缓存技术
缓存是一种加速数据查找(数据读取)的技术。不是直接从IT源读取数据-数据库或另一个远程系统,而是直接从需要数据的计算机上的缓存读取数据。下面是缓存原理的说明:
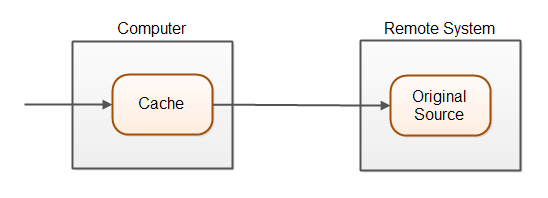
高速缓存是比原始源更接近需要它的实体的存储区域。访问此高速缓存通常比从原始源访问数据更快。缓存通常存储在内存或磁盘上。内存缓存通常比磁盘缓存读得快,但内存缓存通常无法在系统重新启动时生存。
数据缓存可能发生在软件系统的许多不同级别(计算机)中。在现代Web应用程序缓存中,可以在至少3个位置进行,如下所示:
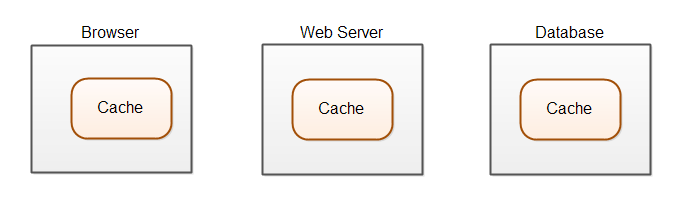
大多数现代Web应用程序使用某种数据库。数据库可以在内存中缓存数据,因此不必从磁盘读取数据。Web服务器可以在内存中缓存像文件、CSS文件、JavaScript等静态文件,而不是每次需要时从磁盘读取这些文件。Web应用程序可以缓存从数据库读取的数据,因此它不必每次需要时访问数据库(通过网络)。最后,浏览器也可以缓存静态文件和数据。在HTML5浏览器中有本地存储、应用程序缓存和Web SQL数据库,在这些数据库中,它们可以存储数据。
在实现缓存时,您需要考虑以下三个问题:
- 填充缓存
- 高速缓存与远程系统同步
- 管理缓存大小
在这篇课文的其余部分,我将讨论这三个问题。
填充缓存
缓存的第一个挑战是用来自远程系统的数据填充缓存。基本上有两种技术可以做到这一点:
- 前期填充
- 懒惰填充
前期填充意味着当缓存系统启动时,你需要用所有需要的值填充缓存。能够做到这一点,就需要知道使用缓存填充数据的数据。在系统启动时,您可能不知道应该将哪些数据插入到高速缓存中。
懒惰填充意味着第一次需要一段数据时填充缓存。首先检查缓存,看看数据是否已经存在。如果没有,则从远程系统读取数据并插入到缓存中。
我总结了前期填充和懒惰填充在下面的表中的优点和缺点:

当然,有可能结合前期和懒惰的填充动作。也许你用最前面读取的数据填充缓存,并让其余数据懒散地填充。
高速缓存与远程系统同步
缓存的一大挑战是保持存储在高速缓存中的数据和存储在远程系统中的数据同步,这意味着数据是相同的。根据系统的结构,有不同的方法来保持数据同步。我将在下面的章节中介绍一些可能的技术。
写入缓存
写通缓存是一个允许读取和写入的高速缓存。如果保持高速缓存的计算机将新数据写入高速缓存,则该数据也被写入远程系统。这就是为什么它被称为“写通”缓存。写入是通过远程系统写入的。
如果远程系统只能通过计算机保持高速缓存,则通过写缓存工作。如果所有数据写入通过高速缓存的计算机,则易于将写入转发到远程系统并相应地更新高速缓存。
基于时间的期满
如果远程系统可以独立于保持高速缓存的计算机进行更新,那么将高速缓存和远程系统保持同步是一个问题。
保持数据同步的一种方法是让缓存中的数据在一定的时间间隔之后过期。当数据过期时,它将从缓存中删除。当再次需要数据时,从远程系统读取新版本的数据并插入到高速缓存中。
多长时间应该取决于你的需要。某些类型的数据(如文章)可能不需要在任何时候都完全更新。也许你可以享受1小时的过期时间。对于一些文章,你甚至可以活24小时的过期时间。
请记住,短的过期时间会导致更多的读取来自远程系统,从而减少了缓存的好处。
有效期满
时间过期的替代方案是活动过期。通过活动过期,我的意思是,您主动终止缓存的数据。例如,如果您的远程系统被更新,您可以发送一条消息给计算机保存缓存,指示它过期更新的数据。
活动期满的优点是,在远程系统中更新之后,缓存中的数据尽可能快地被更新。另外,对于没有更改的数据,您没有任何不必要的到期时间,如您可能使用的基于时间的过期。
活动过期的缺点是您需要能够检测到远程系统的更改。如果你的远程系统是一个关系数据库,并且这个数据库可以通过不同的机制进行更新,这些机制中的每一个都需要能够报告他们更新过的数据。否则,无法向保存缓存的计算机发送过期消息。
管理缓存大小
管理缓存大小也是缓存的一个重要方面。许多系统有如此多的数据存储,不可能或不可行地将所有数据存储在高速缓存中。因此,您需要一种机制来管理缓存中存储的数据量。管理缓存大小通常是通过从缓存中删除数据来为新数据腾出空间来完成的。有几种标准的缓存驱逐技术。这些是:
- Time based eviction.
- First in, first out (FIFO).
- First in, last out (FILO).
- Least accessed.
- Least time between access.
基于时间的驱逐类似于基于时间的期满,这已经在早些时候被覆盖了。除了保持高速缓存与远程系统同步之外,还可以使用基于时间的过期来保持高速缓存大小下降。或者您有一个单独的线程运行,它监视缓存,或者当尝试读取或写入一个新的值到缓存时完成清理。
先入先出意味着当你尝试在缓存中插入新的值时,删除最早的插入值来为新的空间腾出空间。当然,在缓存满足其空间限制之前,您不会删除任何值。
第一个,最后一个是FIFO方法的反向。如果第一个存储值也是通常访问最多的值,则该方法是有用的。
最少访问驱逐意味着首先被访问次数最少的缓存值被驱逐。这种技术的目的是避免重读和存储经常读取的值。为了使该技术工作,缓存必须跟踪给定值已经访问了多少次。
使用最少访问驱逐的注意事项是,缓存中的旧值自动具有更高的访问次数,即使它们不再被访问。也许过去的一篇文章已经被大量访问过,但是现在被访问得少了很多。文章的访问量仍然很高,尽管现在访问次数减少了,但它并没有被删除。为了避免这种情况,访问计数可以计算在最后N个小时内的访问。但这进一步增加了访问计数。
访问驱逐之间的最小时间考虑到访问值之间的时间。当访问一个值时,缓存标记访问值的时间,并增加访问计数。当下次访问该值时,缓存增加访问计数,并计算所有访问之间的平均时间。曾经被大量访问但逐渐普及的值在访问之间的平均时间会下降。迟早,平均值可能会降到足够低,从而导致价值被驱逐。
访问驱逐之间的最小时间的变化是只计算最后N次访问的时间。n可以是100、1或其他一些在应用程序中有意义的数字。每当访问计数达到N时,访问计数被重置为0,并且存取时间也被存储。这种方法会比使用总访问次数和使用时间更快地降低值。
访问之间的最小时间的另一个变化是以规则的间隔重置访问计数,并且只使用最少访问的驱逐。例如,对于每小时缓存一个值,前一个小时的访问计数被存储在另一个变量中,用于驱逐决策。下一个小时的访问计数被重置为0。该机构将具有与上述变化相同的效果。
最后两个变量之间的差异归结为检查访问计数是否达到了N,或者如果时间间隔超过Y,则对于每个缓存访问。因为检查一个整数通常比读取系统时钟快,所以我会采用第一种方法。第一种方法只读取每N次访问的系统时钟,而第二种方法读取每个访问的系统时钟(以查看时间间隔是否已过期)。
请记住,即使使用缓存大小管理,也可能需要逐出、读取和存储值,以确保它们与远程系统同步。即使缓存的值被大量访问,因此应该保留在高速缓存中,有时它可能需要与远程系统同步。
服务器集群中的缓存
在单个服务器上运行的系统中,缓存更简单。使用一个服务器,您可以保证所有的写入都通过同一个服务器,从而使用一个写高速缓存。当您的应用程序分布在服务器集群上时,情况更加复杂。下面的图表说明了这种情况:
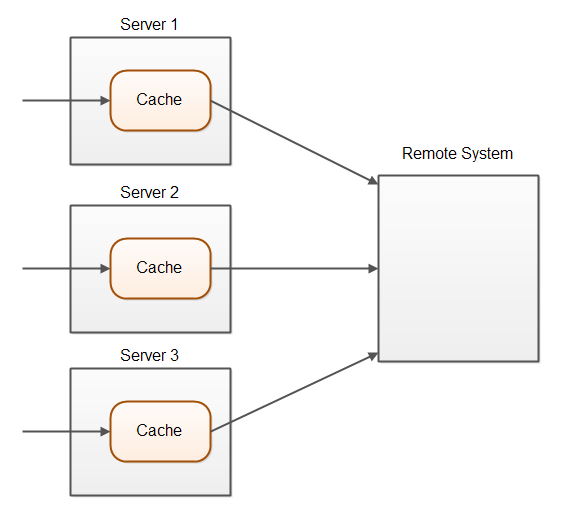
一个简单的写高速缓存只会更新执行写操作的服务器上的缓存。其他服务器上的缓存对写操作一无所知。
在服务器集群中,您可能必须使用基于时间的过期或活动过期,以确保所有高速缓存与远程系统同步。
缓存产品
实现自己的缓存并不难,这取决于您需要的高级程度。但是,如果您没有心情实现自己的缓存,那么存在许多不同的现成的缓存产品。这些产品中的一些是:
- Memcached
- Ehcache
- Redis