一、安装scrapy包
1、更改anaconda下载包的镜像路径
进入到cmd命令行,使用命令:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
这里是使用清华的镜像路径。
接下来执行:
conda config --set show_channel_urls yes
此时就会在你的用户目录C:\Users<你的用户名>下生成一个文件。
文件名字为:.condarc
文件内容如下:

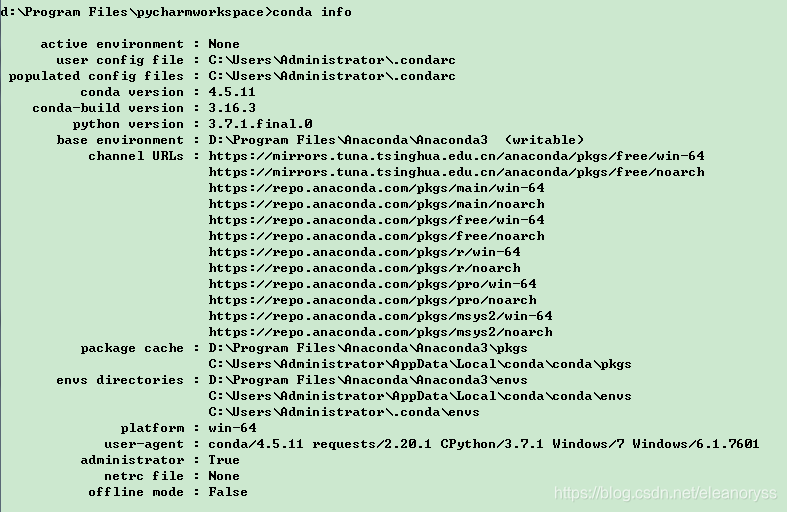
确认镜像是否更新成功,命令如下:
conda info
2、安装scrapy
在命令行中执行此命令:
conda install scrapy
安装过程很快。

3、检查scrapy是否安装成功
使用命令:
conda list
列出所有已经安装的包,检查scrapy是否存在,若存在则已经安装成功。
二、出现的问题及解决办法
1、输入scrapy指令,出现报错:from … import etree ImportError: DLL load failed: 找不到指定的程序。

安装报错信息来看是lxml版本的问题。
解决办法:
(1)卸载已经安装的lxml
pip uninstall lxml

(2)去http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 选择对应的lxml版本下载
因为我的Python是3.7的,windows是64位的,所以我下载的是“lxml-4.2.5-cp37-cp37m-win_amd64.whl”
(3)安装新下载的lxml

再次输入scrapy指令,发现问题解决

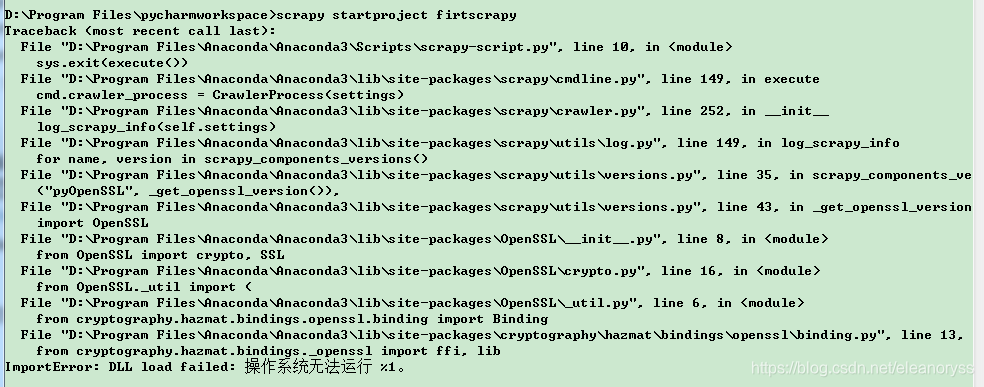
2、创建scrapy工程时报错
from cryptography.hazmat.bindings._openssl import ffi, lib
ImportError: DLL load failed: 操作系统无法运行 %1。
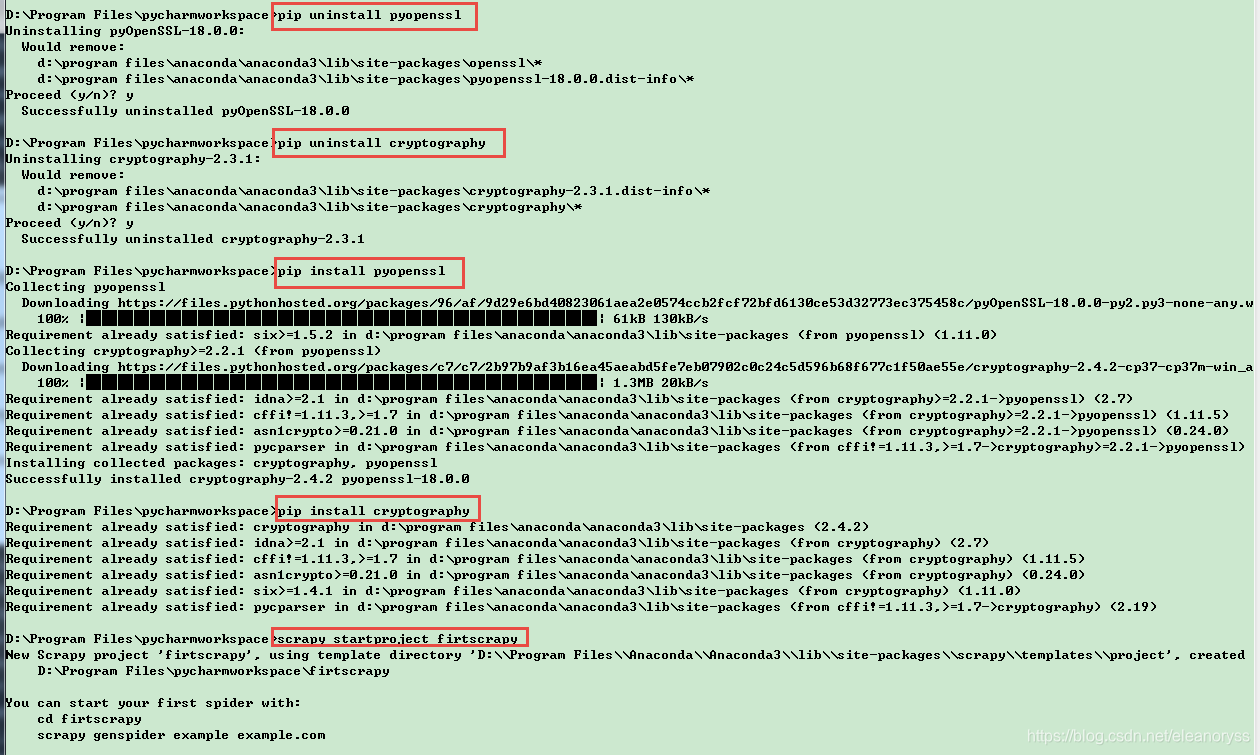
解决办法:
>> pip uninstall pyopenssl
>> pip uninstall cryptography
>> pip install pyopenssl
>> pip install cryptography
二、创建第一个scrapy项目
1、新建scrapy项目
scrapy项目必须用命令行创建,命令如下,项目名为:firtscrapy
scrapy startproject firtscrapy

2、在pycharm中打开上面创建的项目
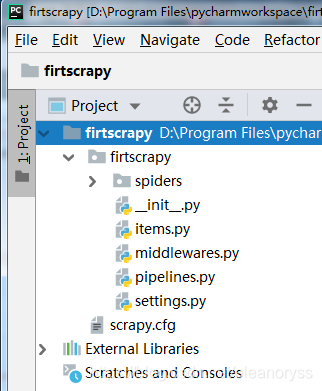
这一步比较简单,有可能import scrapy找不到,解决办法可参见:(https://blog.csdn.net/water3821/article/details/79970621)
3、编写第一个爬虫代码
可以参照scrapy中文手册:Scrapy入门教程。中给的例子来写第一个demo,其实就是按照手册的步骤自己走一遍,能够将一个简单的爬虫代码跑起来,主要目的是熟悉scrapy结构,以及工程中各文件的作用。