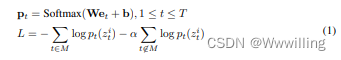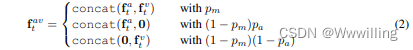我们的研究建立在 Audio HuBERT (Hsu et al., 2021a) 的基础上,它是一个用于语音和音频的自我监督学习框架。它在两个步骤之间交替:特征聚类和掩码预测。在第一步中,将离散潜变量模型(例如,k-means)应用于一系列声学帧 A 1 : T A_{1:T} A1:T,从而产生一系列帧级分配 z 1 : T a z^a_{ 1:T} z1:Ta。基于信号处理的声学特征集群,例如梅尔频率倒谱系数 (MFCC),与语音输入的固有声学单元表现出非平凡的相关性。使用 ( A 1 : T , z 1 : T a ) (A_{1:T} , z^a_{ 1:T} ) (A1:T,z1:Ta) 对,第二步通过最小化掩码预测损失来学习新的特征表示,类似于 BERT 中的掩码语言建模 (Devlin et al., 2019)。预测掩蔽音频区域的集群分配的压力迫使模型学习未掩蔽区域的良好局部声学表示和潜在特征之间的长期时间依赖性。重复这两个步骤可以提高集群质量,从而提高学习表示的质量。
单模态和跨模态视觉HUBERT-
单模态视觉 HuBERT:将 HuBERT 扩展到视觉领域的最简单的方法是使用视觉特征生成目标。 形式上,给定一个图像序列 I 1 : T I_{1:T} I1:T,我们首先通过 k-means 将图像特征聚类成一系列离散单元 z 1 : T i z^i_{1:T} z1:Ti: z t i = k − m e a n s ( G ( I t ) ) ∈ { 1 , 2 , . . . , V } z^i_t = k-means(G(I_t)) ∈ \{1, 2, ..., V \} zti=k−means(G(It))∈{
1,2,...,V},其中 G G G 是视觉特征提取器, V V V是码本大小。 聚类分配 z 1 : T i z^i_{1:T} z1:Ti 作为模型的预测目标。 最初, G G G 可以是工程图像特征提取器,例如方向梯度直方图 (HoG),类似于音频 HuBERT 中的 MFCC。 HuBERT 模型的中间层在后面的迭代中用作 G G G。
为了执行掩码预测任务,该模型首先使用 ResNet 将 I 1 : T I_{1:T} I1:T 编码为中间视觉特征序列 f 1 : T v f^v_{1:T} f1:Tv,然后通过二元掩码 M M M 将其破坏为 f ~ 1 : T v \tilde{f}^v_{1:T} f~1:Tv。具体而言, ∀ t ∈ M ∀t ∈ M ∀t∈M, f ~ t v \tilde{f}^v_t f~tv 被替换为学习的掩码嵌入。 我们在 HuBERT 中采用相同的策略来生成跨度掩码。 被掩蔽的视觉特征 f 1 : T v f^v_{1:T} f1:Tv 通过一个变换器编码器和一个线性投影层被编码成一系列上下文化特征 e 1 : T e_{1:T} e1:T。 损失是在屏蔽区域和可选的未屏蔽区域上计算的(当 α ≥ 0 α ≥ 0 α≥0 时):
其中 ( W ∈ R d × V , b ∈ R V W ∈ R^{d×V}, b ∈ R^V W∈Rd×V,b∈RV) 是投影层的参数,它将特征映射到预测集群分配的 logit 中。
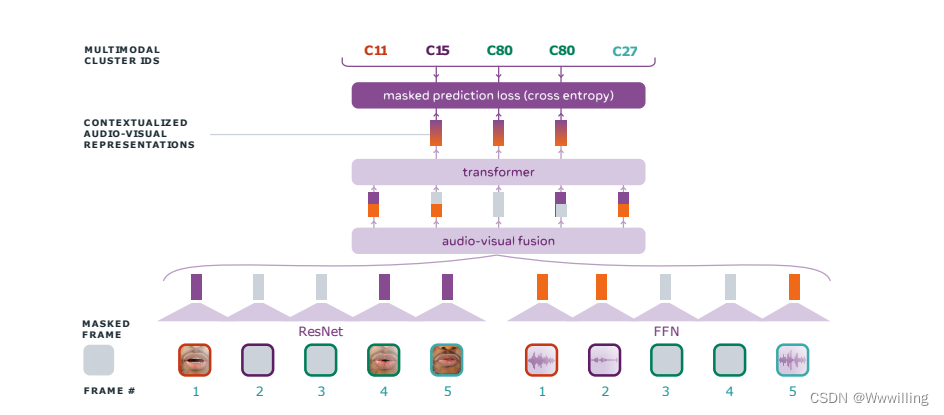
跨模态视觉 HuBERT:单模态视觉 HuBERT 旨在通过逐渐细化的图像特征来学习视觉语音表示。 但是,它不使用视频的音频流。 据推测,音频特征(例如 MFCC 或预训练的音频 HuBERT 模型)与手机的相关性比普通图像特征(例如 HoG)更好。 为此,我们基于对齐的音频帧序列 A 1 : T A_{1:T} A1:T 与视觉编码器并行训练音频编码器。 迭代训练在两个编码器之间交替进行。 在每次迭代中,使用音频编码器 E a E^a Ea 来生成目标集群分配 z 1 : T a z^a_{1:T} z1:Ta。 随后使用 ( I 1 : T , z 1 : T a I_{1:T} , z^a_{1:T} I1:T,z1:Ta) 训练视觉编码器 E v E^v Ev。 z 1 : T a z^a_{1:T} z1:Ta 还用于训练音频编码器 E a E^a Ea 的下一次迭代以进行细化。
跨模态视觉 HuBERT 可以看作是通过从音频流中提取知识来对视觉输入进行建模,其中 z 1 : T a z^a_{1:T} z1:Ta 代表音频方面的知识。 我们假设音频特征比视觉特征更有利于语音表示学习,这在 E.1 节中得到了验证。 对于唇读下游任务至关重要,HuBERT 使用的蒙面预测目标强制模型捕获时间关系,这有助于预测同音词,它们是具有相同视觉形状的声音组(例如,‘p’-‘b’, ‘f’-‘v’, ‘sh’-‘ch’) 使用单个图像帧无法区分。
此外,在将音频和视频输入融合到主干变压器编码器之前,会应用 dropout 来掩盖一种模态的全部特征; 我们将其称为模态辍学。 在概率 p m pm pm 下,两种模式都被用作输入。 当仅使用一种模态时,选择音频流的概率为 p a pa pa。 形式上,给定编码的音频和视觉特征序列 f 1 : T a f^a_{1:T} f1:Ta 和 f 1 : T v f^v_{1:T} f1:Tv,等式 2 显示了配备模态丢失的特征融合: