ParNet注意力机制
ParNet注意力是一种用于自然语言处理任务的注意力机制,它是由谷歌在2019年提出的。ParNet注意力旨在解决传统注意力机制在处理长序列时的效率问题。
传统的注意力机制在计算注意力权重时,需要对所有输入序列的位置进行逐一计算,这导致了在长序列上的计算复杂度较高。而ParNet注意力通过将序列分割成多个子序列,并对每个子序列进行独立的注意力计算,从而降低了计算复杂度。
论文地址:https://arxiv.org/pdf/2110.07641.pdf
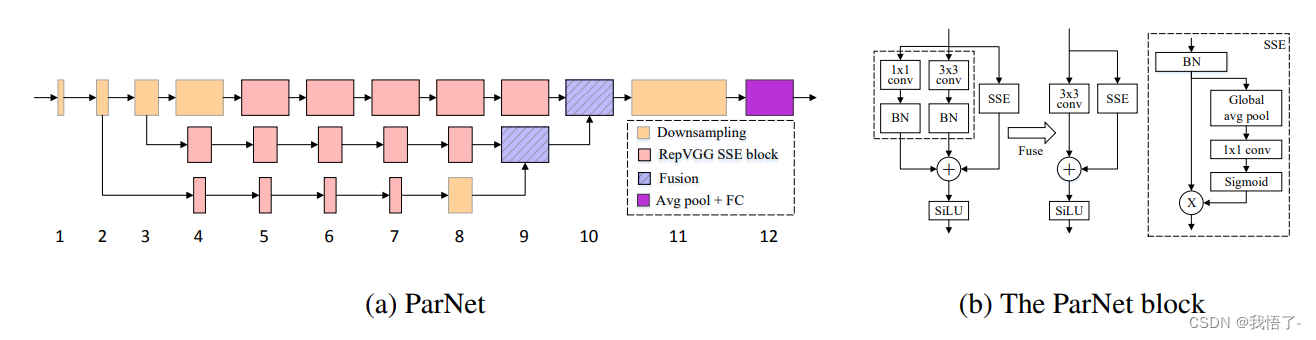
代码如下:
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ParNetAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.sse = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channel, channel, kernel_size=1),
nn.Sigmoid()
)
self.conv1x1 = nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=1),
nn.BatchNorm2d(channel)
)
self.conv3x3 = nn.Sequential(
nn.Conv2d(channel, channel, kernel_size=3, padding=1),
nn.BatchNorm2d(channel)
)
self.silu = nn.SiLU()
def forward(self, x):
b, c, _, _ = x.size()
x1 = self.conv1x1(x)
x2 = self.conv3x3(x)
x3 = self.sse(x) * x
y = self.silu(x1 + x2 + x3)
return y
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
pna = ParNetAttention(channel=512)
output = pna(input)
print(output.shape)