1 、损失函数种类
- 0-1损失函数
J(θ)=1Y≠f(x) J(θ)=0Y=f(x) - 感知损失函数
J(θ)=1|Y−f(X)|>t J(θ)=0|Y−f(X)|<t - 平方和损失函数
J(θ)=∑i=1m(hθ(x(i)−y(i))2 - 绝对值损失函数
J(θ)=∑i=1m|hθ(x(i)−y(i)| - 对数指标
J(θ)=∑i=1m(y(i)loghθ(x(i)))
2 、性能指标
2.1 错误率与精度:
m个样本,有a个分错。
错误率:
精度:
2.2 查准率、查全率和F1:
TP:真正例 / TN:真反例
FP:假正例 / FN:假反例
查准率:
查全率:
F1是查准率和查全率的调和平均数:
与算术平均数相比,调和平均数更加重视较小值。如果对查全率和查准率有偏好,引出了加权调和平均数:
其中
2.3 ROC和AUC:
将m+个正例和m-个负例放进模型,然后预测值从小到大排列,模型目标是让正例尽可能小,负例尽可能大,从最小样例开始,如果是正例,就向上移一格,也就是
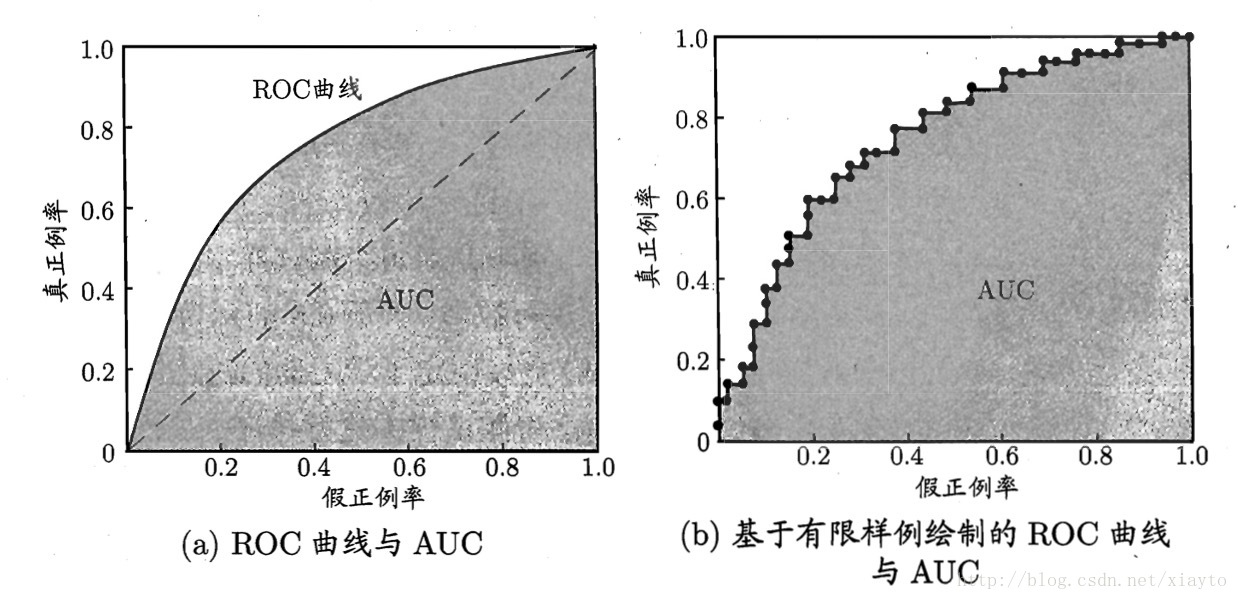
ROC曲线下的面积就是AUC值,AUC越接近1证明模型效果越好。
2.4 回归模型评价指标
MSE:均方差
MAE:平均绝对值误差
RMSE:
TSS:总平方和,表示样本之间的差异情况。
RSS:残差平方和,表示预测值和样本值之间的差异情况
3 、评估方法
3.1 留出法
划分出互斥的训练集和测试集,注意两个集合的分布尽量保持一致,通常采用分层采样的方法。通过若干次的随机划分得到比较稳定可靠的结果。
3.2 交叉验证法
p次k折的交叉验证法,就是k-1个子集作为训练集,剩下的1个作为测试集。
3.3 自助法
有放回的采用,产生更多的测试机,bootstrapping,同时有一部分的数据不会被采集到,可以作为外包估计。