回归模型评估指标(MAE、MSE、RMSE、R²、MAPE)
提示:回归模型简单理解就是:学习模型的因变量(y_predict)是一个连续值。
- 平均绝对误差(Mean Absolute Error, MAE):是绝对误差的平均值,可以更好地反映预测值误差的实际情况。
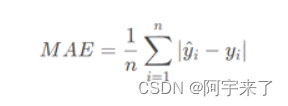
def MAE(Y_real,Y_pre):#计算MAE
from sklearn.metrics import mean_absolute_error
return mean_absolute_error(Y_real,Y_pre)#Y_real为实际值,Y_pre为预测值
- 均方误差(Mean Square Error, MSE):是真实值与预测值的差值的平方,然后求和的平均,一般用来检测模型的预测值和真实值之间的偏差
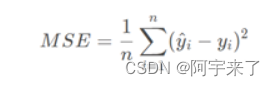
def MSE(Y_real,Y_pre):#计算MSE
from sklearn.metrics import mean_squared_error
return mean_squared_error(Y_real,Y_pre)#Y_real为实际值,Y_pre为预测值
- 均方根误差(Root Mean Square Error, RMSE):即均方误差开根号,方均根偏移代表预测的值和观察到的值之差的样本标准差
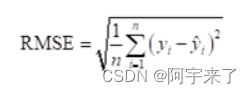
def RMSE(Y_real,Y_pre):#计算RMSE
from sklearn.metrics import mean_squared_error
return np.sqrt(mean_squared_error(Y_real,Y_pre))#Y_real为实际值,Y_pre为预测值
- R²(R squared, Coefficient of determination):决定系数,反映的是模型拟合数据的准确程度,一般R² 的范围是0到1。其值越接近1,表明方程的变量对y的解释能力越强,这个模型对数据拟合的也较好
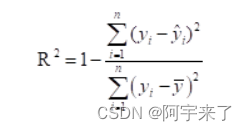
def R2(Y_real,Y_pre):#计算R²
from sklearn.metrics import r2_score
return r2_score(Y_real,Y_pre)#Y_real为实际值,Y_pre为预测值
- 平均绝对百分比误差(Mean Absolute Percentage Error,MAPE):理论上,MAPE 的值越小,说明预测模型拟合效果越好,具有更好的精确度
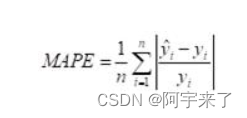
def MAPE(Y_real,Y_pre):#计算mape
from sklearn.metrics import mean_absolute_percentage_error
return mean_absolute_percentage_error(Y_real,Y_pre)#Y_real为实际值,Y_pre为预测值
分类模型的常用评价指标:准确率Accuracy、查准率Precision、查全率Recall、 F1-score、图形面积AUC:
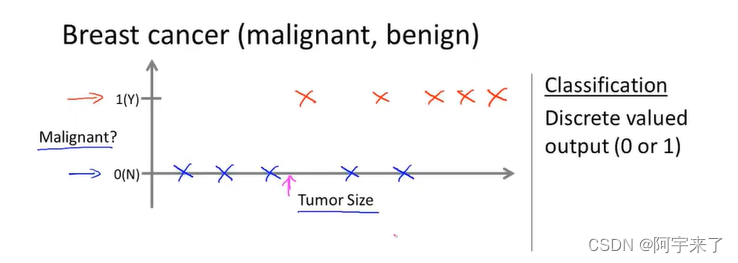
提示:分类模型简单理解就是:学习模型的因变量(y_predict)是一个离散值(结果只有n个类别),例如:n为3就是3分类问题。
例子:根据肿瘤的大小(自变量:Tumor Size)来预测肿瘤(因变量:Malignant)是恶性样本(negative examples)还是良性样本(positive examples)。(二分类问题)
-
基本指标:误差率(错分类样本占总样本的比例)
-
基本指标:准确率(正确分类样本占总样本的比例)
-
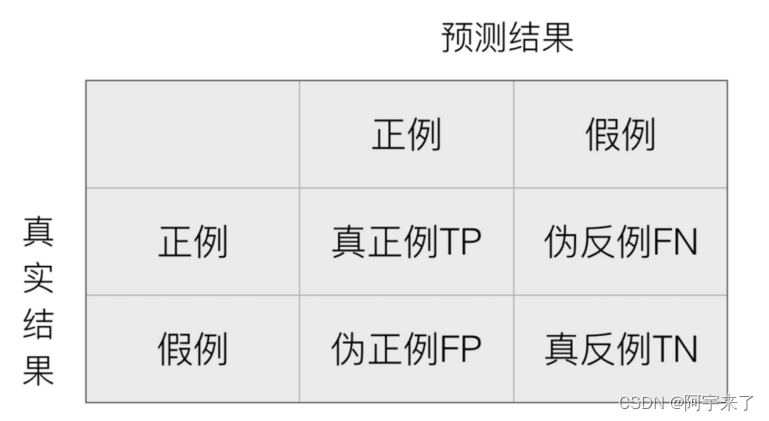
混淆矩阵(二分类问题):在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵
-
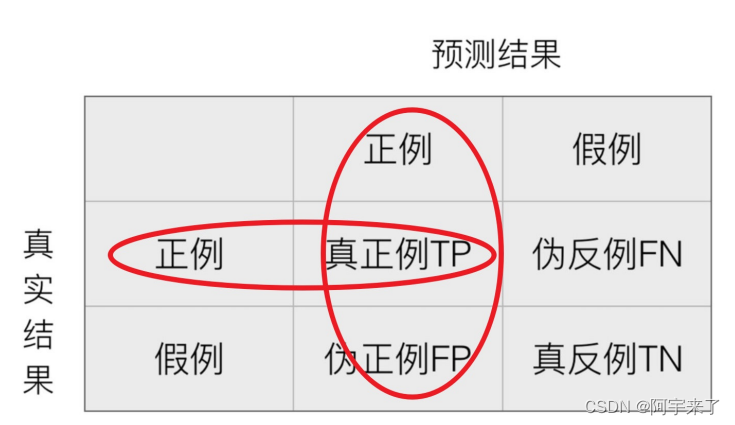
查准率Precision:预测结果为正例样本中真实为正例的⽐例(也成精确率)
-
查全率(召回率)Recall:真实为正例的样本中预测结果为正例的⽐例(查得全,对正样本的区分能⼒)

分类问题评测指标API:
#分类问题评测指标API
from sklearn.metrics import classification_report
#y_test为实际值,y_predict为预测值
#labels:指定类别对应的数字,target_names:⽬标类别名称
ret = classification_report(y_test, y_predict, labels=(2,4), target_names=("良性", "恶性"))
# 打印返回的ret:包括每个类别精确率(Precision)与召回率(Recall)
print(ret)
-
有其他的评估标准:F1-score(反映了模型的稳健型)
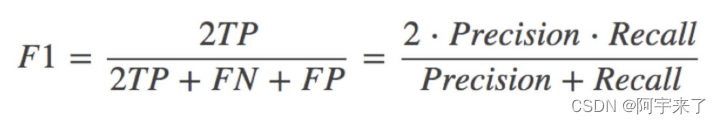
-
TPR与FPR

-
ROC曲线和AOC指标

-
提出背景:为了避免样本不均衡下的评估问题
1.例子:
如果99个样本癌症,1个样本⾮癌症,我直接全都预测正例(默认癌症为正例),准确率就为99%
但是这样效果并不好
2.问题:
这个预测模型(直接全都预测正例的模型)只是在当前不均衡的数据集下又99%的准确率,在其他数据集下结果不为所知。在一些重要业务中,这样的模型根本不具有普遍性,是很可怕的。
3.解决:
使用ROC曲线 -
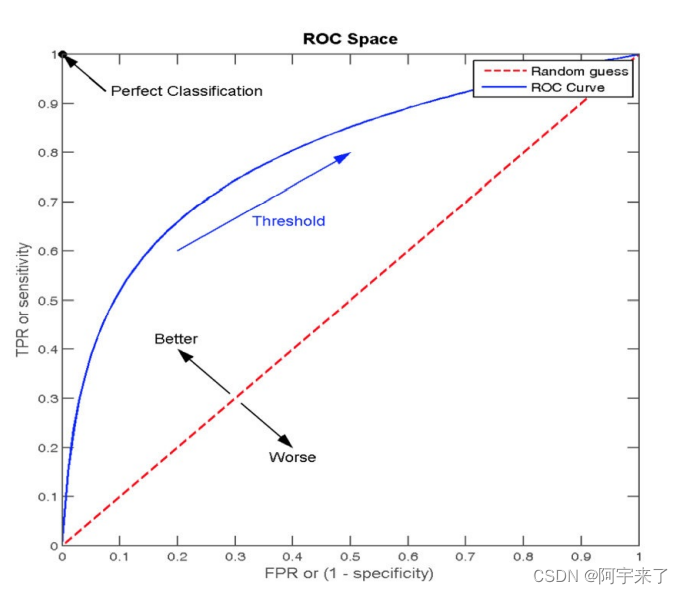
含义:ROC曲线的横轴就是FPRate,纵轴就是TPRate,当⼆者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5.
-
图示:
-
AUC指标
1.AUC的概率意义是随机取⼀对正负样本,正样本得分⼤于负样本得分的概率
2.AUC的范围在[0, 1]之间,并且越接近1越好,越接近0.5属于乱猜
3.AUC=1,完美分类器,采⽤这个预测模型时,不管设定什么阈值都能得出完美预测。但绝⼤多数预测的场合,不存在完美分类器。
4.当0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定合适阈值的话,能有预测价值。 -
AUC计算API

- ROC曲线的绘制
- 绘制流程
- 1.构建模型,把模型的概率值从⼤到⼩进⾏排序
- 2.从概率最⼤的点开始取值,⼀直进⾏tpr和fpr的计算,然后构建整体模型,得到结果
- 3.其实就是在求解积分(⾯积)
- 案例背景
假设有6个样本,有两个是正样本,得到⼀个样本序列(1:1,2:0,3:1,4:0,5:0,6:0),前⾯的表示序号,后⾯的表示正样本(1)或负样本(0)。
然后在这6个样本都通过model算出了正样本的概率序列。 - 三种情况
-
1.如果概率的序列是(1:0.9,2:0.7,3:0.8,4:0.6,5:0.5,6:0.4)
与原来的序列⼀起,得到序列(从概率从⾼到低排)

绘制的步骤是:
1)把概率序列从⾼到低排序,得到顺序(1:0.9,3:0.8,2:0.7,4:0.6,5:0.5,6:0.4);
2)从概率最⼤开始取⼀个点作为正类,取到点1,计算得到TPR=0.5,FPR=0.0;
3)从概率最⼤开始,再取⼀个点作为正类,取到点3,计算得到TPR=1.0,FPR=0.0;
4)再从最⼤开始取⼀个点作为正类,取到点2,计算得到TPR=1.0,FPR=0.25;
5)以此类推,得到6对TPR和FPR。
然后把这6对数据组成6个点(0,0.5),(0,1.0),(0.25,1),(0.5,1),(0.75,1),(1.0,1.0)。
这6个点在⼆维坐标系中能绘出来。
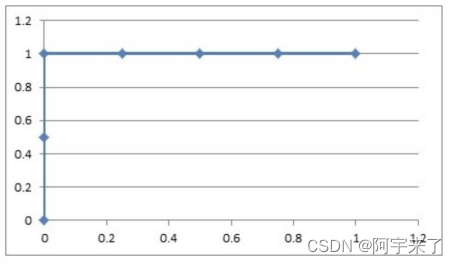
如图所示就是ROC曲线。 -
2.如果概率的序列是(1:0.9,2:0.8,3:0.7,4:0.6,5:0.5,6:0.4)
与原来的序列⼀起,得到序列(从概率从⾼到低排)

绘制的步骤是:
1)把概率序列从⾼到低排序,得到顺序(1:0.9,2:0.8,3:0.7,4:0.6,5:0.5,6:0.4);
2)从概率最⼤开始取⼀个点作为正类,取到点1,计算得到TPR=0.5,FPR=0.0;
3)从概率最⼤开始,再取⼀个点作为正类,取到点2,计算得到TPR=0.5,FPR=0.25;
4)再从最⼤开始取⼀个点作为正类,取到点3,计算得到TPR=1.0,FPR=0.25;
5)以此类推,得到6对TPR和FPR。
然后把这6对数据组成6个点(0,0.5),(0.25,0.5),(0.25,1),(0.5,1),(0.75,1),(1.0,1.0)。
这6个点在⼆维坐标系中能绘出来。
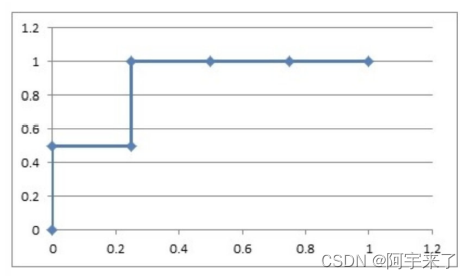
-
3.如果概率的序列是(1:0.4,2:0.6,3:0.5,4:0.7,5:0.8,6:0.9)
与原来的序列⼀起,得到序列(从概率从⾼到低排)

绘制的步骤是:
1)把概率序列从⾼到低排序,得到顺序(6:0.9,5:0.8,4:0.7,2:0.6,3:0.5,1:0.4);
2)从概率最⼤开始取⼀个点作为正类,取到点6,计算得到TPR=0.0,FPR=0.25;
3)从概率最⼤开始,再取⼀个点作为正类,取到点5,计算得到TPR=0.0,FPR=0.5;
4)再从最⼤开始取⼀个点作为正类,取到点4,计算得到TPR=0.0,FPR=0.75;
5)以此类推,得到6对TPR和FPR。
然后把这6对数据组成6个点(0.25,0.0),(0.5,0.0),(0.75,0.0),(1.0,0.0),(1.0,0.5),(1.0,1.0)。
这6个点在⼆维坐标系中能绘出来。
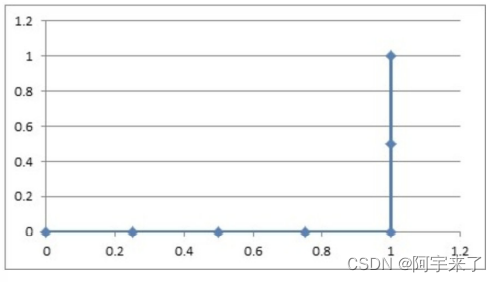
-
- 意义解释
- 如上图的例⼦,总共6个点,2个正样本,4个负样本,取⼀个正样本和⼀个负样本的情况总共有8种。
- 上⾯的
第⼀种情况,从上往下取,⽆论怎么取,正样本的概率总在负样本之上,所以分对的概率为1,AUC=1。再看那个ROC曲线,它的积分是什么?也是1,ROC曲线的积分与AUC相等。 - 上⾯
第⼆种情况,如果取到了样本2和3,那就分错了,其他情况都分对了;所以分对的概率是0.875,AUC=0.875。再看那个ROC曲线,它的积分也是0.875,ROC曲线的积分与AUC相等。 - 上⾯的
第三种情况,⽆论怎么取,都是分错的,所以分对的概率是0,AUC=0.0。再看ROC曲线,它 的积分也是0.0,ROC曲线的积分与AUC相等。 - AUC的意思是——Area Under roc Curve,就是
ROC曲线的积分,也是ROC曲线下⾯的⾯积。 - 绘制
ROC曲线的意义很明显,不断地把可能分错的情况扣除掉,从概率最⾼往下取的点,每有⼀个是负样本,就会导致分错排在它下⾯的所有正样本,所以要把它下⾯的正样本数扣除掉(1-TPR,剩下的正样本的⽐例)。总的ROC曲线绘制出来了,AUC就定了,分对的概率也能求出来了。