一、实验目的
1、掌握基于线性表、二叉排序树和散列表不同存储结构的查找算法。
2、掌握不同检索策略对应的平均查找长度(ASL)的计算方法,明确不同检索策略的时间性能的差别。
二、设计内容
一篇英文文章存储在一个文本文件中,然后分别基于线性表、二叉排序树和哈希表不同的存储结构,完成单词词频的统计和单词的检索功能。同时计算不同检索策略下的平均查找长度ASL,通过比较ASL的大小,对不同检索策略的时间性能做出相应的比较分析(比较分析要写在实习报告中的“收获和体会”中)。
- 读取一篇包括标点符号的英文文章(InFile.txt),假设文件中单词的个数最多不超过5000个。从文件中读取单词,过滤掉所有的标点。
- 分别利用线性表(包括基于顺序表的顺序查找、基于链表的顺序查找、基于顺序表的折半查找)、二叉排序树和哈希表(包括基于开放地址法的哈希查找、基于链地址法的哈希查找)总计6种不同的检索策略构建单词的存储结构。
- 不论采取哪种检索策略,完成功能均相同。
(1)词频统计
当读取一个单词后,若该单词还未出现,则在适当的位置上添加该单词,将其词频计为1;若该单词已经出现过,则将其词频增加1。统计结束后,将所有单词及其频率按照词典顺序写入文本文件中。其中,不同的检索策略分别写入6个不同的文件。
基于顺序表的顺序查找— OutFile1.txt
基于链表的顺序查找— OutFile2.txt
折半查找— OutFile3.txt
基于二叉排序树的查找— OutFile4.txt
基于开放地址法的哈希查找— OutFile5.txt
基于链地址法的哈希查找— OutFile6.txt
注:如果实现方法正确,6个文件的内容应该是一致的。
(2)单词检索
输入一个单词,如果查找成功,则输出该单词对应的频率,同时输出查找成功的平均查找长度ASL和输出查找所花费的时间。如果查找失败,则输出“查找失败”的提示。
三、测试数据
我这里只是随便找的比较短的一篇

四、设计思路

五、代码内容
1、函数运行时间(高精度)
精度比较高
#include<iostream>
#include<thread>
using namespace std ;
using namespace chrono; //使用命名空间chrono
template <typename T> //函数模板
/*
关键词 auto 看上去很高大上,它是一个“自动类型”,可以理解成“万能类型”,想成为啥,就成为啥
system_clock 是 C++11 提供的一个 clock。除此之外,还有两个clock:steady_clock 和 high_resolution_clock clock:时钟
now( ) 表示计时的那“一瞬间”
duration_cast< > 表示类型转换 duration:持续时间
count( ) 用来返回时间
*/
void measure(T&& func) {
auto start = system_clock::now(); //开始时间
func(); //执行函数
duration<double> diff = system_clock::now() - start; //现在时间 - 开始时间
cout << "elapsed: " << diff.count() << "秒" << endl;
}
void func(){
long long s = 0;
for(int i=0;i<20000000;i++){
s+=i;
}
cout<<s<<endl;
}
int main(){
measure(func);
return 0;
}
2、函数运行时间(低精度)
精度比较低
#include <ctime>
#include <iostream>
using namespace std;
void func(){
long long s = 0;
for(int i=0;i<20000000;i++){
s+=i;
}
cout<<s<<endl;
}
int main(){
clock_t start = clock();
func();
clock_t end = clock();
cout << "花费了" << (double)(end - start) / CLOCKS_PER_SEC << "秒" << endl;
}
3、代码实现
//写一个标准的头文件避免重复编译
#ifndef _HEAD_H
#define _HEAD_H
/*
#include <fstream>
ofstream //文件写操作 内存写入存储设备
ifstream //文件读操作,存储设备读取到内存中
fstream //读写操作,对打开的文件可进行读写操作
void open(const char* filename,int mode,int access);
参数:
filename: 要打开的文件名
mode: 要打开文件的方式
access: 打开文件的属性
打开文件的方式在类ios(是所有流式I/O类的基类)中定义.
常用的值如下:
ios::app: 以追加的方式打开文件
ios::ate: 文件打开后定位到文件尾,ios:app就包含有此属性
ios::binary: 以二进制方式打开文件,缺省的方式是文本方式。两种方式的区别见前文
ios::in: 文件以输入方式打开(文件数据输入到内存)
ios::out: 文件以输出方式打开(内存数据输出到文件)
ios::nocreate: 不建立文件,所以文件不存在时打开失败
ios::noreplace:不覆盖文件,所以打开文件时如果文件存在失败
ios::trunc: 如果文件存在,把文件长度设为0
*/
#include<iostream>
#include<thread>
#include<fstream>
#include<string>
#include<ctime>
#include<cmath>
#include<Windows.h>
using namespace std;
using namespace chrono; //使用命名空间chrono
//常量
const int MaxSize = 1000; //文章单词最大容量
const char* file = "file.txt"; //待检索文件
static int sum = 0; //单词总数(不重复)
// 结构体
// 词频顺序存储结构
struct WordFrequency {
//词频
string word; //单词
int frequency; //频率
int key; //关键码
}WF[MaxSize];
typedef WordFrequency datatype; //为数据类型定义一个新的名字
//词频链式存储结构
struct Node {
datatype data; //数据域
Node* next; //指针域
};
//二叉排序树链式存储结构
struct BiNode {
datatype data; //节点数据域
BiNode* lchild, * rchild; //左右孩子指针
};
//ReadFile函数声明
int StatisticalWord(string word); //统计文章词频(去掉重复单词)
string WordTransition(string word); //大写英语单词转化成小写
int WordJudge(string word); //判断单词中是否有大写字母
void StatisticsData(); //数据统计
int WordTransitionKey(string word); //将单词转换为唯一关键码
//LinkedListMenu函数声明
void ListMenu(); // 线性表菜单
void SequenceMenu(); //顺序查找菜单
void SeqListMenu(); //顺序表顺序查找菜单
void WorLocatMenu();//顺序表单词查找菜单
void LinklistSeqMenu();//链表顺序查找菜单
void LinklistLocateMenu(); //链表单词查找菜单
void HalfSortMenu(); //顺序表折半查找菜单
void HalfdLocateMenu(); //顺序表折半单词查找菜单
//BiTreeMenu函数声明
void BiTreeMenu(); // 二叉排序树菜单
void BitreeLocateMenu(); //二叉排序树的顺序查找菜单
void BitreeWordLocMenu(); //二叉排序树查找单词菜单
//HashTableMenu函数声明
void HashMenu(); //哈希表菜单
void OpenHashLocateMenu(); //开放地址法哈希查找菜单
void OpenHashLocate(); //开放地址法哈希查找
void LinkHashLocate(); //链地址法哈希查找
void LinkHashWordLocateMenu(); //开放地址法哈希查找菜单
void MajorMenu(); //主菜单
#endif // !_HEAD_H
//主函数
int main(){
ifstream fin;
fin.open(file);//关联文件file
if (!fin.is_open()){
cout << "file.txt文件不存在,请检查文件名或者目录下文件是否存在。" << endl;
system("pause"); //暂停
return 0;
} //if
else{
cout << "file.txt文件加载中..." << endl;
Sleep(1000);//延时1秒
} //else
StatisticsData(); //数据统计
MajorMenu();//主菜单
return 0;
}
//主菜单
void MajorMenu(){
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---菜单---" << endl;
cout << "1.基于线性表的查找" << endl;
cout << "2.基于二叉排序树的查找" << endl;
cout << "3.基于哈希表的查找" << endl;
cout << "4.退出系统" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
ListMenu();
break;
case 2:
BiTreeMenu();
break;
case 3:
HashMenu();
break;
case 4:
cout << "系统已退出" << endl;
return;
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("cls"); //清屏
system("pause"); //暂停
} //switch
} //for
}
// 读取TXT内容并整理
//统计文章词频(去掉重复单词)
int StatisticalWord(string word){
for (int i = 0; i < MaxSize; i++){
//循环控制,单词查重
if (WF[i].word == word){
//单词重复
WF[i].frequency++; //词频+1
return i; //退出函数
} //if
} //for
//单词不重复
WF[sum].word = word; //添加单词
WF[sum].frequency = 1; //词频置为一
WF[sum].key = WordTransitionKey(word); //添加关键码
sum ++; //单词总数+1
return 0;
}
//大写英语单词转化成小写
string WordTransition(string word){
for (int i = 0; i < int(word.size()); i++){
//获取字符串长度,使用length()也可以
if (word[i] >= 'A' && word[i] <= 'Z') //判断字符是否是大写字母
word[i] = word[i] + 32; //ASCII码表中十进制 A==65 a==97 中间相差32,后面的也是如此
} //for
return word; //返回小写单词
}
//判断单词中是否有大写字母
int WordJudge(string word){
for (int i = 0; i < int(word.size()); i++){
if (word[i] >= 'A' && word[i] <= 'Z') //判断单词中是否有大写字母
return 1; //如果有,返回1
} //for
return 0; //没有返回0
}
//词频统计
void StatisticsData(){
system("cls"); //清屏
ifstream fin; //文件读操作,存储设备读取到内存中
fin.open(file); //关联文件file
char ch; //用于获取字符
string word; //用于存放单词
int count = 0,min; //count用于标记单词个数,min用于标记最小的单词
for (int i = 0; fin.get(ch); i++){
//读取文件内容,并去除符号
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')){
if (word == "\0") //word为空,放入第一个字母
word = ch;
else
word += ch; //word不为空,拼接字母组成单词
} //if
else{
if (word != "\0"){
//判断之前的word里面是否有单词
count++; //有单词,总数+1
if (count > MaxSize){
cout << "文章单词超出统计上限,系统已退出" << endl;
fin.close(); //关闭文件
exit(0); //退出程序
system("pause"); //暂停
}
StatisticalWord(word); //存放到结构体数组里面
} //if
word = "\0"; //重置word,用于存放新单词
} //else
} //for
//按照词典排序(选择排序) 从小到大
WordFrequency temp; //临时存储空间
for (int i = 0; i < sum; i++){
min = i; //重置min
for (int j = i + 1; j < sum; j++){
if (WordTransition(WF[j].word) < WordTransition(WF[min].word)) //将单词转换成小写进行比较
min = j; //得到最小单词序号
} //for
//交换原始单词,词频
temp = WF[i];
WF[i] = WF[min];
WF[min] = temp;
} //for
for (int i = 0; i < sum; i++){
min = i;
for (int j = i + 1; j < sum; j++){
if (WordTransition(WF[j].word) == WordTransition(WF[min].word)) //两个单词相等
if (WordJudge(WF[j].word) > WordJudge(WF[min].word)) //大写的排前面
min = j; //得到最小单词序号
} //for
//交换原始单词,词频
temp = WF[i];
WF[i] = WF[min];
WF[min] = temp;
} //for
fin.close(); //关闭文件
}
//将单词转换为唯一关键码
int WordTransitionKey(string word) {
int a[21] = {
0,2,3,5,7,11,13,17,19,23,27,29,31,37,41,47,51,67,87,101,111 }; //最长识别20个字母的的单词
int sumkey = 0;
for (int i = 0; i < int(word.size()); i++) {
sumkey += int(word[i]); //每个字符的ASCLL值相加
}
sumkey += int('h') * a[int(word.size())];
return sumkey;
}
//顺序表类
class SeqList{
public:
SeqList() {
} //无参构造
SeqList(datatype a[], int n){
//有参构造函数,初始化长度为n的顺序表
if (n > MaxSize){
cout << "单词数量过多,超出线性表最大容量" << endl;
} //if
for (int i = 0; i < n; i++){
wf[i].word = a[i].word;
wf[i].frequency = a[i].frequency;
} //for
}
~SeqList(){
}; //析构函数
int Empty(); //顺序表判空函数
void PrintList(int n); //遍历操作,按序号依次输出各元素
int SeqlistLocate(string word); //顺序查找
int BinSearch(string word); //折半查找
string getword(int n); //返回单词
int getfre(int n); //返回词频
private:
datatype wf[MaxSize]; //存放词频结构体的数组
};
//返回单词
string SeqList::getword(int n) {
return wf[n].word;
}
//返回词频
int SeqList::getfre(int n) {
return wf[n].frequency;
}
//顺序表判空函数
int SeqList::Empty(){
if (sum == 0)
return 1;
else
return 0;
}
//顺序查找
int SeqList::SeqlistLocate(string word){
for (int i = 0; i < sum; i++){
//依次遍历
if (wf[i].word == word) //找到word
return i; //返回下标
} //for
return -1; //未找到返回-1
}
//折半查找
int SeqList::BinSearch(string word){
int mid, low = 0, high = sum - 1; //初始查找区间是[0, sum-1]
while (low <= high) {
//当区间存在时
mid = (low + high) / 2; //初始化中值
if (word == wf[mid].word) //找到word
break; //退出循环
else if (WordTransition(word) < WordTransition(wf[mid].word)) //word在前半段
high = mid - 1; //改变上限,gigh前移查找区间变为 [low,mid-1]
else //word在后半段,或者不存在
low = mid + 1; //改变下线,low后移查找区间变为 [mid+1,high]
} //while
if (low <= high)
return mid; //找到返回下标
else
return -1; //未找到返回-1
}
//输出线性表顺序表,参数n用来控制输出顺序查找还是折半查找
void SeqList::PrintList(int n){
system("cls"); //清屏
if (n == 1){
ofstream fout; //文件写操作 内存写入存储设备
fout.open("outfile1.txt");
fout << "单词总数为:" << sum << endl;
fout << "词频" << "\t" << "单词" << endl;
for (int i = 0; i< sum; i++){
fout << wf[i].frequency << "\t" << wf[i].word << endl;
} //for
fout.close(); //关闭文件
} //if
if (n == 2){
ofstream fout; //文件写操作 内存写入存储设备
fout.open("outfile3.txt");
fout << "单词总数为:" << sum << endl;
fout << "词频" << "\t" << "单词" << endl;
for (int i = 0; i < sum; i++) {
fout << wf[i].frequency << "\t" << wf[i].word << endl;
} //for
fout.close(); //关闭文件
} //if
cout << "单词总数为:" << sum << endl;
cout << "词频" << "\t" << "单词" << endl;
for (int i = 0; i < sum; i++)
cout << wf[i].frequency << "\t" << wf[i].word << endl;
if (n == 1)
cout << "单词以及词频已经保存到文件outfile1.txt文件中" << endl;
else if (n == 2)
cout << "单词以及词频已经保存到文件outfile3.txt文件中" << endl;
system("pause"); //暂停
}
//链表类
class LinkList{
public:
LinkList(datatype a[], int n) {
//有参构造函数,建立有n个元素的单链表
Head = new Node; //生成头结点
Node* r = Head, * s = NULL; //尾指针初始化,并定义存储指针
for (int i = 0; i < n; i++){
s = new Node;
s->data = a[i]; //数据域赋值
r->next = s; //将存储节点s插入链表
r = s; //更新尾指针
} //for
r->next = NULL; //单链表建立完毕,将终端结点的指针域置空
}
~LinkList() {
//析构函数
Node* temp = NULL; //定义临时节点
while (Head != NULL){
//释放单链表的每一个结点的存储空间
temp = Head; //暂存被释放结点
Head = Head->next; // Head指向被释放结点的下一个结点
delete temp;
} //while
}
int Empety(); //判断链表是否为空
int Locate(string word); //按值查找,返回下标
void PrintList(); //遍历操作,按序号依次输出各元素
datatype getdata(int n);
private:
Node* Head; //单链表的头指针
};
//返回数据域
datatype LinkList::getdata(int n) {
Node* t = Head->next; //指针初始化
for (int i = 1; i < n; i++)
t = t->next;
return t->data;
}
//判空
int LinkList::Empety(){
if (Head->next)
return 1; //链表非空,正常返回
return 0; //链表为空,返回-1
}
//输出单链表
void LinkList::PrintList(){
system("cls"); //清屏
Node* p = Head->next;//工作指针p初始化
ofstream fout; //文件写操作 内存写入存储设备
fout.open("outfile2.txt"); //打开文件
fout << "单词总数为:" << sum << endl;
fout << "词频" << "\t" << "单词" << endl;
while (p != NULL){
fout << p->data.frequency << "\t" << p->data.word << endl;
p = p->next; //指针p后移
} //while
fout.close(); //关闭文件
cout << "单词总数为:" << sum << endl;
cout << "词频" << "\t" << "单词" << endl;
Node* p1 = Head->next;//工作指针p初始化
while (p1){
//p <--> p != NULL
cout << p1->data.frequency << "\t" << p1->data.word << endl;
p1 = p1->next; //工作指针p后移,注意不能写作p++
} //while
cout << "单词以及词频已经保存到文件outfile2.txt文件中" << endl;
system("pause"); //暂停
}
//按值查找,返回下标
int LinkList::Locate(string word){
Node* p = Head->next; //指针p初始化
int count = 1; //计数器count初始化,表示查找次数
while (p != NULL){
if (p->data.word == word)
return count; //查找成功,结束函数并返回下标
p = p->next; //p指针后移
count++;
} //while
return -1; //退出循环表明查找失败
}
// 线性表菜单
void ListMenu(){
while(true) {
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---基于线性表的查找---" << endl;
cout << "1.顺序查找" << endl;
cout << "2.折半查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1 :
SequenceMenu(); //顺序查找菜单
break;
case 2 :
HalfSortMenu(); //顺序表折半查找菜单
break;
case 3 :
return; //结束函数
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
} //switch
} //while
}
//顺序查找菜单
void SequenceMenu(){
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---顺序查找---" << endl;
cout << "1.顺序表查找" << endl;
cout << "2.链表顺序查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
SeqListMenu(); //顺序查找菜单
break;
case 2:
LinklistSeqMenu(); //链表查找菜单
break;
case 3:
return; //结束函数
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
break;
} //switch
} //while
}
//顺序表顺序查找菜单
void SeqListMenu(){
SeqList L(WF, sum);
while(true){
system("cls");
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---顺序表顺序查找---" << endl;
cout << "1.词频统计" << endl;
cout << "2.单词查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
L.PrintList(1); //输出线性表顺序表词频统计
break;
case 2:
WorLocatMenu(); //顺序表顺序单词查找菜单
break;
case 3:
return;
default: cout << "输入的不是有效符号,请重新输入" << endl;
system("pause");
} //switch
} //while
return;
}
//链表顺序查找菜单
void LinklistSeqMenu(){
LinkList L(WF, sum);
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---链表顺序查找---" << endl;
cout << "1.词频统计" << endl;
cout << "2.单词查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
L.PrintList(); //输出线性表链表词频统计
break;
case 2:
LinklistLocateMenu(); //链表单词查找
break;
case 3:
return;
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
} //switch
} //while
return;
}
//顺序表顺序单词查找菜单
void WorLocatMenu(){
SeqList L(WF , sum);
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---顺序表单词查找---" << endl;
cout << "请输入要查找的单词:";
string word;
cin >> word; //键盘录入要查找单词
auto start = system_clock::now(); //开始时间
int i = L.SeqlistLocate(word); //返回下标
duration<double> diff = system_clock::now() - start; //现在时间 - 开始时间
if (i+1) {
cout << "此单词为:" << L.getword(i) << endl;
cout << "此单词的词频:" << L.getfre(i) << endl;
cout << "查找该单词所花费的时间:" << (diff.count())*1000 << "毫秒" << endl;
cout << "平均查找长度:" << (sum + 1) / 2 << endl;
} //if
else
cout << "查找失败" << endl;
system("pause"); //暂停
}
//链表单词查找菜单
void LinklistLocateMenu(){
LinkList L(WF, sum);
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---链表单词查找---" << endl;
cout << "请输入要查找的单词:";
string word;
cin >> word;
auto start = system_clock::now(); //开始时间
int i = L.Locate(word);
duration<double> diff = system_clock::now() - start; //现在时间 - 开始时间
if (i) {
cout << "此单词为:" << L.getdata(i).word << endl;
cout << "此单词的词频:" << L.getdata(i).frequency << endl;
cout << "查找该单词所花费的时间:" << (diff.count())*1000 << "毫秒" << endl;
cout << "平均查找长度:" << (sum + 1) / 2 << endl;
} //if
else
cout << "查找失败" << endl;
system("pause"); //暂停
}
//顺序表折半查找菜单
void HalfSortMenu(){
SeqList L(WF, sum);
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---基于顺序表的折半查找---" << endl;
cout << "1.词频统计" << endl;
cout << "2.单词查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
L.PrintList(2); //折半查找,输出
break;
case 2:
HalfdLocateMenu(); //折半查找
break;
case 3:
return; //退出函数
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
} //switch
} //while
}
//顺序表折半查找菜单
void HalfdLocateMenu(){
SeqList L(WF, sum);
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---折半单词查找---" << endl;
cout << "请输入要查找的单词:";
string word;
cin >> word;
auto start = system_clock::now(); //开始时间
L.BinSearch(word);
duration<double> diff = system_clock::now() - start; //现在时间 - 开始时间
int i = L.BinSearch(word); //返回下标
if (i >= 0) {
cout << "此单词为:" << L.getword(i) << endl;
cout << "此单词的词频:" << L.getfre(i) << endl;
cout << "查找该单词所花费的时间:" << (diff.count())*1000 << "毫秒" << endl;
cout << "平均查找长度:" << double((log(double(sum) + 1) / log(2)) - 1) << endl;
} //if
else
cout << "查找失败" << endl;
system("pause"); //暂停
}
//开放地址哈希表类
class HashTable{
public:
HashTable(); //构造函数,初始化空散列表
~HashTable(){
}; //析构函数
int Insert(datatype a); //插入
int Search(string word); //查找
datatype Get(int a);
void Print(); //输出
private:
int H(int k); //哈希函数(散列函数)
datatype ht[MaxSize]; //散列表
};
//构造函数
HashTable::HashTable(){
for (int i = 0; i < MaxSize; i++){
ht[i].key = 0; //关键码初始化
ht[i].word = "";
ht[i].frequency = 0; // 0表示该散列单元为空
} //for
}
//哈希函数,除留余数法
int HashTable::H(int k){
return k % MaxSize;
}
//输出函数
void HashTable::Print() {
system("cls"); //清屏
ofstream fout; //文件写操作 内存写入存储设备
fout.open("outfile5.txt"); //打开文件
fout << "单词总数为:" << sum << endl;
fout << "词频" << "\t" << "单词" << endl;
for (int i = 0; i < sum; i++) {
fout << WF[i].frequency << "\t" << WF[i].word << endl;
cout << WF[i].frequency << "\t" <<WF[i].word << endl;
} //for
system("pause"); //暂停
}
//查找函数
int HashTable::Search(string word){
int key = WordTransitionKey(word); //将单词转化为关键码
int i = H(key); //计算散列地址,设置比较的起始位置
while (ht[i].key != 0){
if (ht[i].word == word)
return i; //查找成功
else
i = (i + 1) % MaxSize; //向后探测一个位置
} //while
return 0; //查找失败
}
//插入函数
int HashTable::Insert(datatype f_word_key){
int key = WordTransitionKey(f_word_key.word);//将单词转化为关键码
int i = H(key); //计算散列地址,设置比较的起始位置
while (ht[i].key != 0){
//寻找空的散列单元
i = (i + 1) % MaxSize; //向后探测一个位置
} //while
ht[i].key = key; //关键码赋值
ht[i].word = f_word_key.word; //单词赋值
ht[i].frequency = f_word_key.frequency; //词频赋值
return i; //返回插入位置
}
//获取单词以及频率
datatype HashTable::Get(int a){
return ht[a];
}
//链地址法哈希表类
class HashTableLink{
public:
HashTableLink(); //构造函数,初始化开散列表
~HashTableLink(); //析构函数,释放同义词子表结点
int Insert(datatype fword); //插入
Node* Search(string word); //查找
void Print(); //输出
private:
int H(int k); //散列函数
Node* ht[MaxSize]; //开散列表
};
//构造函数
HashTableLink::HashTableLink(){
for (int i = 0; i < MaxSize; i++)
ht[i] = NULL; //链式存储结构指针置空
}
//析构函数,释放空间
HashTableLink :: ~HashTableLink(){
Node* p = NULL, * q = NULL;
for (int i = 0; i < MaxSize; i++){
p = ht[i];
q = p; //用来储存p
while (p != NULL){
//p非空
p = p->next; //p后移
delete q; //删除q
q = p;
} //while
} //for
}
//除留余数法-散列函数
int HashTableLink::H(int k){
return k % MaxSize;
}
//输出到屏幕和文本文件outfile6.txt
void HashTableLink::Print() {
system("cls"); //清屏
ofstream fout; //文件写操作 内存写入存储设备
fout.open("outfile6.txt"); //打开文件
fout << "单词总数为:" << sum << endl;
fout << "词频" << "\t" << "单词" << endl;
for (int i = 0; i < sum; i++) {
fout << WF[i].frequency << "\t" << WF[i].word << endl;
cout << WF[i].frequency << "\t" <<WF[i].word << endl;
} //for
system("pause"); //暂停
}
//查找函数
Node* HashTableLink::Search(string word){
int k = WordTransitionKey(word); //转化为关键码
int j = H(k); //计算散列地址
Node* p = ht[j]; //指针p初始化
while (p != NULL){
//p非空
if (p->data.word == word)
return p; //已找到返回指针
else
p = p->next; //p后移
} //while
return nullptr; //未找到返回空指针
}
//插入函数(前插法)
int HashTableLink::Insert(datatype fword){
int k = WordTransitionKey(fword.word); //转化为关键码
fword.key = k; //给关键码赋值
int j = H(k); //计算散列地址
Node* p = Search(fword.word); //调用查找函数
if (p != nullptr) //p非空,表示该内容已经插入过了
return -1; //已存在元素k,无法插入
else {
//p为空,表示该内容未插入
p = new Node; //生成新节点
p->data.key = fword.key; //关键码赋值
p->data.frequency = fword.frequency; //词频赋值
p->data.word = fword.word; //单词赋值
p->next = ht[j]; //新节点插入ht[j]
ht[j] = p; //更新节点
return 1; //插入成功标志
}
}
//哈希表菜单
void HashMenu(){
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---哈希表---" << endl;
cout << "1.开放地址法哈希查找" << endl;
cout << "2.链地址法哈希查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1 :
OpenHashLocate(); //开放地址法哈希查找
break;
case 2 :
LinkHashLocate(); //链地址法哈希查找
break;
case 3 :
return; //退出函数
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause");
} //switch
} //while
return;
}
//开放地址法哈希查找菜单
void OpenHashLocateMenu(){
HashTable HT;
for (int i = 0; i < sum; i++)
HT.Insert(WF[i]); //把数据插入到哈希表中
double bulkfactor = sum / MaxSize; //装填因子
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---开放地址单词查找---" << endl;
cout << "请输入要查找的单词:";
string word;
cin >> word;
auto start = system_clock::now(); //开始时间
int i = HT.Search(word); //获取散列地址
duration<double> diff = system_clock::now() - start; //现在时间 - 开始时间
if (i) {
cout << "此单词为:" << HT.Get(i).word << endl;
cout << "此单词的词频:" << HT.Get(i).frequency << endl;
cout << "查找该单词所花费的时间:" << (diff.count())*1000 << "毫秒" << endl;
cout << "平均查找长度:" << (1 + 1 / (1 - bulkfactor)) / 2 << endl;
} //if
else
cout << "查找失败" << endl;
system("pause"); //暂停
}
//开放地址法哈希查找
void OpenHashLocate(){
HashTable HT;
for (int i = 0; i < sum; i++)
HT.Insert(WF[i]); //把数据插入到哈希表中
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---基于开放地址法的哈希查找---" << endl;
cout << "1.词频统计" << endl;
cout << "2.单词查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1 :
HT.Print(); //词频统计
break;
case 2 :
OpenHashLocateMenu(); //开放地址法的哈希查找菜单
break;
case 3 :
return;
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
} //switch
} //while
}
//链地址法哈希查找
void LinkHashLocate(){
HashTableLink HT;
for (int i = 0; i < sum; i++)
HT.Insert(WF[i]); //把数据插入到哈希表
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---基于链地址法的哈希查找---" << endl;
cout << "1.词频统计" << endl;
cout << "2.单词查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
HT.Print(); //词频统计
break;
case 2:
LinkHashWordLocateMenu(); //单词查找菜单
break;
case 3:
return; //退出函数
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
} //switch
} //while
}
//链地址法哈希查找菜单
void LinkHashWordLocateMenu(){
HashTableLink HT;
for (int i = 0; i < sum; i++)
HT.Insert(WF[i]); //把数据插入到哈希表
double load_factor = sum / MaxSize;//散列表的装填因子
system("cls");
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---链地址单词查找---" << endl;
cout << "请输入要查找的单词:";
string word;
cin >> word;
auto start = system_clock::now(); //开始时间
HT.Search(word);
duration<double> diff = system_clock::now() - start; //现在时间 - 开始时间
Node* p = HT.Search(word); //返回目标指针
if (p != NULL) {
cout << "此单词为:" << p->data.word << endl;
cout << "此单词的词频:" << p->data.frequency << endl;
cout << "查找该单词所花费的时间:" << (diff.count())*1000 << "毫秒" << endl;
cout << "平均查找长度:" << 1 + (load_factor) / 2 << endl;
} //if
else
cout << "查找失败" << endl;
system("pause"); //暂停
}
//二叉排序树类
class BiSortTree{
public:
BiSortTree(datatype a[], int n); //带参构造函数,对树初始化
~BiSortTree(){
//析构函数
Release(root);
}
BiNode* InsertBST(datatype data){
//函数重载,插入数据域data
return InsertBST(root, data);
}
BiNode* SearchBST(string word){
//函数重载,查找值为word的结点
return SearchBST(root, word);
}
void printf(); //输出函数
private:
void Release(BiNode* bt); //释放空间
BiNode* InsertBST(BiNode* bt, datatype data); //插入数据域data
BiNode* SearchBST(BiNode* bt, string word); //查找值为word的结点
void InOrder(BiNode* bt); //中序遍历函数调用
BiNode* root; //二叉排序树的根指针
};
//构造函数
BiSortTree::BiSortTree(datatype a[], int n) {
root = NULL; //根指针置空
for (int i = 0; i < n; i++)
root = InsertBST(root, a[i]); //遍历,插入数据
}
//输出函数
void BiSortTree::InOrder(BiNode* bt){
//递归输出二叉排序树
ofstream fout; //文件写操作 内存写入存储设备
fout.open("outfile4.txt", ios_base::out | ios_base::app); //打开文件并将内容追加到文件尾
if (bt == NULL) //递归调用的结束条件,根指针为空
return; //退出函数
else{
InOrder(bt->lchild); //中序递归遍历bt的左子树
cout << bt->data.frequency << "\t" << bt->data.word << endl; //访问根结点bt的数据域,输出到屏幕
fout << bt->data.frequency << "\t" << bt->data.word << endl; //访问根结点bt的数据域,输出到文件
fout.close(); //关闭文件
InOrder(bt->rchild); //中序递归遍历bt的右子树
} //else
}
//输出二叉排序树到屏幕和outfile4.txt
void BiSortTree::printf() {
system("cls"); //清屏
ofstream fout; //文件写操作 内存写入存储设备
fout.open("outfile4.txt");//打开文件
fout << "单词总数为:" << sum << endl;
fout << "词频" << "\t" << "单词" << endl;
InOrder(root); //输出函数
system("pause"); //暂停
return; //退出函数
}
//递归查找函数,返回指针
BiNode* BiSortTree::SearchBST(BiNode* bt, string word){
if (bt == NULL)
return NULL; //未找到,返回NULL
if (bt->data.word == word)
return bt; //找到word,返回该指针
else if (bt->data.word > word) //数据大于word
return SearchBST(bt->lchild, word); //递归查找左子树
else //数据小于word
return SearchBST(bt->rchild, word); //递归查找右子树
}
//递归插入函数
BiNode* BiSortTree::InsertBST(BiNode* bt, datatype data){
if (bt == NULL){
//找到插入位置
BiNode* s = new BiNode; //生成一个新的储存空间
s->data = data; //为数据域赋值
s->lchild = NULL; //左孩子指针置空
s->rchild = NULL; //右孩子指针置空
bt = s; //根指针更新
return bt; //返回根指针
} //if
else if (WordTransition(bt->data.word) > WordTransition(data.word)){
//根节点数据大于要插入的数据
bt->lchild = InsertBST(bt->lchild, data); //更新左孩子指针
return bt; //返回根指针
} //else if
else{
//根节点数据小于要插入的数据
bt->rchild = InsertBST(bt->rchild, data); //更新有孩子指针
return bt; //返回根指针
} //else
}
//递归析构函数
void BiSortTree::Release(BiNode* bt){
if (bt == NULL)
return; //根指针为空直接退出
else {
Release(bt->lchild); //释放左子树
Release(bt->rchild); //释放右子树
delete bt; //释放根结点
}
}
// 二叉排序树菜单
void BiTreeMenu(){
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---二叉排序树查找---" << endl;
cout << "1.二叉排序树的顺序查找" << endl;
cout << "2.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
BitreeLocateMenu(); //二叉排序树查找菜单
break; //退出switch
case 2:
return; //退出函数
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
} //switch
} //while
}
//二叉排序树的顺序查找菜单
void BitreeLocateMenu(){
BiSortTree B(WF,sum);
while(true){
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---基于二叉排序树的顺序查找---" << endl;
cout << "1.词频统计" << endl;
cout << "2.单词查找" << endl;
cout << "3.返回上一级" << endl;
cout << "请按相应的数字键进行选择:" << endl;
int n;
cin >> n;
switch (n){
case 1:
B.printf();
break;
case 2:
BitreeWordLocMenu(); //二叉排序树查找单词菜单
break;
case 3:
return; //退出函数
default:
cout << "输入的不是有效符号,请重新输入" << endl;
system("pause"); //暂停
} //switch
} //while
}
//二叉排序树查找单词菜单
void BitreeWordLocMenu(){
BiSortTree B(WF,sum);
system("cls"); //清屏
cout << "*******************基于不同策略的英文单词的词频统计和检索系统*******************" << endl;
cout << "---二叉排序单词查找---" << endl;
cout << "请输入要查找的单词:";
string word;
cin >> word;
auto start = system_clock::now(); //开始时间
B.SearchBST(word);
duration<double> diff = system_clock::now() - start; //现在时间 - 开始时间
BiNode* p = NULL; //指针置空
p = B.SearchBST(word);
if (p != NULL) {
cout << "此单词为:" << p->data.word << endl;
cout << "此单词的词频:" << p->data.frequency << endl;
cout << "查找该单词所花费的时间:" << (diff.count())*1000 << "毫秒" << endl;
cout << "平均查找长度:" << sum << endl;
} //if
else
cout << "查找失败" << endl;
system("pause"); //暂停
}
六、运行结果
这里通过查找同一个单词来分辨不同查找方式的效率









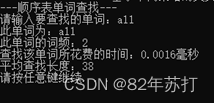
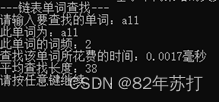
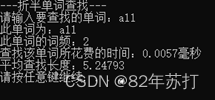

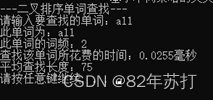

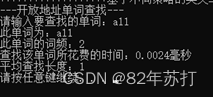
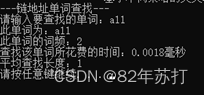

七、总结
通过这次实验,让我对顺序表、链表、二叉排序树、连地址哈希表和开放地址哈希表的结构有了更深刻的认识;学会如何去使用基于以上结构的顺序查找、折半查找等;还学会了如何输出查找时间以及他们的ASL(平均查找长度)