机器学习中的评估指标
1. 机器学习的目标
根本目标:
在给定的训练数据上,试图训练出能够归纳数据的规律的模型,并且能在未知样本上也有好的效果。
泛化能力强的模型最好
能很好地适用于未知样本,如错误率低,精度高
2. 评估方法
使用测试集数据进行可靠的评估
测试集:测试集(用于评估)应该与训练集(用于模型学习)“互斥”
常见方法:
- 留出法 hold-out
- 保持数据分布一致(如:分层采样)
- 多次重复划分(如:100次随机划分)
- 数量适中,20-30%

- 交叉验证法 cross-validation
- k折交叉验证
- 若k = m,则得到留一法(leave-one-out,LOO)

自助法 bootstrap
- 基于“自助采样”的方法(bootstrap smapling)
- 别称:“有放回采样”,“可重复采样”
- 约有36.8%的样本不出现
- 训练集与原样本集同规模,且数据分布有所改变(可能会重复出现)
- 测试集:训练集中未出现的原样本
3. 评估度量标准
性能度量 performance measure:
- 衡量模型泛化能力的数值评价标准,反应了当前问题(任务需求)
使用不同的性能度量可能会导致不同的评判结果
模型的“好坏”,不仅取决于算法和数据,还取决于**当前任务需求**
常用性能度量:
- 分类问题
1. 错误率:
2. 精度:
指示函数,当括号内的条件成立时取 1 ,不成立时取 0
二分类混淆矩阵:
| 真实情况 | 预测情况 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
3.查准率(准确率):预测出的正例中真实的正例所占比例
4.查全率(召回率):真实的正例中预测正确的比例
5.F1值:
通过设置权重 \beta ,调整查准率与查全率的重要度
\beta > 1 时,查全率有更大影响;
\beta < 1 时,查准率有更大影响;
6.ROC && AUC
ROC:Receiver Operating Characteristic Cruve
AUC:Area Under thd ROC Cruve,即曲线下方的面积
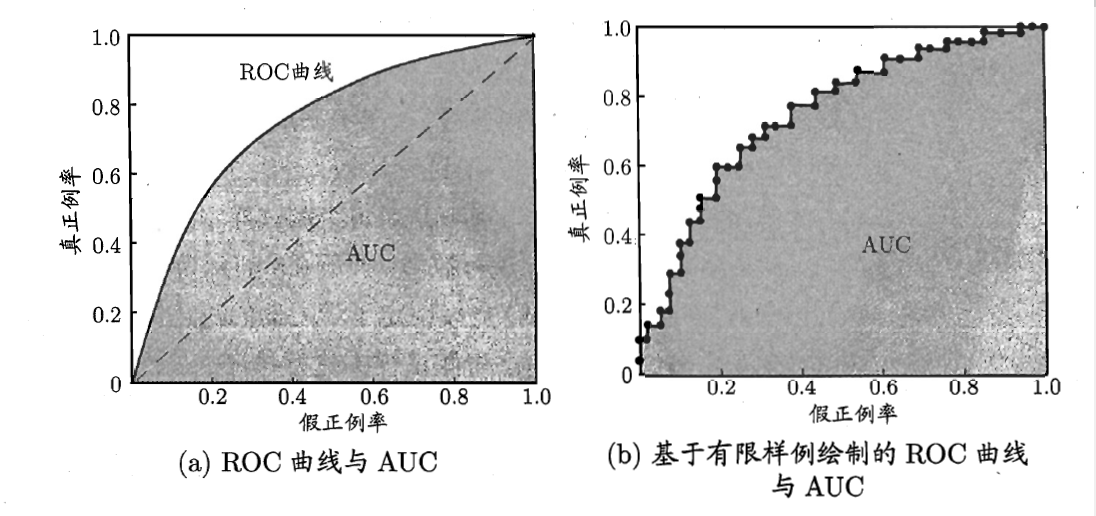
AUC值范围 0~1,值越大,结果越好
- 回归问题
1.平均绝对误差:MAE(Mean Absolute Error)
2.均方误差:MSE(Mean Square Error)
3.均方根误差:RMSE(Root Mean Square Error)
4.R平方