Scrapy爬虫学习笔记1. 安装并编写第一个Scrapy爬虫
以下内容参考自《精通Scrapy网络爬虫一书》,小白的学习记录。
如果想了解一下Scrapy的实现细节,可以在github中下载到源代码,地址如下:
https://github.com/scrapy/scrapy
Scrapy安装
- (1)pip install 安装
- (2)setup.py 安装
- (3)尝试修改version
- 练手小程序,爬取http://books.toscrape.com上的书籍信息
- (1)创建项目,分析stratproject做了哪些事
- (2)分析页面,编写代码,测试
- (3)分析Scrapy的启动过程
1、Scrapy安装
Scrapy是一个基于Python的网络爬虫框架,使用它可以快速地开发出开发出自己的爬虫系统,避免重复造轮子。
(1)使用pip安装
要安装Scrapy,首先需确保安装了Python,我这里已经安装了Python3.6.4。在shell中,使用pip install scrapy 即可安装Scrapy。
安装后,可以测试一下是否安装成功,执行scrapy.version_info查看版本信息。
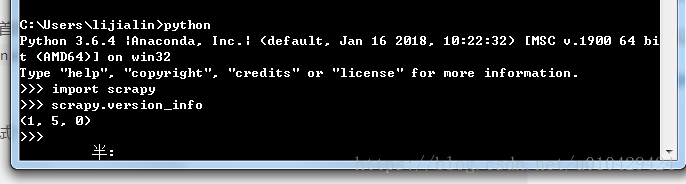
或者在shell中,执行scrapy,看看能否成功执行,就像下面这样。
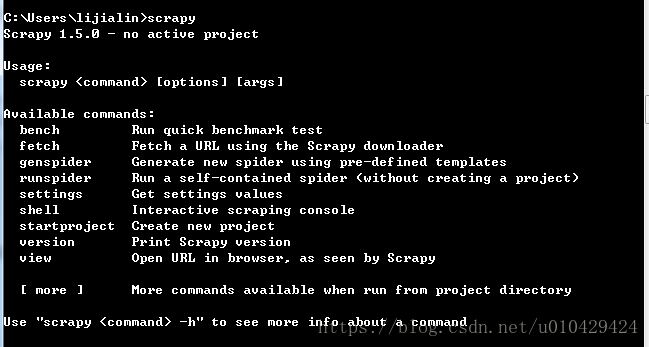
如果可以执行上面两条命令,说明Scrapy安装成功。
(2)使用setup.py 安装源代码
下载Scrapy源代码,解压至某个目录下,比如:E:\1-Workspace\scrapy-master
进入scrapy-master,可以看到一个setup.py文件,打开setup.py,修改代码如下:
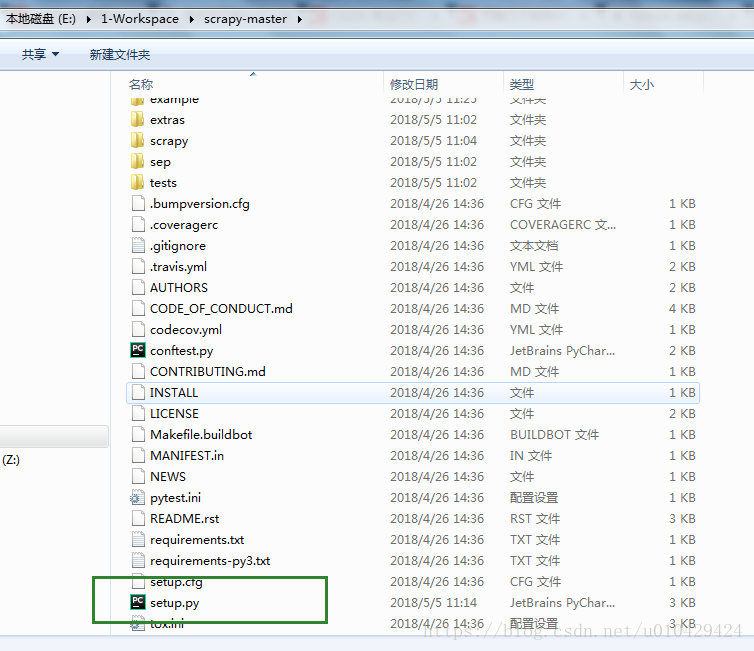
先后执行下面两条命令进行安装
python setup.py build
python setup.py install在路径C:\Users\lijialin\AppData\Local\Continuum\anaconda3\Lib\site-packages下,能够看到一个目录scrapy-1.5.0.1-py3.6.egg。

在shell中测试安装是否成功:
(3)尝试修改version
使用pyCharm打开scrapy-1.5.0.1-py3.6.egg目录中的scrapy子目录,scrapy目录下是Scrapy框架的源代码。打开__init__.py,找到显示版本号的代码段,如下:
# Scrapy version
import pkgutil
__version__ = pkgutil.get_data(__package__, 'VERSION').decode('ascii').strip()
version_info = tuple(int(v) if v.isdigit() else v
for v in __version__.split('.'))
可以修改这段代码,比如这样:
# Scrapy version
import pkgutil
__version__ = pkgutil.get_data(__package__, 'VERSION').decode('ascii').strip()
# 把版本号的每一位数字,都加1
version_info = tuple(int(v)+1 if v.isdigit() else v
for v in __version__.split('.'))
修改后,来测试一下:
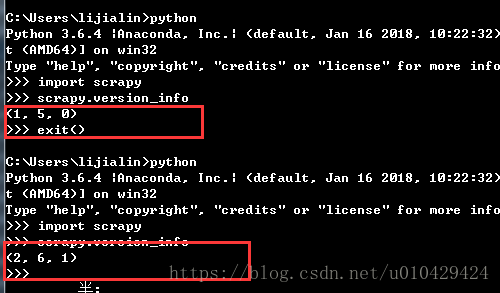
哈哈哈,可以看到版本号由1.5.0变为2.6.1.
小结:
1、上面记录了两种安装方式,第一种使用pip install scrapy直接安装。第二种使用python setup.py install 安装。
2、如果需要安装python,建议安装anaconda。
3、能够修改Scrapy源代码,对于今后阅读和理解框架有很大的帮助。
2、练手小程序:爬取http://books.toscrape.com上的书籍信息
(1)创建项目
使用下面的命令创建一个新的爬虫项目,该项目的路径在:C:\Users\lijialin\books_toscrape
scrapy startproject books_toscrape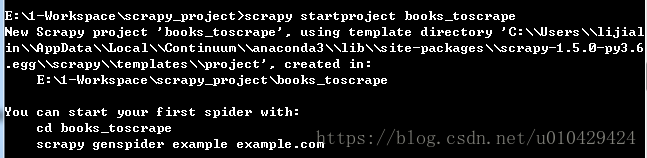
分析一下Scrapy的源代码,C:\Users\lijialin\AppData\Local\Continuum\anaconda3\Lib\site-packages\scrapy-1.5.0-py3.6.egg\scrapy\commands\startproject.py
看看startproject命令,都为我们执行了哪些操作:
TEMPLATES_TO_RENDER = (
('scrapy.cfg',),
('${project_name}', 'settings.py.tmpl'),
('${project_name}', 'items.py.tmpl'),
('${project_name}', 'pipelines.py.tmpl'),
('${project_name}', 'middlewares.py.tmpl'),
)
# 一个递归方法,将src copy到dst
def _copytree(self, src, dst):
# 省略部分代码 ...
names = os.listdir(src)
ignored_names = ignore(src, names)
if not os.path.exists(dst):
os.makedirs(dst)
for name in names:
if name in ignored_names:
continue
srcname = os.path.join(src, name)
dstname = os.path.join(dst, name)
if os.path.isdir(srcname):
self._copytree(srcname, dstname)
else:
copy2(srcname, dstname)
copystat(src, dst)
# 核心方法
def run(self, args, opts):
project_name = args[0]
project_dir = args[0]
# 当执行完下面这句代码,会在project_dir下生成book_toscrapy项目,项目结构如下图所示
self._copytree(self.templates_dir, abspath(project_dir))
# 相当于把module重命名为project_name
move(join(project_dir, 'module'), join(project_dir, project_name))
# 遍历TEMPLATES_TO_RENDER中的每一个文件
for paths in TEMPLATES_TO_RENDER:
path = join(*paths)
tplfile = join(project_dir,
string.Template(path).substitute(project_name=project_name))
render_templatefile(tplfile, project_name=project_name,
ProjectName=string_camelcase(project_name))
print("New Scrapy project %r, using template directory %r, created in:" % \
(project_name, self.templates_dir))
print(" %s\n" % abspath(project_dir))
print("You can start your first spider with:")
print(" cd %s" % project_dir)
print(" scrapy genspider example example.com")
@property
def templates_dir(self):
_templates_base_dir = self.settings['TEMPLATES_DIR'] or \
join(scrapy.__path__[0], 'templates')
return join(_templates_base_dir, 'project')
# 下面这个方法,将.tmpl中的内容重新写入到新的文件中
def render_templatefile(path, **kwargs):
with open(path, 'rb') as fp:
raw = fp.read().decode('utf8')
content = string.Template(raw).substitute(**kwargs)
render_path = path[:-len('.tmpl')] if path.endswith('.tmpl') else path
with open(render_path, 'wb') as fp:
fp.write(content.encode('utf8'))
if path.endswith('.tmpl'):
os.remove(path)
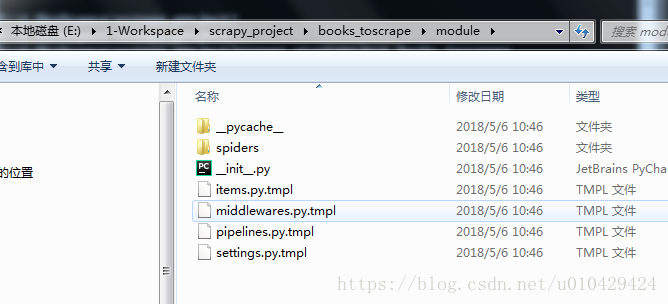
上面代码的大概意思是,按照TEMPLATES中的模板文件,在books_toscrapy项目下,为我们一一创建这些文件。
(2)开始写代码
第一步,分析页面
要爬取的网站链接为:http://books.toscrape.com/
使用Chrome F12 分析html,每一本书对应一个<article></article> 标签。
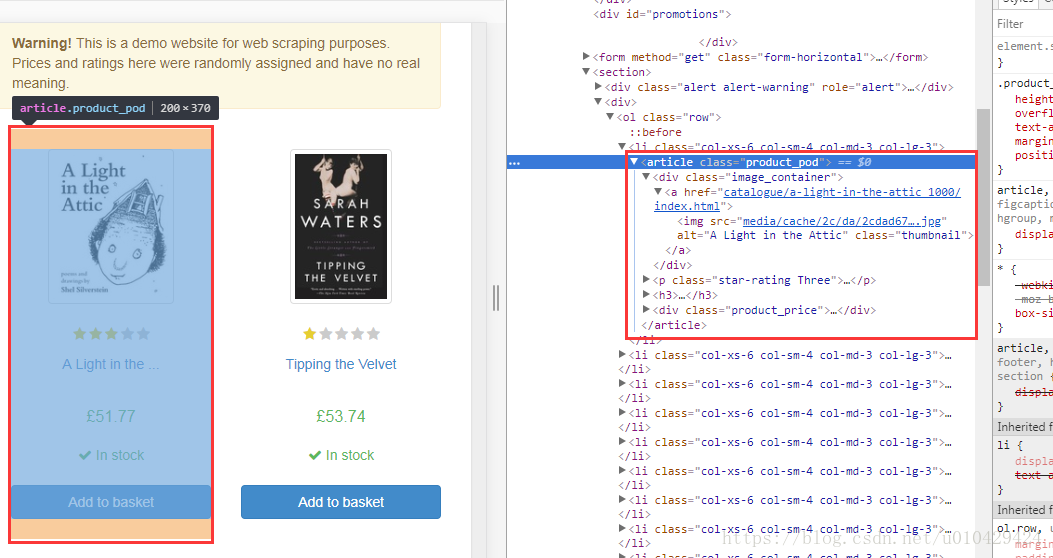
下一页的链接,在<li class="next"></li>标签中
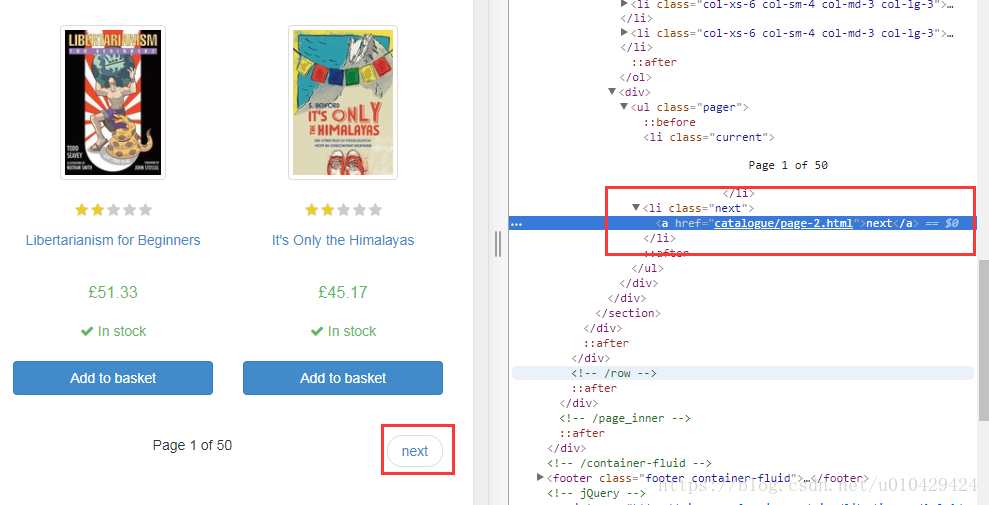
第二步,写代码
以下代码参考自《精通Scrapy网络爬虫一书》,顺便安利一下这本书。
在spider目录下,创建book_spider.py,代码如下:
# -*- coding:utf-8 -*-
import scrapy
class BooksSpider(scrapy.Spider):
name = "books"
start_urls = ['http://books.toscrape.com/'] # 定义起始url
def parse(self, response):
for book in response.css('article.product_pod'):
book_name = book.xpath('./h3/a/@title').extract_first() # 提取书名
book_price = book.css('p.price_color::text').extract_first() # 提取书价
yield {
'book_name': book_name,
'book_price': book_price,
}
next_page_url = response.css('ul.pager li.next a::attr(href)').extract_first() # 提取下一页的url
if next_page_url:
next_page_url = response.urljoin(next_page_url)
yield scrapy.Request(next_page_url, callback=self.parse)
第三步,测试
在shell中,使用命令scrapy crawl books -o books.csv 运行books爬虫,并将数据写入到books.csv中。
books.csv如下,可以看到书名和价钱都抓取到了,尽管价钱乱码了。

(3)分析一下这个程序,看看Scrapy是怎样启动的
首先,我们使用crawl命令来执行这个程序,所以从crawl命令入手分析Scrapy框架的执行过程。
其源码在路径:
C:\Users\lijialin\AppData\Local\Continuum\anaconda3\Lib\site-packages\scrapy-1.5.0-py3.6.egg\scrapy\commands\crawl.py
# 核心方法如下,省略部分代码
def run(self, args, opts):
spname = args[0]
self.crawler_process.crawl(spname, **opts.spargs)
self.crawler_process.start()
# 核心就是调用了crawler_process的crawl()方法
# 在cmdline.py中的execute()方法中,定义了crawler_process
cmd.crawler_process = CrawlerProcess(settings)
# 接着在CrawlerProcess中看看它的start()方法,根据注释可知:CrawlerProceee是一个跑过个爬虫的单进程
class CrawlerProcess(CrawlerRunner):
"""
A class to run multiple scrapy crawlers in a process simultaneously.
This class extends :class:`~scrapy.crawler.CrawlerRunner` by adding support
for starting a Twisted `reactor`_ and handling shutdown signals, like the
keyboard interrupt command Ctrl-C. It also configures top-level logging.
"""
def start(self, stop_after_crawl=True):
"""
This method starts a Twisted `reactor`_, adjusts its pool size to
:setting:`REACTOR_THREADPOOL_MAXSIZE`, and installs a DNS cache based
on :setting:`DNSCACHE_ENABLED` and :setting:`DNSCACHE_SIZE`.
If `stop_after_crawl` is True, the reactor will be stopped after all
crawlers have finished, using :meth:`join`.
:param boolean stop_after_crawl: stop or not the reactor when all
crawlers have finished
"""
# 如果stop_after_crawl为True,则必须等其他爬虫运行结束,才能运行这个爬虫
if stop_after_crawl:
d = self.join()
# Don't start the reactor if the deferreds are already fired
if d.called:
return
d.addBoth(self._stop_reactor)
reactor.installResolver(self._get_dns_resolver())
tp = reactor.getThreadPool() # 初始化线程池对象
#调整线程池大小,如果线程过多,则kill部分线程
tp.adjustPoolsize(maxthreads=self.settings.getint('REACTOR_THREADPOOL_MAXSIZE'))
# 添加事件驱动
reactor.addSystemEventTrigger('before', 'shutdown', self.stop)
reactor.run(installSignalHandlers=False) # blocking call
# 下面是调整线程池大小的代码
def adjustPoolsize(self, minthreads=None, maxthreads=None):
"""
Adjust the number of available threads by setting C{min} and C{max} to
new values.
@param minthreads: The new value for L{ThreadPool.min}.
@param maxthreads: The new value for L{ThreadPool.max}.
"""
if minthreads is None:
minthreads = self.min
if maxthreads is None:
maxthreads = self.max
assert minthreads >= 0, 'minimum is negative'
assert minthreads <= maxthreads, 'minimum is greater than maximum'
self.min = minthreads
self.max = maxthreads
if not self.started:
return
# Kill of some threads if we have too many.
if self.workers > self.max:
self._team.shrink(self.workers - self.max)
# Start some threads if we have too few.
if self.workers < self.min:
self._team.grow(self.min - self.workers)
CrawlerProcess的父类是CrawlerRunner类,CrawlerRunner类中的create_crawler()方法创建了Crawler对象,并调用Crawler的crawl方法,
#################### 1、下面是create_crawler方法 #################
def create_crawler(self, crawler_or_spidercls):
"""
Return a :class:`~scrapy.crawler.Crawler` object.
* If `crawler_or_spidercls` is a Crawler, it is returned as-is.
* If `crawler_or_spidercls` is a Spider subclass, a new Crawler
is constructed for it.
* If `crawler_or_spidercls` is a string, this function finds
a spider with this name in a Scrapy project (using spider loader),
then creates a Crawler instance for it.
"""
if isinstance(crawler_or_spidercls, Crawler):
return crawler_or_spidercls
return self._create_crawler(crawler_or_spidercls)
def _create_crawler(self, spidercls):
if isinstance(spidercls, six.string_types):
spidercls = self.spider_loader.load(spidercls)
return Crawler(spidercls, self.settings)
#################### 2、下面是crawl方法 #################
def crawl(self, crawler_or_spidercls, *args, **kwargs):
"""
Run a crawler with the provided arguments.
It will call the given Crawler's :meth:`~Crawler.crawl` method, while
keeping track of it so it can be stopped later.
"""
crawler = self.create_crawler(crawler_or_spidercls)
return self._crawl(crawler, *args, **kwargs)
def _crawl(self, crawler, *args, **kwargs):
self.crawlers.add(crawler)
# 会调用crawler对象的crawl方法
d = crawler.crawl(*args, **kwargs)
self._active.add(d)
def _done(result):
self.crawlers.discard(crawler)
self._active.discard(d)
return result
return d.addBoth(_done)
#################### 3、下面是Crawler对象的crawl方法 #################
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 1、创建spider
self.spider = self._create_spider(*args, **kwargs)
# 2、创建engine
self.engine = self._create_engine()
# 3、获取start_request
start_requests = iter(self.spider.start_requests())
# 4、调用open_spider()方法
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
# 省略 ...
#################### 4、下面是open_spider方法 #################
# 关于open_spider方法,具体参见:https://blog.csdn.net/happyanger6/article/details/53470638
@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
assert self.has_capacity(), "No free spider slot when opening %r" % \
spider.name
logger.info("Spider opened", extra={'spider': spider})
nextcall = CallLaterOnce(self._next_request, spider)
scheduler = self.scheduler_cls.from_crawler(self.crawler)
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
slot.nextcall.schedule()
slot.heartbeat.start(5)
小结:
本部分通过编写Scrapy爬虫的小例子,从crawl 命令入手,简单分析了Scrapy是如何启动的。即,在CrawlerProcess类中初始化线程池等参数,由其父类CrawlerRunner创建Crawler对象,Crawler对象的crawl方法会调用open_spider()方法开启抓取。
关于代码中的更多细节,可以参考下面的链接,这些文章写得比我详细。
参考:
1、https://blog.csdn.net/ybdesire/article/details/51746268
2、https://blog.csdn.net/happyAnger6/article/details/53367108
3、https://www.cnblogs.com/3wtoucan/p/6020060.html
4、https://blog.csdn.net/happyanger6/article/details/53470638