版权声明:转载请声明原文链接地址,谢谢! https://blog.csdn.net/weixin_42859280/article/details/84487812
执行:
D:\pycodes\python123demo>scrapy crawl demo
scrapy crawl demo
学习笔记:
代码:

D:\pycodes>scrapy startproject python123demo
New Scrapy project 'python123demo', using template directory 'c:\\users\\hwp\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\scrapy\\templates\\project', created in:
D:\pycodes\python123demo
You can start your first spider with:
cd python123demo
scrapy genspider example example.com
D:\pycodes>
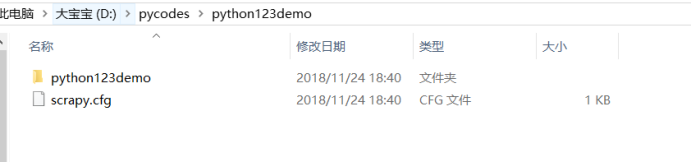
D:.
└─python123demo
│ scrapy.cfg
│
└─python123demo
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ __init__.py
│ │
│ └─__pycache__
└─__pycache__


代码:
D:\pycodes\python123demo>scrapy genspider demo python123.io
Created spider 'demo' using template 'basic' in module:
python123demo.spiders.demo
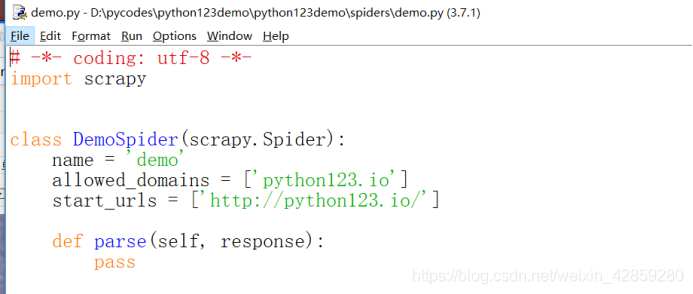
会生成一个文件:demo.py
代码:
*# -- coding: utf-8 --*
import scrapy
class DemoSpider(scrapy.Spider):#类的名字:DemoSpider(叫啥都无所谓) 继承:scrapy.Spider
name = 'demo'
allowed_domains = ['python123.io']#最开始用户提交给命令行的域名:python123.io
start_urls = ['http://python123.io/']#所要爬取页面的初始页面!
def parse(self, response):#解析页面为空的方法!
pass
产生步骤:

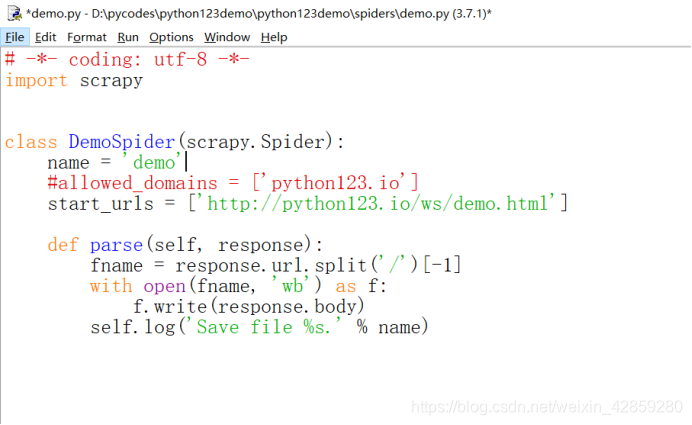
修改:
代码:
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as f:
f.write(response.body)
self.log('Save file %s.' % name)
执行:
D:\pycodes\python123demo>scrapy crawl demo
但是报错误!
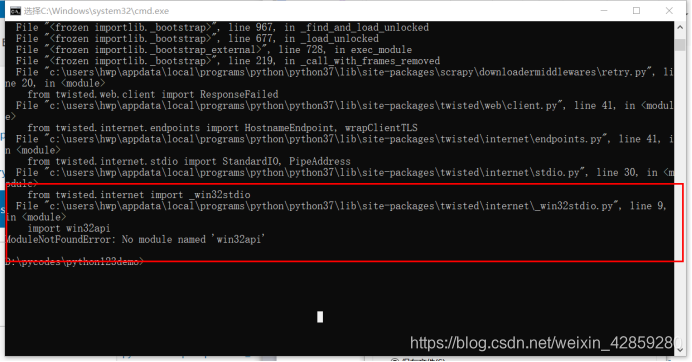
不急解决办法:https://blog.csdn.net/weixin_42859280/article/details/84481289
还要下载依赖:
链接:https://pypi.org/project/pywin32/#files
成功解决后:

demo.py代码的完整版本:与普通的对比!

yiled:啥意思呢~

学习笔记,不是技术文档~