Extracting Class Activation Maps from Non-Discriminative Features as well
看之前需要了解CAM
摘要
目的:
从分类模型中提取类激活图(CAM)通常会导致前景对象的覆盖率较低,即只识别出可区分的区域(例如“羊”的“头”),而其余区域(例如“羊”的“腿”)被错误地作为背景。 背后的关键是分类器的权重(用于计算CAM)只捕获对象的鉴别特征。
本文方法:
显式地捕获非判别特征,从而将CAM扩展到覆盖整个对象。
- 具体来说,省略了分类模型的最后一个池化层,并对对象类的所有局部特征进行聚类,其中“局部”表示“在空间像素位置”。将结果K聚类中心称为局部原型——表示局部语义,如“羊”的“头”、“腿”和“身体”。
- 给定一个类的新图像,将其未合并的特征与每个原型进行比较,得出K个相似度矩阵,然后将它们聚合成热图(即我们的CAM)。
- 因此,CAM无差别地捕捉到了类的所有局部特征。
代码链接
效果展示

相关工作
图像分类模型被优化为只捕获物体的判别局部区域(特征),导致其CAM对物体的覆盖较差。
种子生成
基于擦除的方法
- AE-PSL是一种以迭代方式运行的对抗性擦除策略:掩盖了当前迭代中的鉴别区域,以显式地迫使模型在下一个迭代中发现新的区域
- ACoL是一种改进的方法:框架由两个分支组成。一个分支对另一个分支应用特征级屏蔽。
然而,这两种方法都有过度擦除的问题,特别是对于小对象。
- CSE是特定于类的擦除方法:基于CAM屏蔽了一个随机对象类,然后显式地惩罚被擦除的类的预测。这样,它就逐渐接近物体在图像上的边界。它不仅可以发现更多的非判别区域,而且还可以缓解(以上两种方法的)过擦除问题,因为它也惩罚了过擦除区域。
基于擦除的方法存在效率低的问题,因为它们必须多次前向传播图像
其他方法
- RIB用信息瓶颈原理解释了CAM的低覆盖率问题 : 通过省略最后一层的激活函数,对多标签分类器进行重新训练,鼓励信息无差别区域的信息向分类器传递。
- 其他学者通过经验观察到,分类模型以局部图像斑块为输入,而不是以整个输入图像为输入,可以发现更多的判别区域。他们提出了一种局部到全局的注意力转移方法,该方法包含一个局部网络,该网络为局部视图生成具有丰富对象细节的局部注意,以及一个全局网络,该网络接收全局视图作为输入,旨在从局部网络中提取区分性注意知识。
- 还有研究人员探索利用对比学习、图神经网络和自监督学习来发现更多的非判别区域。
MASK Refinement
细分方法
- 将种子中的对象区域传播到邻近区域中语义相似的像素:通过在转换矩阵上的随机游走实现的,其中每个元素都是一个亲和分数。相关方法对该矩阵有不同的设计
- PSA是一个用于预测相邻像素之间语义亲和力的AffinityNet
- IRN是一个像素间关系网络,用于估计类边界图,并基于其计算亲和力
- BES它通过使用CAM作为伪地真值来学习预测边界图
所有这些方法都为普通CAM引入了额外的网络模块
其他方法
- 利用显著性图提取背景线索,并将其与目标线索结合起来
- EPS提出了一种结合CAM和显著性图的联合训练策略
- EDAM介绍了一种后处理方法融入显著性图中的自信区域到CAM
方法
本文方法可融入于上面方法当中
LPCAM Pipeline
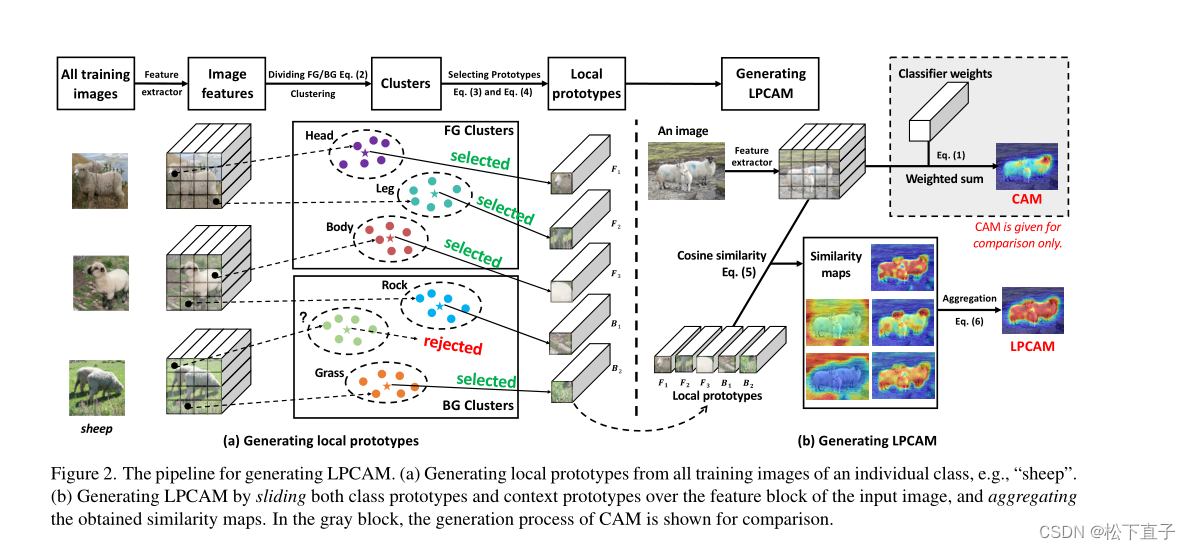
- 使用标准ResNet50作为多标签分类模型的网络骨干(即特征编码器)来提取特征
- 在聚类和上下文的局部原型之前,我们需要前景和背景的粗略位置信息。我们使用传统的CAM来实现这一点。在给定特征f(x)和FC层中对应的分类器权重wn的情况下,我们为每个单独的类n提取它,如下所示:
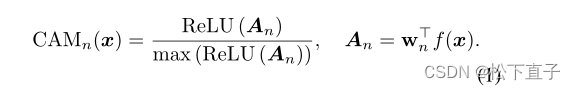
聚类
为每个单独的类执行聚类。给定一类n的图像样本x,我们基于CAM将特征块f(x)在空间上划分为f和B两个集合

对F和B进行K-均值聚类,以获得它们各自的K个类中心,其中K是一个超参数。我们将前景簇中心记为F = {F1,···,FK},背景簇中心记为B = {B1,···,BK}。

Selecting Prototypes
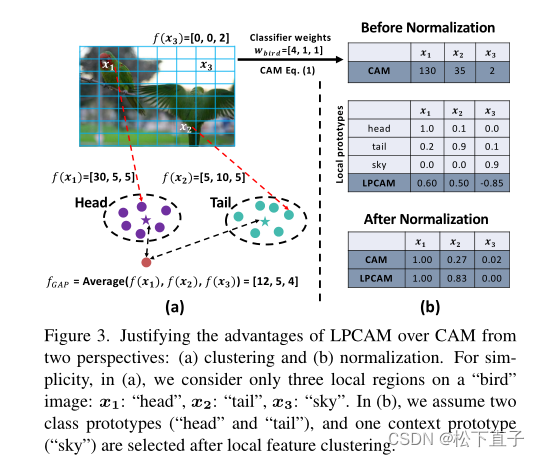
传统CAM的掩码不准确或不完整,例如,背景特征可能被分组为f。为了解决这个问题,我们需要一个“评估者”来检查作为原型的聚类中心是否合格。直观的方法是将分类器wn作为一个自动“评估器”:用它来计算F中每个聚类中心Fi的预测得分:
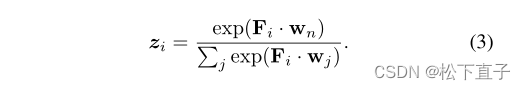
然后,我们选择那些具有高置信度的中心:zi >µf,其中µf是一个阈值,通常是一个非常高的值,如0.9。我们用F ’ = {F ’ 1,···,F ’ k ’ 1}表示所选值。有信心的预测表明该类的强局部特征,即原型
在使用这些局部原型生成LPCAM之前,强调在LPCAM的实现中,不仅保留了非判别特征,而且还抑制了强context特征(即假阳性),因为上下文原型的提取和应用很方便——类似于类原型,但以相反的方式。我们在下面详细阐述这些。对于context聚类中心集B中的每个Bi,我们应用与Fi相同的方法来计算预测得分:
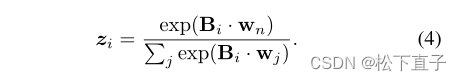
直观地说,如果模型在类标签上训练得很好,那么它对context特征的预测应该非常低。
因此,我们选择zi <µb的中心(其中µb通常是一个类似0.5的值),并将它们表示为b ’ = {b ’ 1,···,b ’ k ’ 2}。值得注意的是,我们的方法对超参数µf和µb的值不敏感,给出合理的范围,例如,µf应该在0.9左右有一个很大的值。我们在章节中对此进行了实证验证
生成LPCAM
对于每个原型,我们将其滑动到特征映射块上的所有空间位置,并计算其与每个位置的局部特征的相似度。我们采用余弦相似度,就像我们使用K-Means一样。最后,我们得到了原型与特征之间的余弦相似度映射。计算完所有相似度图后(通过滑动所有局部原型),我们将它们聚合如下:
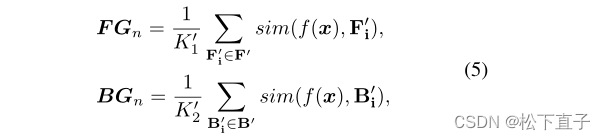
FGn突出显示输入图像中与第n个原型相关的类区域,而BGn突出显示context区域。前者需要保留,后者(例如,与背景高度相关的像素)应该被删除。因此,我们可以将LPCAM表述如下:

证明
证明有时间再补上,详细可以去看一下论文
消融实验
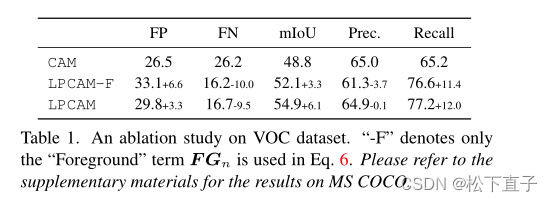
就只做了一个关于前景于背景计算的
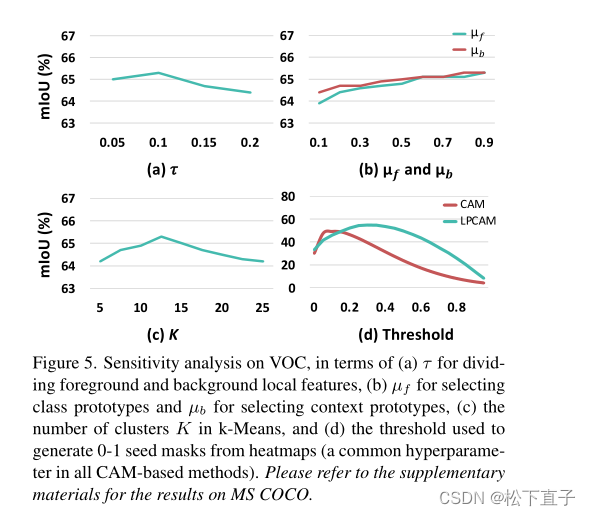
关于阈值的灵敏度分析:
总结
传统CAM覆盖率低的症结在于全局分类器只捕获对象的鉴别特征。本文提出了一种被称为LPCAM的新方法,利用判别和非判别局部原型来生成对对象完全覆盖的激活映射。