
最近几场周赛好像都是过T4没过T3,有点离谱。。
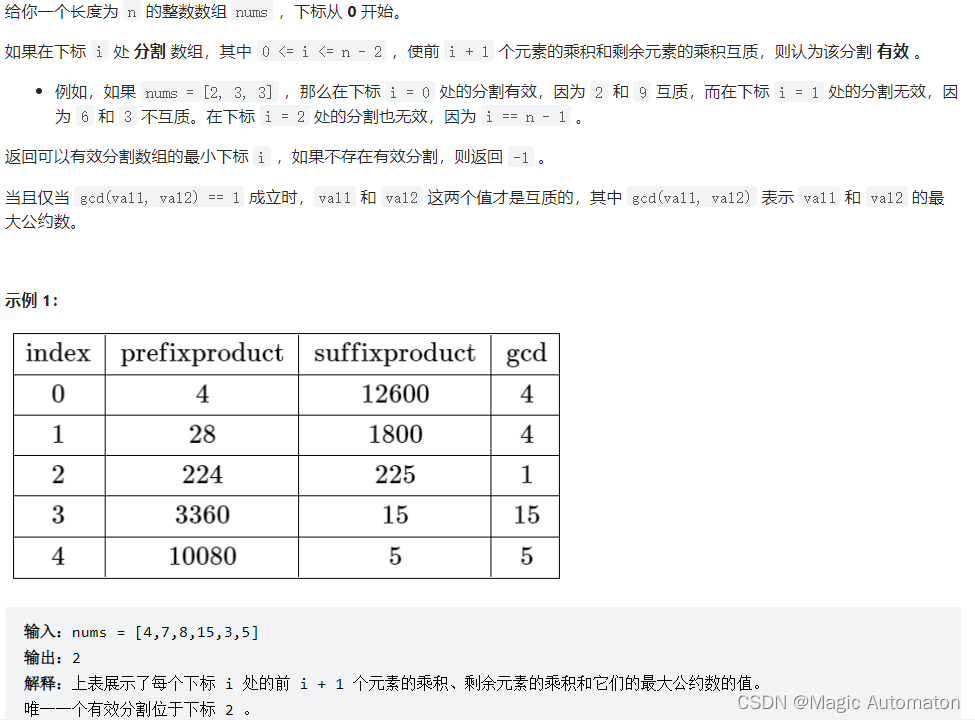
简单来说,题意就是要将数组分为两部分,两部分的积互质。
思路很容易想:分割点不能在两个不互质的数之间。
一种简单的暴力解法是枚举每个数,然后确定与它不互质的最后一个数(为了方便命名为配对数)的位置。如果前k个数的配对数都在前k个数之内,那么就说明将数组在这个位置拆开得到的两个数组是满足条件的。
class Solution {
public:
int findValidSplit(vector<int>& nums) {
int sz=nums.size();
int ans=0;
int checked=0;
while(true)
{
for(int i=ans+1;i<sz;++i)
if(gcd(nums[i],nums[checked])>1)
ans=i;
if(ans==sz-1)
return -1;
++checked;
if(checked>ans)
break;
}
return ans;
}
};
这个算法是 O ( n 2 l o g ( m a x ( n u m ) ) ) O(n^2log(max(num))) O(n2log(max(num)))的,会超时。
上述算法中主要的时间复杂度在于用了 n 2 n^2 n2的时间进行枚举,现在考虑如何更快地完成这个任务。
首先,我们其实并不关心两个数的gcd是什么:只要两个数有相同的因数,不管它是不是最大公因数,都可以知道两个数不是互质的。
其次,我们其实也不关心任两个数之间的互质关系:假如a,b,c三个数相互都不互质,那么当判断出c与a不互质之后,就没必要判断c与b的互质关系。
根据第一点,我们可以考虑处理出每个数的质因数,然后根据每个数拥有的质因数来判断互质关系。
但如果仍然枚举每对数,整体的复杂度不降反升,来到了 O ( n 2 m a x ( n u m ) ) O(n^2\sqrt{max(num)}) O(n2max(num)).
根据第二点,我们不需要枚举每对数,因为很多数对是没必要判断的:假如现在已经有了每个数的质因数信息,那么对于第k个数的第i个质因数,只需要找到最早的出现过i的数即可。
但是不对,这样一来似乎并没有影响整体的复杂度。
这是因为我们在寻找这些数时,仍然是用了 O ( n ) O(n) O(n)的复杂度。为了更快找到这些数,用一个哈希表来存每个质因数第一次出现的位置即可。这样复杂度就降了 n n n。
class Solution {
public:
int findValidSplit(vector<int>& nums) {
unordered_map<int,int> appear;
int sz=nums.size();
int rightmost[sz];
memset(rightmost,0,sizeof(rightmost));
for(int i=0;i<sz;++i)
{
int x=nums[i];
for(int p=2;p*p<=nums[i];++p)
{
if(x%p)
continue;
while(!(x%p))x/=p;
if(!appear.count(p))
{
appear[p]=i;
}
rightmost[appear[p]]=i;
}
if(x>1)
{
if(!appear.count(x))
appear[x]=i;
rightmost[appear[x]]=i;
}
}
int rm=0;
for(int i=0;i<sz;++i)
{
if(i>rm)
return rm;
rm=max(rm,rightmost[i]);
}
return -1;
}
};