BV13g41157hK
认识复杂度和简单的排序算法
- 数组:取arr[i]:计算了一个偏移量是一个常数操作,算距离堆偏移量直接把地址拿出来,跟数据量无关
- 实际结构在地址中串着比较乱,跟数据量有关,list.get(i)不是一个常数操作
- 加减乘除是一个常数操作、位运算都是常数操作
- 选择排序:选一个最小值 放在1位置 再在1到最后选择最小放到1位置上 最后不断空间被挤压就成功达到了要求
计算了一下多少次常数操作,只需要取最高次项就为时间复杂度
当同时为O(n)的时候,用理论值无法估计,需要通过实际运行来判断常数项时间。
- 冒泡排序:12比较,23比较,34比较谁大谁往后移动一直放到最后,最后一个一定最大,一定是一个等差数列
- 空间复杂度:额外有限几个变量空间复杂度就是O(1),要开辟数组就是O(n)
- 异或运算:相同为0 不同为1。还可以理解为无进位相加 性质:0异或n=n n异或n=0 满足交换律和结合律和谁先谁后的顺序无关 超级牛逼的异或更改排序方法:a=a^b b=a^b a=a^b 运行一遍之后就可以实现a和b的交换(作用是可以不额外申请一个变量空间)


需要保证a和b的两块内存分属于不同的两部分 否则会被洗成0
题目:全偶数次的数组中有一两种数字为奇数次,找出其中奇数次的数

- 对于第一种情况直接全部异或数组中的每一个数字即可,原理是偶数次异或为0,奇数次异或为这个数
- 对于第二种情况需要全部异或一遍得到a^b
再提取出最右侧的1的写法:int rightone = a &(~a+1) 自己与上他自己的取反加一可以得到一个最右侧1其他全为0的数
只找到其中一位a和b不同再在数组中全部异或这一位为1或者这一位为0的数便可以找到a或者找到b
然后再用这个数字去异或a^b就得到了另外一个数
至于取哪一位就用上面提取最后测1的方法
插入排序
和数据量有关不像我们之前的冒泡排序和选择排序,无论数据量大小多少都要进行相同的操作数
先保证前0-1个有序 再保证0-2个有序 再保证.0-n个有序具体的保证方法是拿这个新的数和前面的数一一对比,找到最合适的位置插入进去
二分思想
在一个已经有序的数组中查找有没有一个数
拿这个数一次又一次的和我们数组的中值作对比并且更改长度
在一个有序数组中找到大于等于一个数的最左的位子
二分找中值 如果已经满足大于这个数取左区间继续二分
局部最小值问题
数组无序,任何两个临近的数不相等,局部最小就是同时小于左边一个元素,同时也小于右边一个元素,在这个数组中只找一个局部最小就可以stop。
左边下滑右边上升,中间一定存在某个低谷
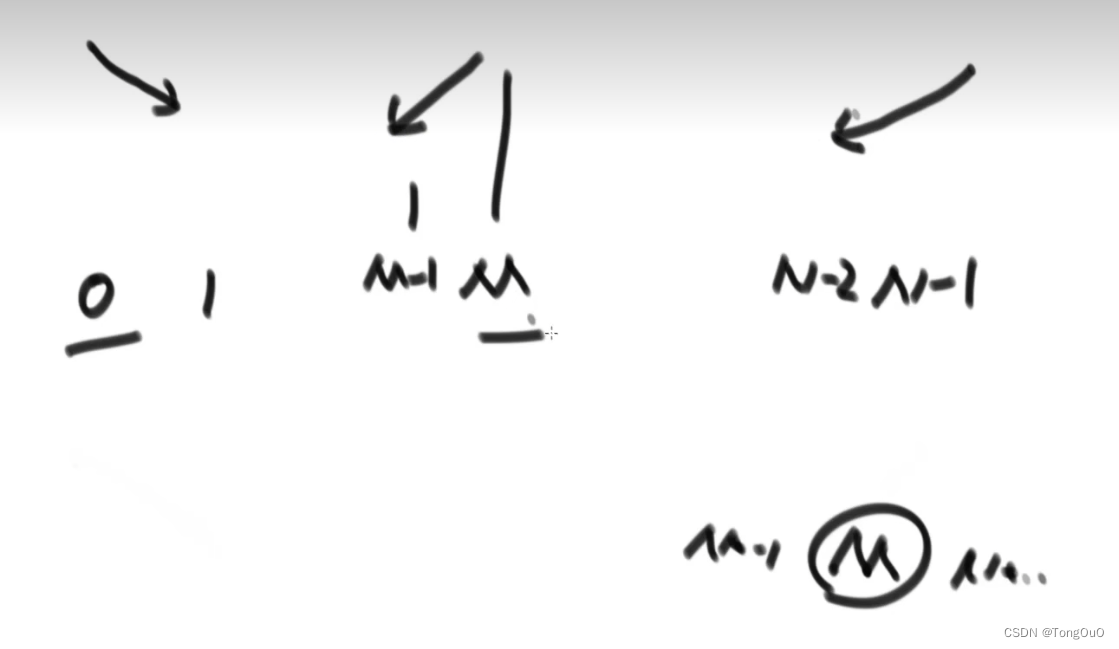
优化策略:1.数据状况特殊:是否有序呀~ 2.问题的标准特殊
具有排他性可以二分 比如左边可能有 右边一定没有
对数器
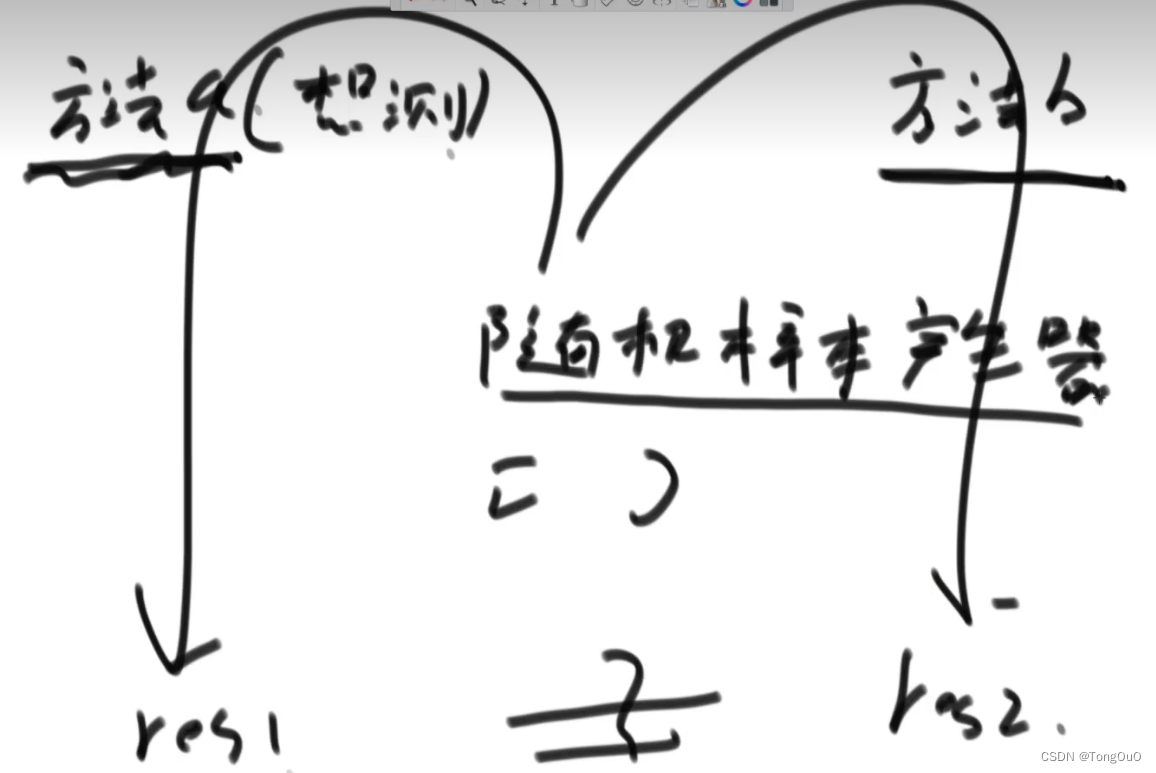
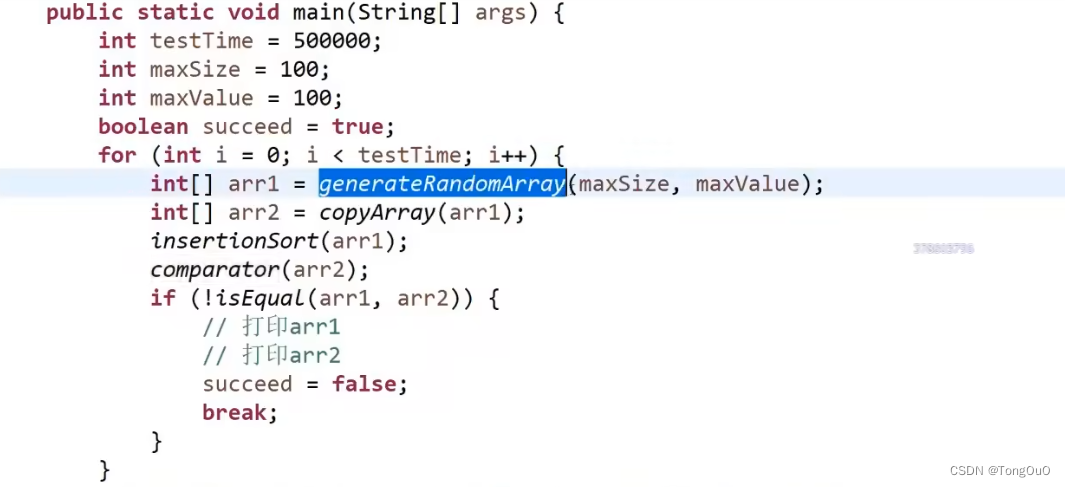
长度随机+值随机
认识O(nlogn)的排序
递归
- 计算中点的时候不用l+r除以2的原因是l+r有可能会溢出不行
使用mid=l+(r-l)/2使用l加一半 或者把除二改为右移一位 - 在一个数组中用递归方法求最大
L=R时候return数组中这个数,否则划分左右两个子区间,分别再次进行这个函数
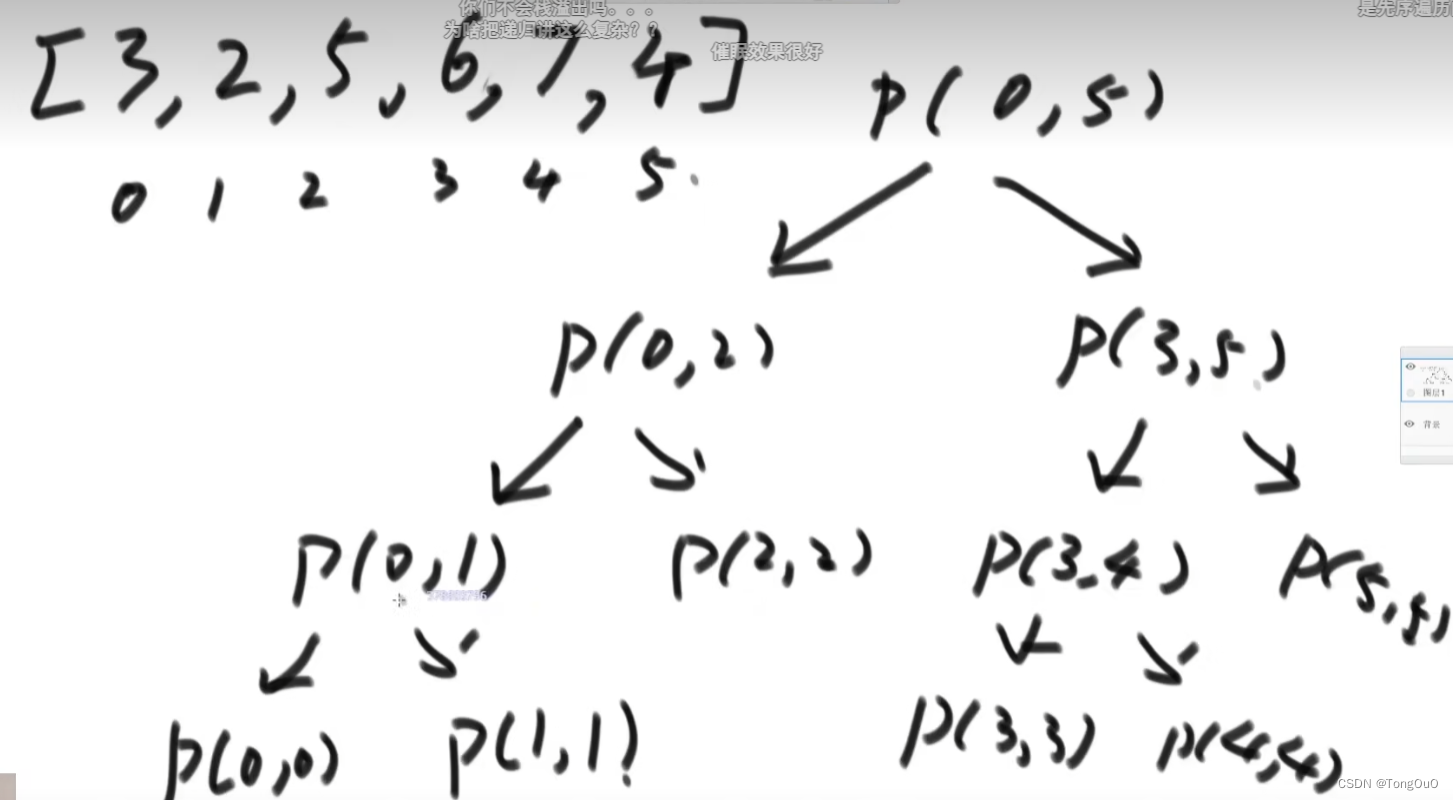
是一个利用栈计算所有树的节点的过程
Master公式

其中T(N/b)为调用子问题时候规模是否等量,a表示子问题在等量的同时被调用了多少次,O(n^d)为除了子过程外剩下过程的时间复杂度,子问题等规模的递归就可以用master公式直接求时间复杂度
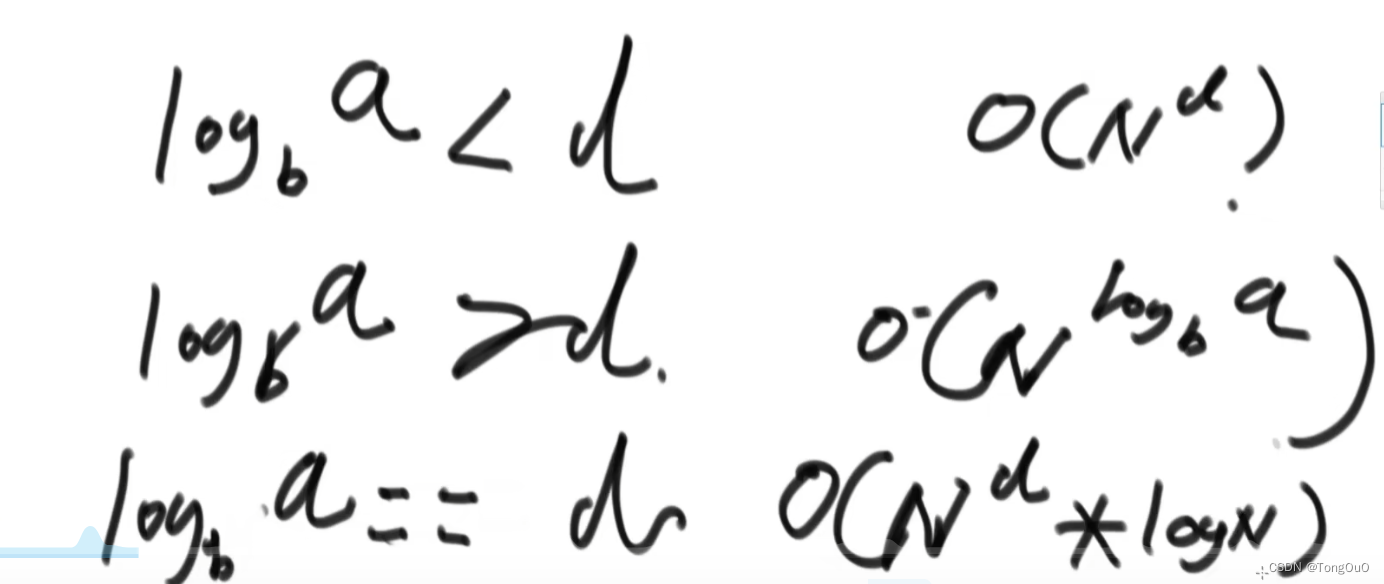
归并排序 MergeSort
为什么时间复杂度会变成nlogn,我们的比较没有被浪费,变成了一个有效的部分归并到更大的部分中去,相比于插入,冒泡排序的效率更高

小和问题(归并扩展)

- 暴力破解法:每个位置i都进行往前的计算暴力法可以得到O(n方)
- O(nlogn)方法:深度改写mergesort,和mergesort的唯一区别的每次排序的时候计算小和,并且在左右相等时候先把右边放入数组
- 逆序对问题(和刚才的小和基本上一样),变成了求左边有多少个比此数大
快速排序(荷兰国旗问题)

不要求排序,只用把小于num的放左边,大于num的放右边
解法:

实质上是动态的修改小于等于区,让小于等于区推着大于区往后走
荷兰国旗问题
让小于的在左边 中间的在中间 右边的在右边
解法:

i和大于区域撞上的时候停止
快速排序
快速排1.0:利用了小于等于放左边大于等于放右边,一次搞定一个数
快速排序2.0:利用了小于放左边,等于放中间,大于放右边,一次可以搞定等于的一批数,荷兰国旗问题
每次取最后一个数来划分
不管是快排1.0还是快排2.0时间复杂度都是O(n方),因为可以举出最差的例子,已经有序的数组每次partation都是一样的,划分值打的很偏产生最差情况
快排3.0版本:为了解决选排序点选偏的问题,我们随机选一个值作为比较值,因为是纯随机,所以数学期望之下也是nlogn的算法
计数排序
统计员工年龄数据,把相同年龄的存到一张表上,只需要根据表上的先后顺序就可以确定根据年龄数据进行排序,时间复杂度On
基数排序
桶排序
数据结构可以是任何东西可以是链表可以是数组或者任何东西
把数字都补成三位,根据个位数字放到对应的桶里面去,根据从小到右边倒出来,再根据十位全部倒一遍,再根据百位倒一遍,最后所有数组倒出来就全部排好序了,这里我们用队列好一点,高位数字优先级最高,从个位开始排,依次进桶,和计数排序的区别是只要是十进制就划出来是个队列就行了,也是基于数据特殊性的非比较算法
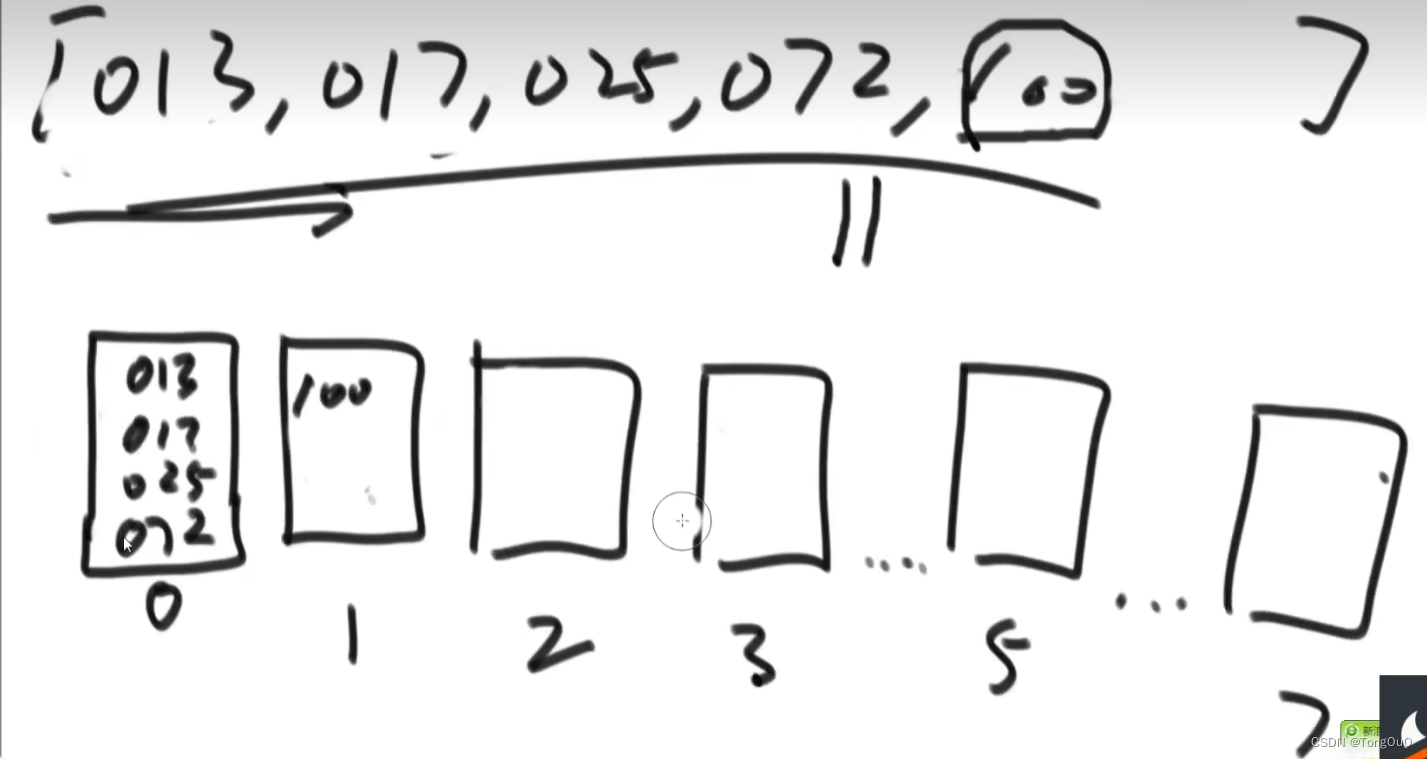
代码具体实现细节:利用了前缀和确定目标数据在辅助数组中的位置完成入桶和出桶的操作,根据入桶所以出桶的时候应该从右到左进行出桶
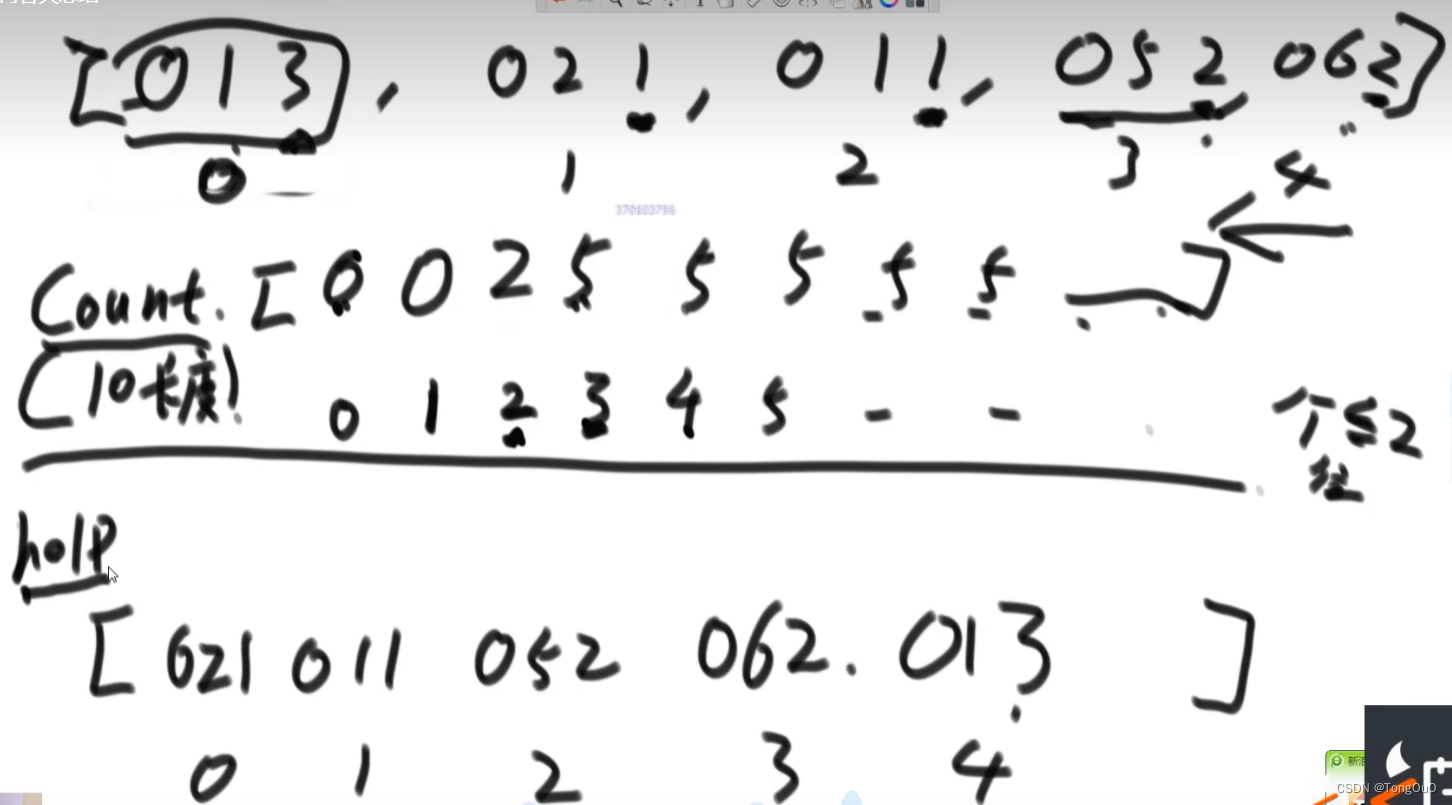
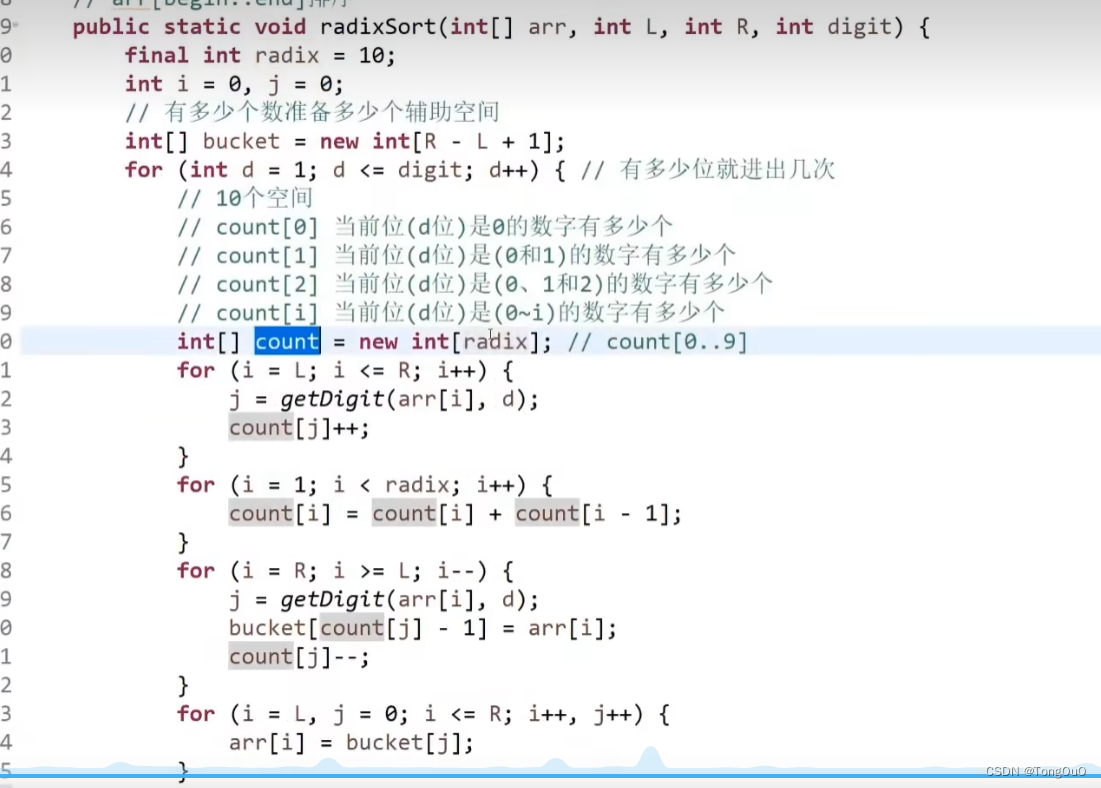
count为各位数字小于cout的有多少个,填在count减1的位置上面之后自身词频减一
代码实现:
排序算法稳定性以及总结
稳定性

- 稳定性是指值相同的数字在排序完之后能否保证顺序不变
- 值相同的那些在排完序后仍能保持相对次序一样
- 对于基础类型没什么用,对于非基础类型比较有用
例如说先排年龄再排班级如果稳定的话就可以按照顺序排序了班级内的所有年龄人数
选择排序
做不到稳定
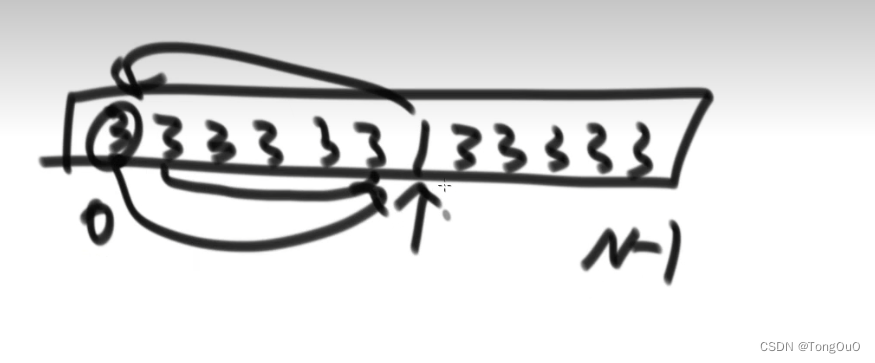 在全是3的数组中选一个移到前面就会破坏掉原有的3的结构
在全是3的数组中选一个移到前面就会破坏掉原有的3的结构
冒泡排序
冒泡排序可以,一直交换,相等的时候不换就可以保持稳定性
可以实现成稳定性
插入排序
可以实现稳定性,让每次右边的数大于等于左边的时候就停在右边,关键在于怎么处理相等的时候
归并排序
左侧和右侧相等我时候先考虑左边的就可以做到稳定了
所以也可以
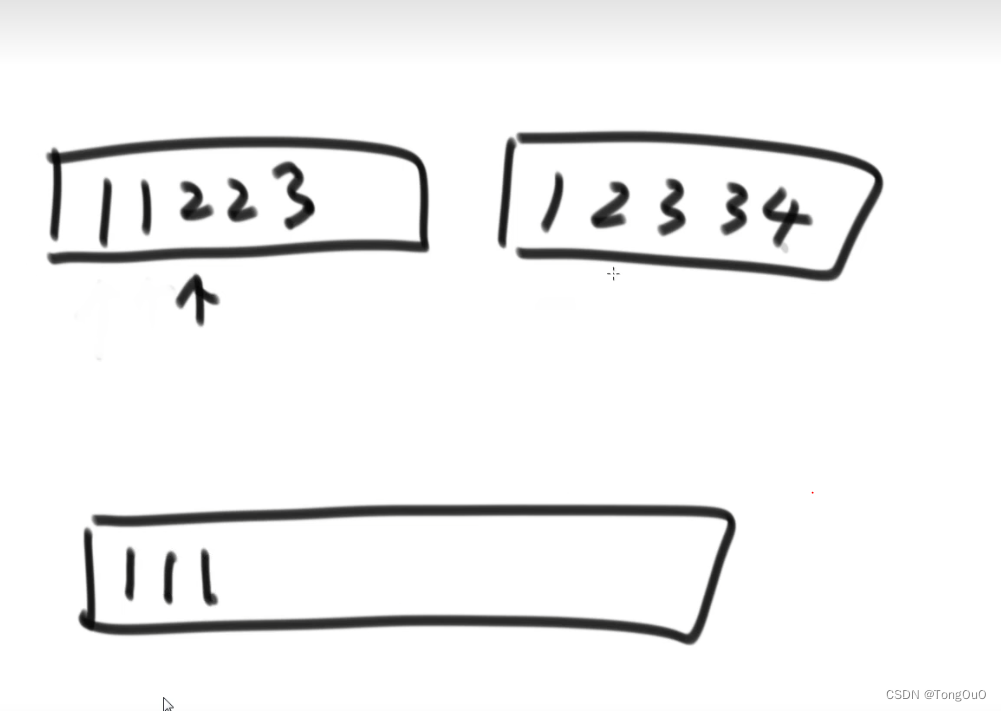
小和问题每次取右边的但同时会失去稳定性
快速排序
在partation时候做不到
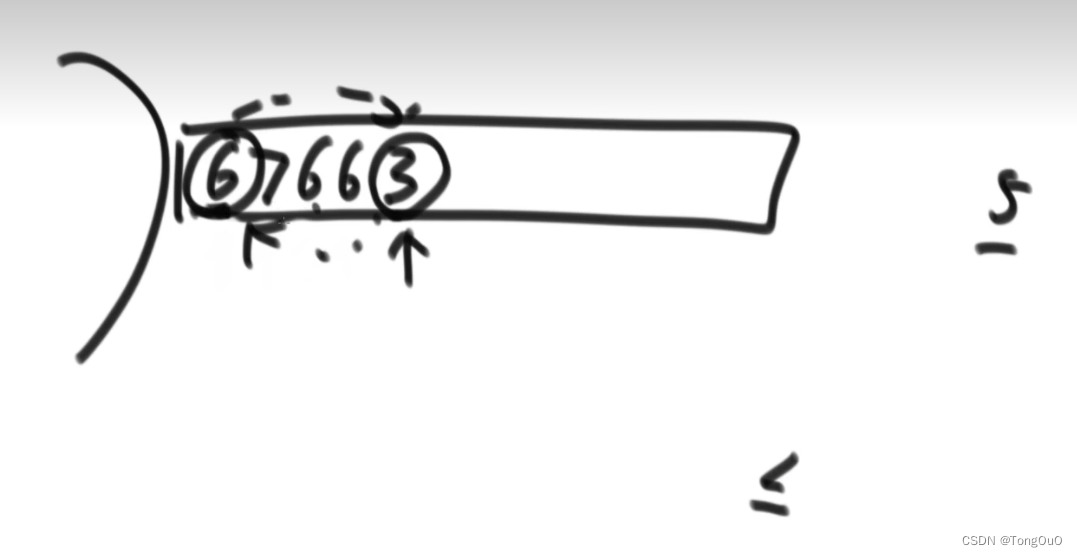
堆排序
在生成大根堆的时候就无法做到稳定性,在插入较大值到完全二叉树的左枝的时候就可以
计数排序和基数排序
都能做到稳定性,先入桶和先出通的东西都能做到稳定和比较无关都能很轻松做到稳定性
总结

哈希表和有序表
哈希表:C++里面是UnsortedMap UnOrderedMap
Set和Map的区别是set只有key map是有key有value
hashmap中put即使放入又是更新
remove时候同时移除key和value
增删改查和数据量没关系都是常数的时间复杂度,比较大的常数,比数组寻址大,面对基础类型按照值来传递,所占空间为这个数据本身所存在的空间
而要是自定义类型的话在哈希表中不会传入值类型,而是传入一个地址,这个地址是8个字节,指向new出来的数据结构,直接把内存地址做一个拷贝,内存占用只是这个东西的地址大小,
不会影响哈希表内存,只会拷贝地址进来
有序表:orderedset orderedmap

只有key是set结构,只有
哈希表无序 有序表有序 可以根据有序有新的功能
因为有序还可以有新的api,返回最大最小,可以知道小于8中最小的,大于8中离8最近的,红黑树AVL树sb树跳表都可以实现,底层实现不同,性能O(logn)的结构,同样道理有序表,有序表基础类型必须按值传递,放入非基础类型必须提供比较器,按引用传递,传入地址。
链表
单链表和双链表

反转链表和双向链表问题

如果有换头的问题就要有返回值,没有换头的问题就void没有返回值
打印链表的公共部分


链表题解题技巧:两个指针,谁指向的值小谁移动,相等的时候共同移动

判断是否为回文结构

笔试的做法:生成一个栈,另一个指针便利线性表,同时比对出栈,如果相同则True
也可以把右侧部分折过来,就是只有右半边进栈,左半边不进栈,实现方法是快慢指针法,快指针F,慢指针S,快指针走完,就可以把慢指针之后的所有东西放到栈里面去,根据实际题目需求定制快慢指针的走速,通过自己Coding的方式把代码写熟了,和算法无关
使得空间复杂度可以为O(1)的方法就是让中间位指向的下一个为null,左右两边,后边朝前面指向一步一步往前推进,相同最后指向中点停
最后的coding每一个条件怎么写是要考虑各个情况然后写出来的
单链表根据某值划分为左边小中间等于右边大的形式

笔试做法:把每个点都放进数组,然后在数组中玩partation,最后还原成列表
partation后数组无法保证相对顺序不变 而用链表作partation的时候反而可以保证相对顺序
难点在于各种条件的情况要讨论清楚边界
一定是一步一步写过很多代码发现逻辑可以化简扣成这样子的
复制含有随机指针节点的链表

两个单链表相交的一系列问题

判断有环无环:
- 哈希表法:hashset,每次存入新的地址,如果已经存在则有环
- 快慢指针法,只要一个指针比另一个指针跑得快,快指针总会追上慢指针,然后将快指针归零,并且将其调整为每次只走一步,最后相遇的地点即为环开始的点(不用额外空间的做法而用数据结构的做法)
正式过程
- 都没环的情况下
只要两个之间有交叉,那么之后的一定会有一连串连续的节点或无节点
两个节点相交部分如果最后一个节点都相同,才证明说前面有可能存在相交区间
1.判断最后节点是否相同,如果不相同则证明之前完全没有过交集可以直接返回null
2.如果相同说明之前肯定有交集,这个时候长的链表先走差值步,然后再一起走走到第一个相同的节点则为第一个相交的节点 - 一个有环,一个无环不可能相交,可以脑补出相应的图,但是最后在链表结构中都不能实现
- 两个链表都有环(三种情况)
先要判断两个链表是否在环前节点即loop之前就完成了,如果已经完成说明就是情况二,再根据以上差值方法计算第一个相交的节点,如果没有完成,再判断再循环中有没有遇到另外一个loopnode,如果有遇到则说明情况3返回相交节点否则为情况一
二叉树及其相关内容
二叉树的定义概念
重点:二叉树递归跟非递归的遍历

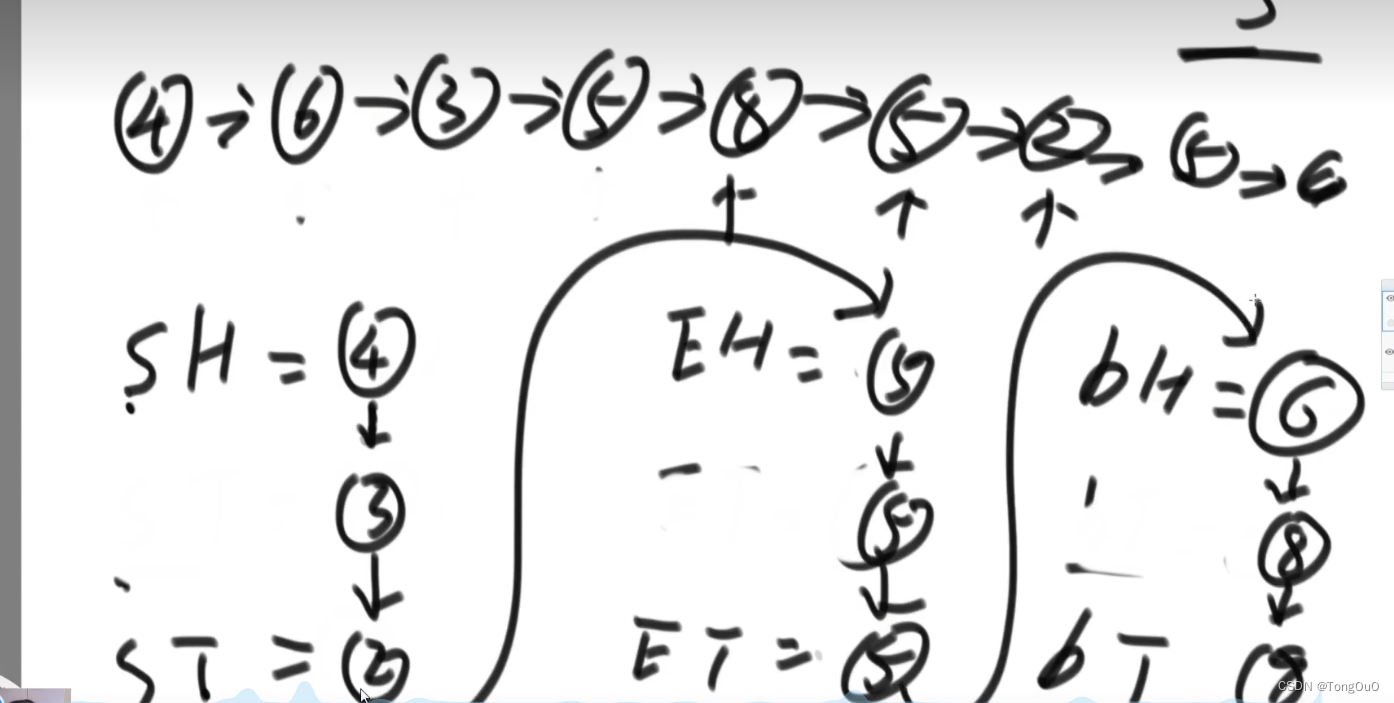
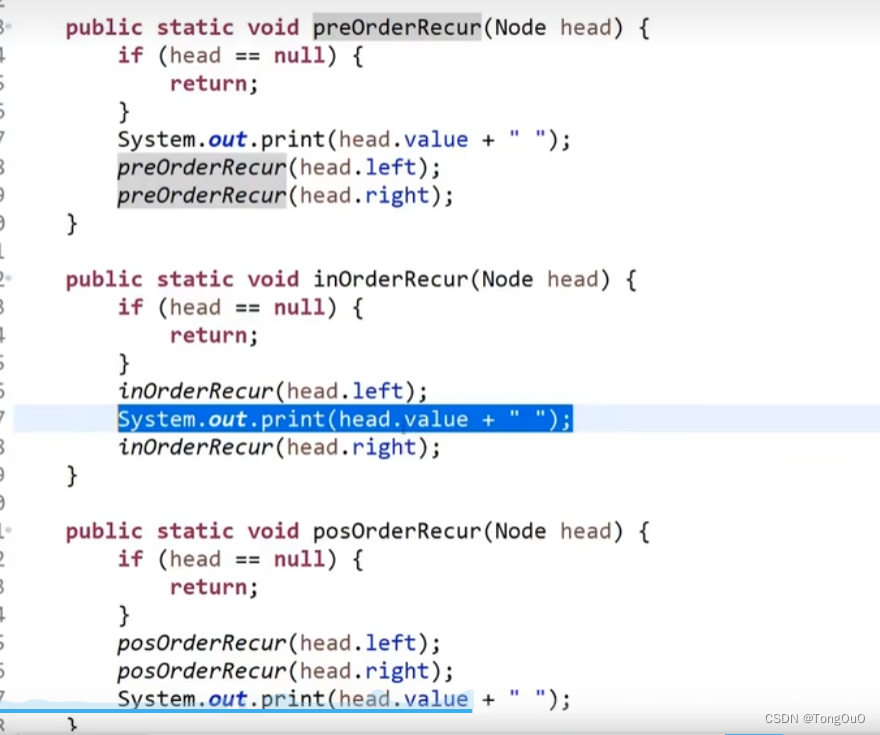
二叉树的先序、中序、后序遍历

递归代码实现
- 先序:第一次到达时取到值本值
- 中序:第二次到达
- 后序:第三次到达时候取值
非递归实现
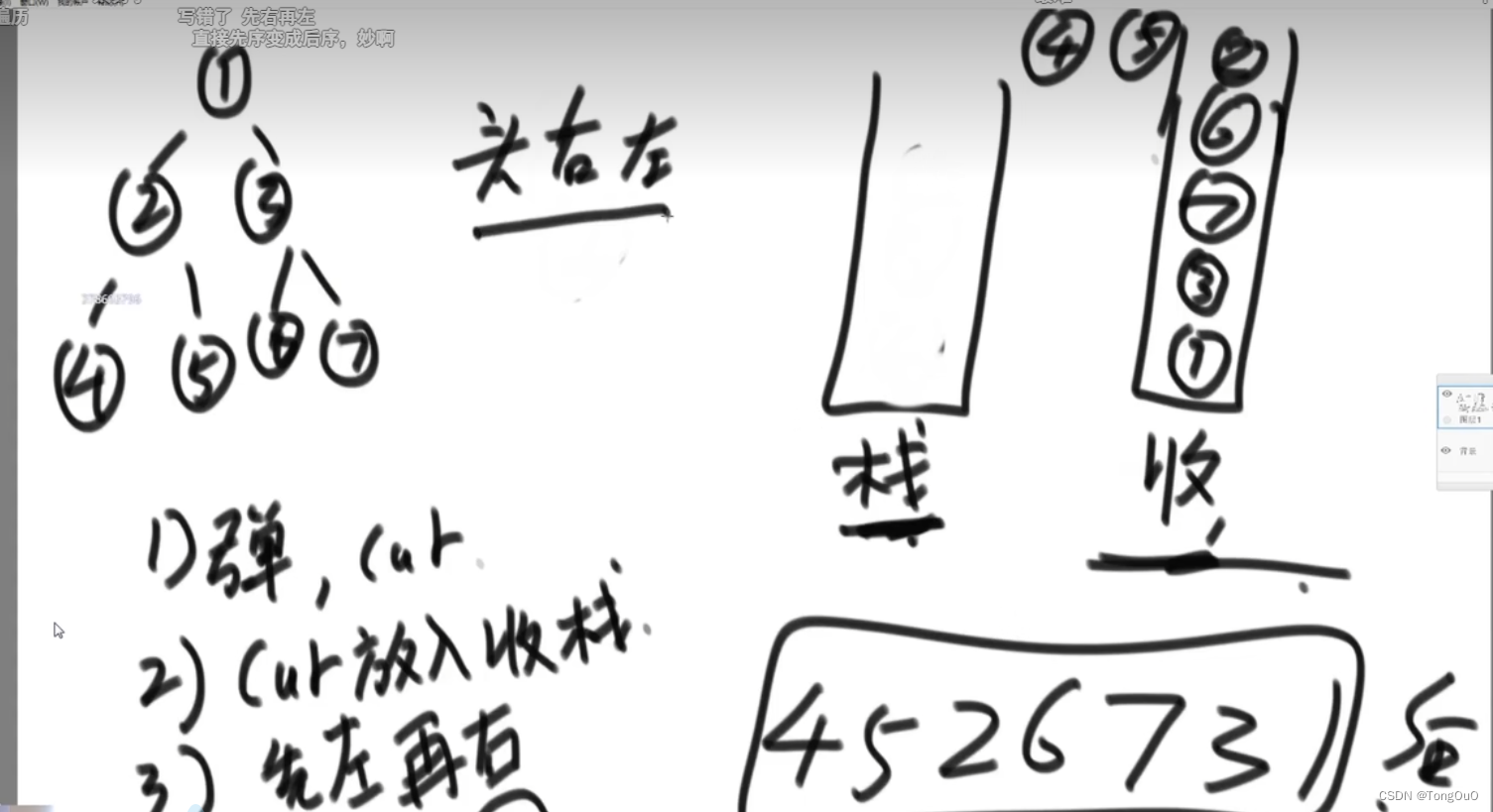
- 先序遍历:每次弹出节点后先压入右节点再压入左边节点重复操作
栈不为空的情况下每次pop一个节点出来,然后如果有的话先将右枝节点压入再将左枝节点压入栈中
- 后序遍历:和先序遍历的唯一不同是增加多了一个栈,每次pop出来放到那个栈当中,然后先压入左枝再压入右枝,最后从辅助栈中pop出每一个就是后序遍历
中序遍历:永远先左再头,再对右节点重复操作,

求一颗二叉树的宽度
介绍了一种看别人代码的思想,不要怕麻烦,别人设置多少变量我们就设变量,在纸上一点一点扣,一点一点还原别人怎么写的,虽然慢但是能理解
宽度优先遍历
利用队列的思想,从同一层将左右分别压入队列,出队列的时候再dequeue每一个并且压入左和右
在宽度优先遍历的同时,利用一张额外的哈希表存储节点和其所在层数,逐层统计求和计算节点数,用max取到最大节点数
不用哈希表的方法:用curEnd和nextEnd分别存储当前行尾节点和下一行尾节点,赋值max,cur=next,next=null
深度优先遍历
就是前序遍历
1.快速排序
算法思想
1.随便取一个值一般是L【0】 L【len-1】or 随机
2.保证左边都小于右边
- 直接暴力 1.将小于三的放到数组 2.再将数组小于3的放进来 需要两遍 一遍出一遍进
- 双指针 取到一大一小之后swap 只用走一遍
3.递归处理
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j)
{
do i ++ ; while (q[i] < x);
do j -- ; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j), quick_sort(q, j + 1, r);
}
#Python版本
def QuickSort( nums, l, r):
if(l >= r):
return nums;
i = l - 1
j = r + 1
mid = nums[(l + r) >> 1]
while (i < j):
i = i + 1
while (nums[i] < mid):
i = i + 1
j = j - 1
while (nums[j] > mid):
j = j - 1
if (i < j):
nums[i], nums[j] = nums[j], nums[i]
QuickSort(nums, l, j)
QuickSort( nums, j + 1, r)
2.归并排序
1.确定分界点为中间
2.递归保证左边有序保证右边有序
3.合二为一
归并排序算法模板 —— 模板题 AcWing 787. 归并排序
void merge_sort(int q[], int l, int r)
{
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] < q[j]) tmp[k ++ ] = q[i ++ ];
else tmp[k ++ ] = q[j ++ ];
while (i <= mid) tmp[k ++ ] = q[i ++ ];
while (j <= r) tmp[k ++ ] = q[j ++ ];
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}
def MergeSort(nums,l,r):
if(l >= r):
return
mid = (l + r)>>1
MergeSort(nums,l,mid)
MergeSort(nums,mid + 1, r)
count = 0
temp = []
i = l
j = mid + 1
while((j <= r) & (i <= mid)):
if(nums[i] < nums[j]):
temp.append(nums[i])
i = i + 1
else:
temp.append(nums[j])
j = j + 1
while(i <= mid):
temp.append(nums[i])
i = i + 1
while(j <= r):
temp.append(nums[j])
j = j + 1
tempindex = l
for index in range(0,r-l+1):
nums[tempindex] = temp[index]
tempindex = tempindex + 1
3.整数二分
1.确定边界
2.假定一个中值
3.根据实际情况的check判断取左还是取右
4.如果l=mid的情况 mid为l+r+1/2
二分是取最近的
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
MID = L + R / 2
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l;
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
//MID = L + R + 1/ 2
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
def search(self, nums, target):
"""
:type nums: List[int] :type target: int :rtype: int
""" l = 0
r = len(nums) - 1
while(l < r):
mid = (l + r + 1) >> 1
if(target >= nums[mid]):
l = mid
else:
r = mid - 1
if(target != nums[l]):
print(-1)
return -1
else:
print(l)
return l
浮点二分
比整数二分更简单 并且无需处理边界
浮点数二分算法模板 —— 模板题 AcWing 790. 数的三次方根
bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-6; // eps 表示精度,取决于题目对精度的要求
while (r - l > eps)
{
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
return l;
}
class Solution(object):
def mySqrt(self,x):
l = 0
r = float(x)
ans = 50
for i in range(1,ans+1):
mid = (l + r) / 2
if ((mid * mid) >= x):
r = mid
else:
l = mid
print(int(r))
return int(r)
单调栈
def nextGreaterElement(nums1, nums2):
tt = 0
q=[]
ansStack=[]
ans = []
for i in range(len(nums2) - 1 , -1, -1):
while(tt and q[tt - 1] <= nums2[i]):
tt = tt - 1
if(tt):
ansStack.insert(0, q[tt - 1])
else:
ansStack.insert(0, -1)
q.insert(tt,nums2[i])
tt = tt + 1
for value in nums1:
ans.append(ansStack[nums2.index(value)])
return ans
单调队列滑动窗口
tt = 0
hh = 0
q = []
ans = []
for i in range(0, len(nums)):
while (tt - hh > 0 and q[hh] <= i - k):
hh = hh + 1
while (tt - hh > 0 and nums[i] >= nums[q[tt - 1]]):
tt = tt - 1
if (tt <= len(q) - 1):
q[tt] = i
tt = tt + 1
else:
q.append(i)
tt = tt + 1
if (i >= k - 1):
ans.append(nums[q[hh]])
return ans
无重复字符的最长子串
队列维护 + 哈希表集合查询 + 注意str为空和 str为空格的情况 + cnt计算注意
求循环节特异性使用此个KMP
def lengthOfLongestSubstring(self, s):
if not s: return 0
dic = set()
hh = 0
tt = 0
cnt = 1
q = []
for i in range(0, len(s)):
if (s[i] in dic):
while (tt - hh > 0 and q[hh] != s[i]):
dic.remove(q[hh])
hh = hh + 1
if (tt - hh > 0 and q[hh] == s[i]):
hh = hh + 1
else:
dic.add(s[i])
q.append(s[i])
tt = tt + 1
cnt = max(cnt, tt - hh)
return cnt
trie树处理
# leetcode submit region begin(Prohibit modification and deletion)
class Trie(object):
def __init__(self):
self.index = 0
self.tree = []
self.cnt = {}
def insert(self, word):
j = 0
for i in range(0, len(word)):
cha = ord(word[i]) - ord("a")
if (j >= len(self.tree) or (cha not in self.tree[j])):
self.index = self.index + 1
self.tree.append({})
self.tree[j][cha] = self.index
j = self.index
else:
j = self.tree[j][cha]
if (j in self.cnt):
self.cnt[j] = self.cnt[j] + 1
else:
self.cnt[j] = 1
def search(self, word):
j = 0
for i in range(0, len(word)):
cha = ord(word[i]) - ord("a")
if (j >= len(self.tree) or (cha not in self.tree[j])):
return False
j = self.tree[j][cha]
if (j in self.cnt):
return True
else:
return False
def startsWith(self, prefix):
j = 0
for i in range(0, len(prefix)):
cha = ord(prefix[i]) - ord("a")
if (j >= len(self.tree) or (cha not in self.tree[j])):
return False
temp = self.tree[j]
j = self.tree[j][cha]
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
# leetcode submit region end(Prohibit modification and deletion)
哈希表
0x3f3f3f3f通常同来表达无穷大
因为memset 0x3f可以作为cpp中的每一位
0和-1也是同理 memset 0 和memset -1即可
0每一位是0000 -1每一位是1111
合在一起也是一样
BFS
while(队列不空)
{
取队头
扩展队列
}
DFS
找顺序 + 回溯 + 恢复现场
代码顺序:终止条件->剪枝return->当前层的遍历顺序
质数
试除法判断一个数是否为质数
for i i<=n/i i++
用i小于等于n/i
不要用平方或者开根号
判断i是否可以被整除 即看看余数是否为0
DP
背包问题
不一定要装满背包
one.01背包
每个物品只能用1次 N个物品 总体V 单个vi 每个价值wi
![[Pasted image 20230307164026.png]]
two.完全背包
每件物品有无限个
![[Pasted image 20230307183046.png]]
多重背包
每个物品最多有si个,朴素版+优化版
朴素版和完全背包问题基本一致
分组背包问题
N组,每一组有若干种,每一组选一个
![[Pasted image 20230309164206.png]]
线性DP
区间DP
![[Pasted image 20230309164240.png]]
计数类DP
数位统计DP
状态压缩DP
树形DP
记忆化搜索
中心扩展
力扣004 中心扩展算法
二分
双有序数组二分
注意二分的时候:
把握确定性的事物和升维是非常重要的
括号匹配
![[Pasted image 20230309215831.png]]
长版短板双指针
对于长板来说往内缩来说可能一定减小最大值
对于短板来说往内缩可能增大也可能减少
中心扩展算法
同时传入i和i-1来做奇数偶数判断,分别向左向右走到边界,并记录最左和最右
def longestPalindrome(s: str) -> str:
if(len(s)<=1):
return s
def FindMaxLength(s,l,r):
while(s[l] == s[r]):
l -=1
r +=1
if(r == len(s) or l < 0):
l += 1
r -= 1
return [l,r]
l += 1
r -= 1
return [l,r]
mymax = float("-inf")
curR = 0
curL = 0
for i in range(1,len(s)):
a1 = FindMaxLength(s,i,i)
if(a1[1]-a1[0]+1 > mymax):
curL = a1[0]
curR =a1[1]
mymax = a1[1]-a1[0]+1
if(s[i] == s[i-1]):
a2 = FindMaxLength(s, i-1, i)
if (a2[1] - a2[0] + 1 > mymax):
curL = a2[0]
curR = a2[1]
mymax = a2[1] - a2[0] + 1
return s[curL:curR + 1]
三数之和-排序加三指针
先对原数组排序
双指针左置于i
右置于n-1
往内走
对于原数组循环的时候
对于i>0的i跳过
并且如果i重复了i也往下跳一个
左右指针如果重复了上一个也往下跳一个
n = len(nums)
if(n < 3):
return []
ans = []
nums.sort()
for i in range(0,n):
if(nums[i] > 0):
return ans
if(i>=1 and nums[i] == nums[i-1]):
continue
left = i + 1
right = n - 1
while(left < right):
if(left - 1 !=i and nums[left] == nums[left - 1]):
left += 1
continue
if(right+1 < n and nums[right] == nums[right+1]):
right -= 1
continue
if (nums[i] + nums[left] + nums[right] == 0):
ans.append([nums[i], nums[left], nums[right]])
right -= 1
left += 1
continue
if(nums[left] + nums[right] > -nums[i]):
right -= 1
else:
left += 1
return ans
Nim游戏 异或和
有V 堆石子。 A B 两个人轮流拿, A先拿。每次只能从一堆中取若工个,可将一堆全取走,但不可不取,拿到最后 1 颗石子的人获胜。假设 A B 都非常聪明,拿石子的过程中不会出现失误。给出 V 及每堆石子的数量,问最后谁能赢得比赛。 例如: 3 堆石子每堆1颗。A拿1颗,B拿 1颗,此时还剩 1堆,所以 A 可以拿到最后 1颗石子。请写个程序算出谁会赢
这是一个经典的博弈问题,也被称为“Nim 游戏”。解决这个问题需要用到“异或和”的概念。具体来说,对于每堆石子的数量,将它们的数量两两进行异或运算,得到一个结果,称为“异或和”。
如果所有的异或和都等于 0,那么先手必败;否则,先手必胜。
证明如下:
假设所有的异或和都等于 0,考虑先手如何取石子。由于每次取走的石子数量一定小于等于当前堆的石子数量,所以取走后各个堆的石子数量的异或和仍然为 0。因此,每次先手取完石子后,两个人面对的局面仍然满足所有的异或和等于 0。这样一直进行下去,直到最后只剩下一颗石子时,后手获胜。
现在假设存在某个异或和不等于 0。考虑先手如何取石子。由于异或和不等于 0,所以至少存在一个二进制位,在所有堆的该位上,石子的数量的异或和不为 0。那么先手可以取走某一堆石子,使得这一堆石子在该二进制位上的值为 0。这样,各个堆的石子数量的异或和仍然不为 0。然后,后手必须在这一位上取走一些石子,使得各个堆的石子数量的异或和为 0。这样,两个人面对的局面仍然满足存在某个异或和不为 0。这样一直进行下去,直到最后只剩下一颗石子时,先手获胜。
根据以上结论,可以编写如下的程序:
pythonCopy code
def nim_game(stones): xor_sum = 0 for stone in stones: xor_sum ^= stone if xor_sum == 0: return "B wins" else: return "A wins"
其中,stones 是一个列表,表示每堆石子的数量。函数返回值是一个字符串,表示最后谁能赢得比赛。