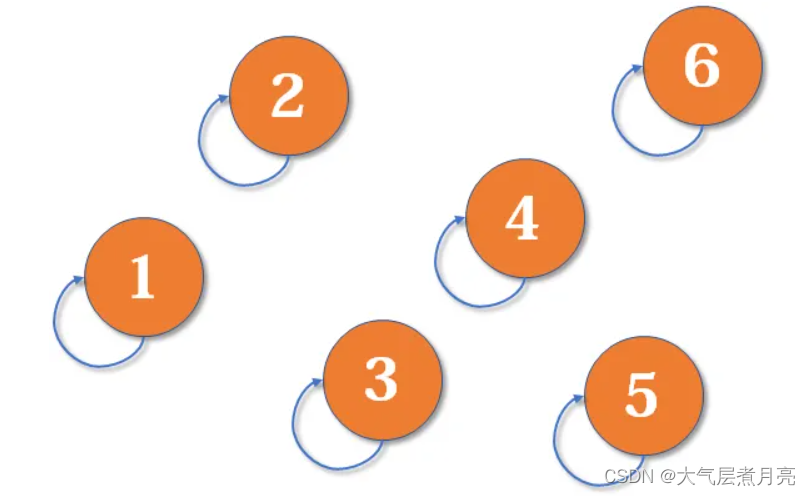
最开始,所有大侠各自为战。他们各自的帮主自然就是自己。(对于只有一个元素的集合,代表元素自然是唯一的那个元素)
现在1号和3号比武,假设1号赢了(这里具体谁赢暂时不重要),那么3号就认1号作帮主(合并1号和3号所在的集合,1号为代表元素)。

现在2号想和3号比武(合并3号和2号所在的集合),但3号表示,别跟我打,让我帮主来收拾你(合并代表元素)。不妨设这次又是1号赢了,那么2号也认1号做帮主。

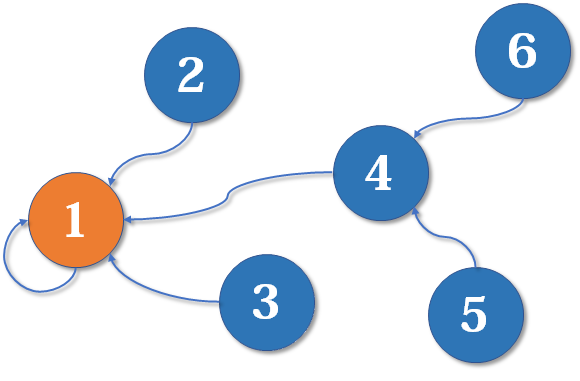
现在我们假设4、5、6号也进行了一番帮派合并,江湖局势变成下面这样:

现在假设2号想与6号比,跟刚刚说的一样,喊帮主1号和4号出来打一架(帮主真辛苦啊)。1号胜利后,4号认1号为帮主,当然他的手下也都是跟着投降了。
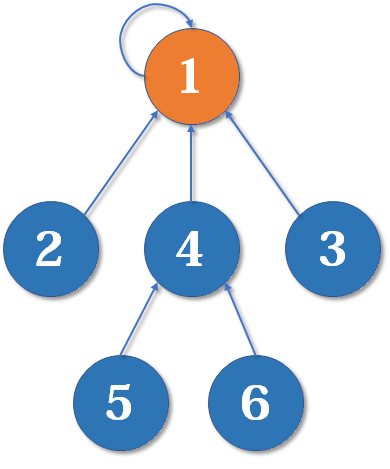
好了,比喻结束了。如果你有一点图论基础,相信你已经觉察到,这是一个树状的结构,要寻找集合的代表元素,只需要一层一层往上访问父节点(图中箭头所指的圆),直达树的根节点(图中橙色的圆)即可。根节点的父节点是它自己。我们可以直接把它画成一棵树:
用这种方法,我们可以写出最简单版本的并查集代码。
【python数据结构算法】并查集
题目1:合并集合
描述

要求
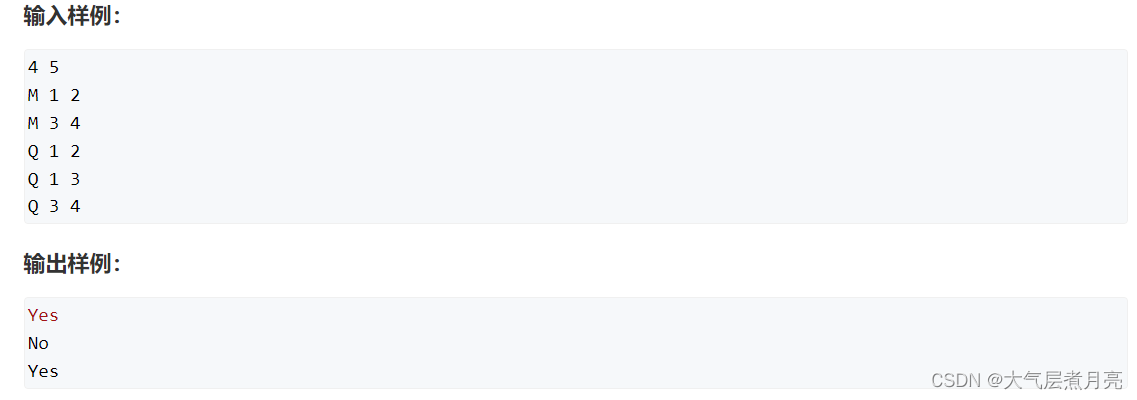
 样例
样例
复习模板
# dataset
def load_dataset():
n, m = map(int, input().split())
opts = []
nodes = []
for _ in range(m):
opt, u, v = input().split()
u = int(u)
v = int(v)
opts.append(opt)
nodes.append([u, v])
return n, m, opts, nodes
# model
def union_find_set(x):
if p[x] != x:
p[x] = union_find_set(p[x])
return p[x]
if __name__ == "__main__":
n, m, opts, nodes = load_dataset()
p = [n for n in range(n + 1)]
for i in range(m):
iter_opt = opts[i]
u, v = nodes[i]
eu = union_find_set(u)
ev = union_find_set(v)
if iter_opt == "M":
if eu != ev:
p[eu] = p[ev]
elif iter_opt == "Q":
if eu == ev:
print('Yes')
else:
print('No')
题目2: 连通块中点的数量
描述
 要求
要求

样例
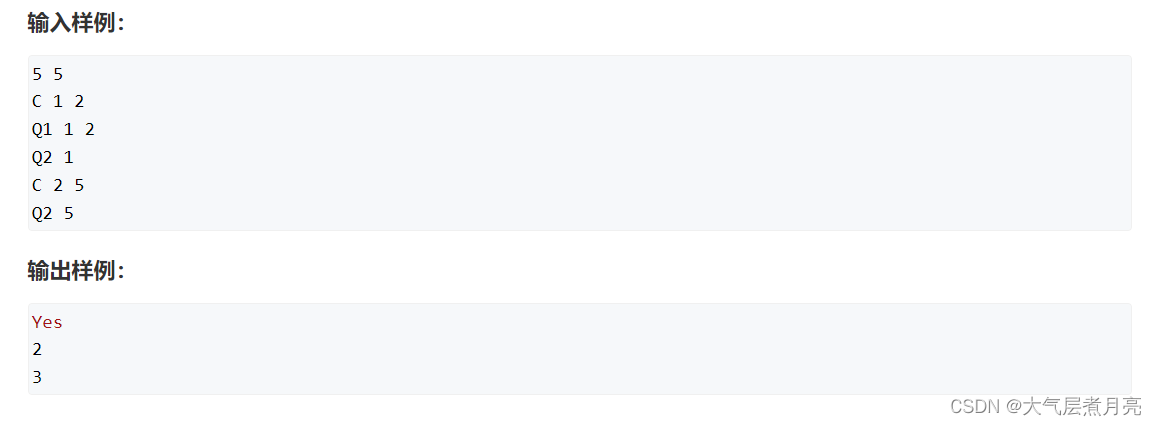
复习模板
def find(x):
if p[x] != x:
p[x] = find(p[x])
return p[x]
n, m = map(int, input().split())
p = [_ for _ in range(n+1)]
s = [1] * (n + 10)
Querry = []
for _ in range(m):
Querry.append(input().split())
for Q in Querry:
if Q[0] == 'C':
a, b = int(Q[1]), int(Q[2])
if find(a) != find(b):
s[find(b)] += s[find(a)] # 先加上点的数量 不然都合并了就失去原来被合并的值了因为a,b的Father都以一样了
p[find(a)] = find(b)
elif Q[0] == 'Q1':
a, b = int(Q[1]), int(Q[2])
if find(a) == find(b):
print("Yes")
else:
print("No")
else:
x = int(Q[1])
print(s[find(x)])