项目背景
- 每个系统都有日志,当系统出现问题时,需要通过日志解决问题
- 当系统机器比较少时,登陆到服务器上查看即可满足
- 当系统机器规模巨大,登陆到机器上查看几乎不现实
当然即使是机器规模不大,一个系统通常也会涉及到多种语言的开发,拿我们公司来说,底层是通过c++开发的,而也业务应用层是通过Python开发的,并且即使是C++也分了很多级别应用,python这边同样也是有多个应用,那么问题来了,每次系统出问题了,如何能够迅速查问题? 好一点的情况可能是python应用层查日志发现是系统底层处理异常了,于是又叫C++同事来查,如果C++这边能够迅速定位出错误告知python层这边还好,如果错误好排查,可能就是各个开发层的都在一起查到底是哪里引起的。当然可能这样说比较笼统,但是却引发了一个问题:
- 当系统出现问题后,如何根据日志迅速的定位问题出在一个应用层?
- 在平常的工作中如何根据日志分析出一个请求到系统主要在那个应用层耗时较大?
- 在平常的工作中如何获取一个请求到达系统后在各个层测日志汇总?
针对以上问题,我们想要实现的一个解决方案是:
- 把机器上的日志实时收集,统一的存储到中心系统
- 然后再对这些日志建立索引,通过搜索即可以找到对应日志
- 通过提供界面友好的web界面,通过web即可以完成日志搜索
关于实现这个系统时可能会面临的问题:
- 实时日志量非常大,每天几十亿条(虽然现在我们公司的系统还没达到这个级别)
- 日志准实时收集,延迟控制在分钟级别
- 能够水平可扩展
关于日志收集系统,业界的解决方案是ELK

ELK的解决方案是通用的一套解决方案,所以不免就会产生以下的几个问题:
- 运维成本高,每增加一个日志收集,都需要手动修改配置
- 监控缺失,无法准确获取logstash的状态
- 无法做定制化开发以及维护
针对这种情况,其实我们想要的系统是agent可以动态的获取某个服务器我们需要监控哪些日志
以及那些日志我们需要收集,并且当我们需要收集日志的服务器下线了,我们可以动态的停止收集
当然这些实现的效果最终也是通过web界面呈现。
日志收集系统设计
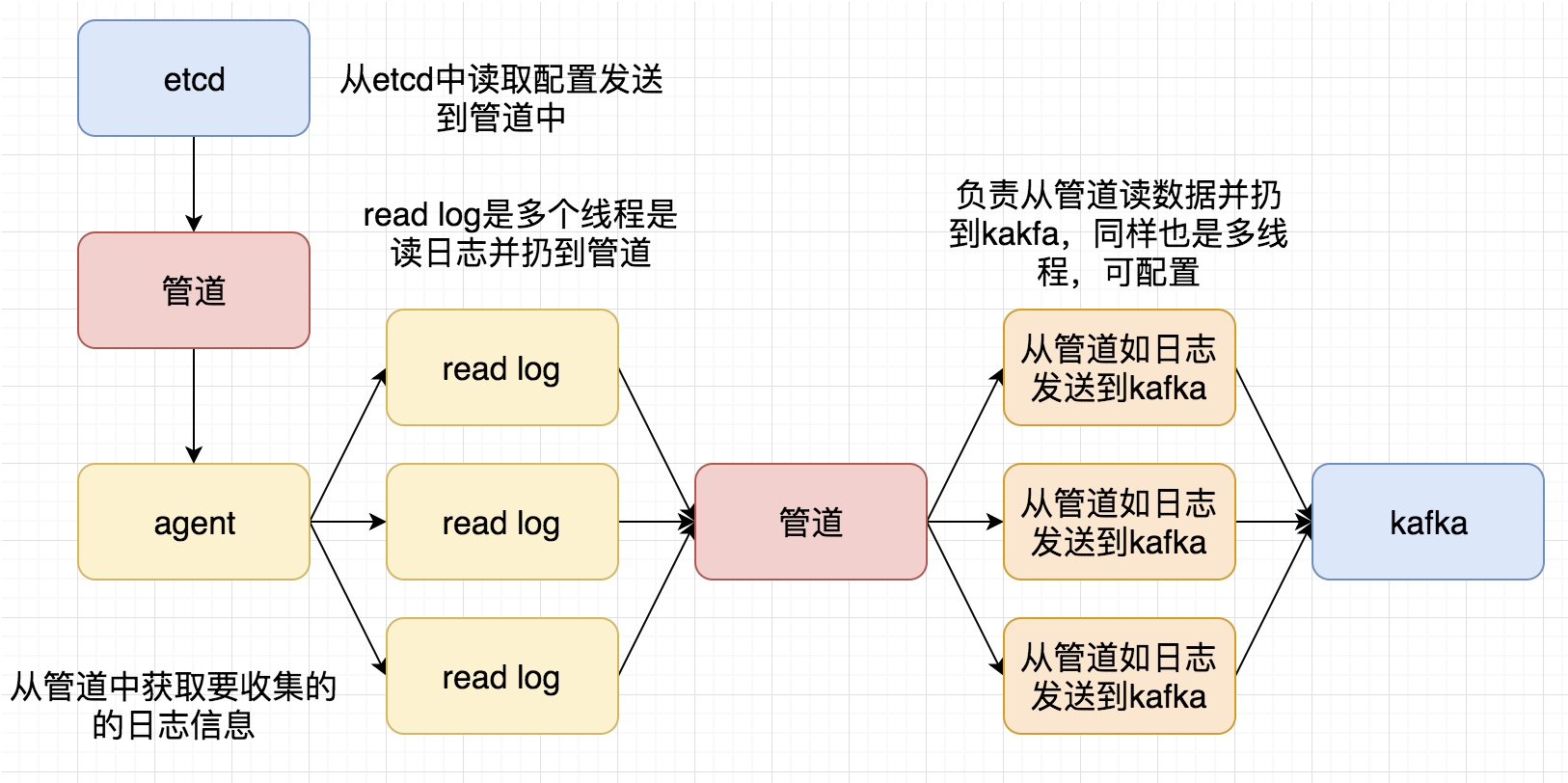
主要的架构图为
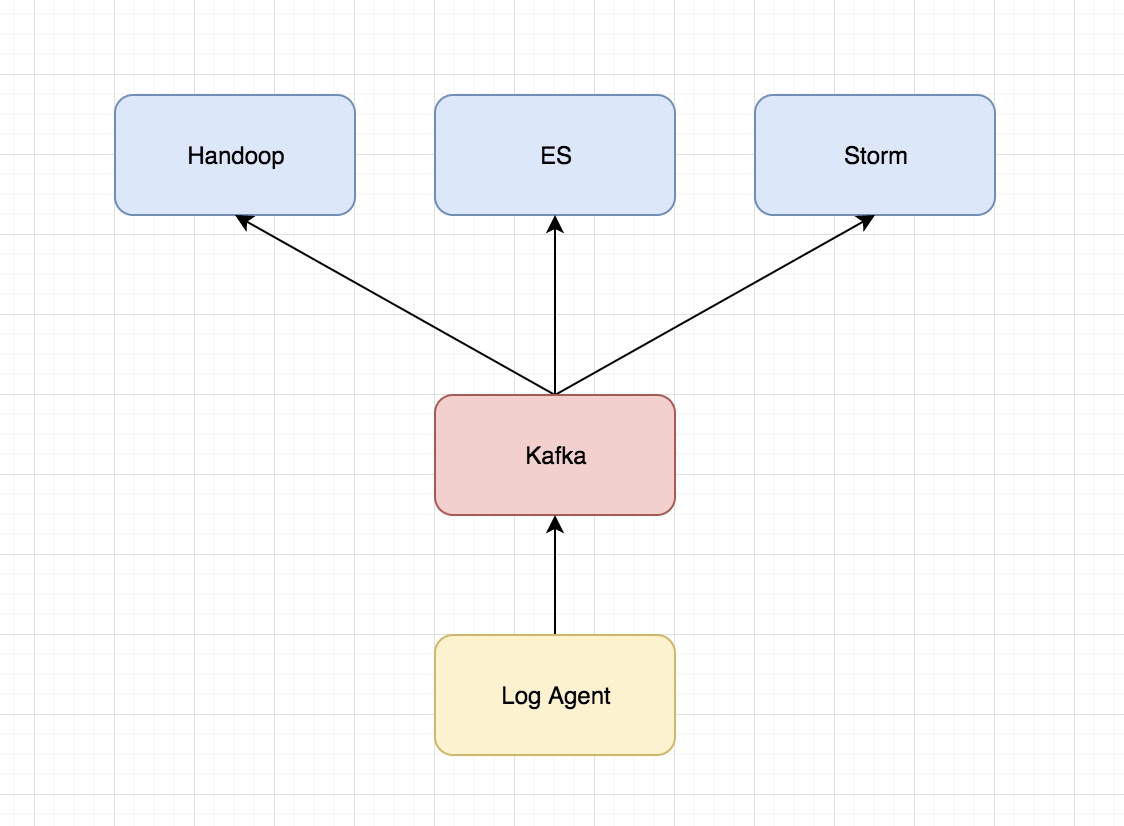
关于各个组件的说明:
- Log Agent,日志收集客户端,用来收集服务器上的日志
- Kafka,高吞吐量的分布式队列,linkin开发,apache顶级开源项目
- ES,elasticsearch,开源的搜索引擎,提供基于http restful的web接口
- Hadoop,分布式计算框架,能够对大量数据进行分布式处理的平台
关于Kakfa的介绍
Apache Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 Kafka适合离线和在线消息消费。 Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 Kafka构建在ZooKeeper同步服务之上。 它与Apache Storm和Spark非常好地集成,用于实时流式数据分析。

注:这里关于Kafka并不会介绍太多,只是对基本的内容和应用场景的说明,毕竟展开来说,这里的知识也是费非常多的
Kafka中有几个基本的消息术语需要了解:
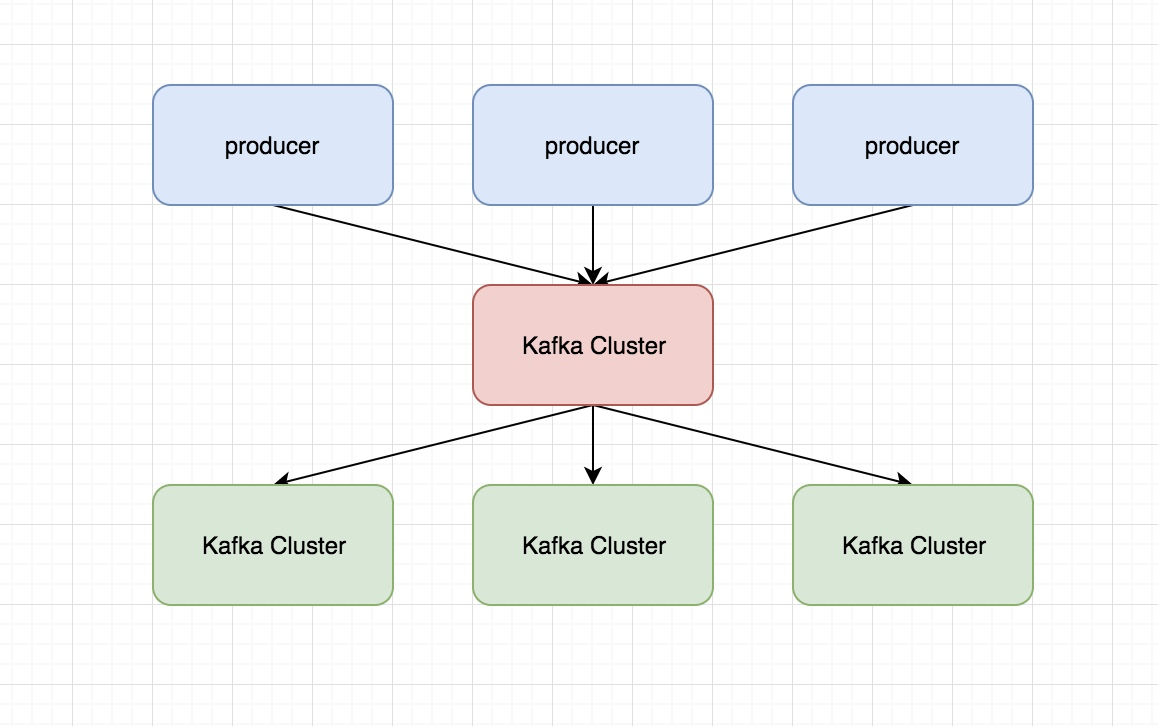
- Kafka将消息以topic为单位进行归纳。
- 将向Kafka topic发布消息的程序成为producers.
- 将预订topics并消费消息的程序成为consumer.
- Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker.
Kafka的优点:
- 可靠性 - Kafka是分布式,分区,复制和容错的。
- 可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
- 耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
- 性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。
Kafka非常快,并保证零停机和零数据丢失。
Kafka的应用场景:
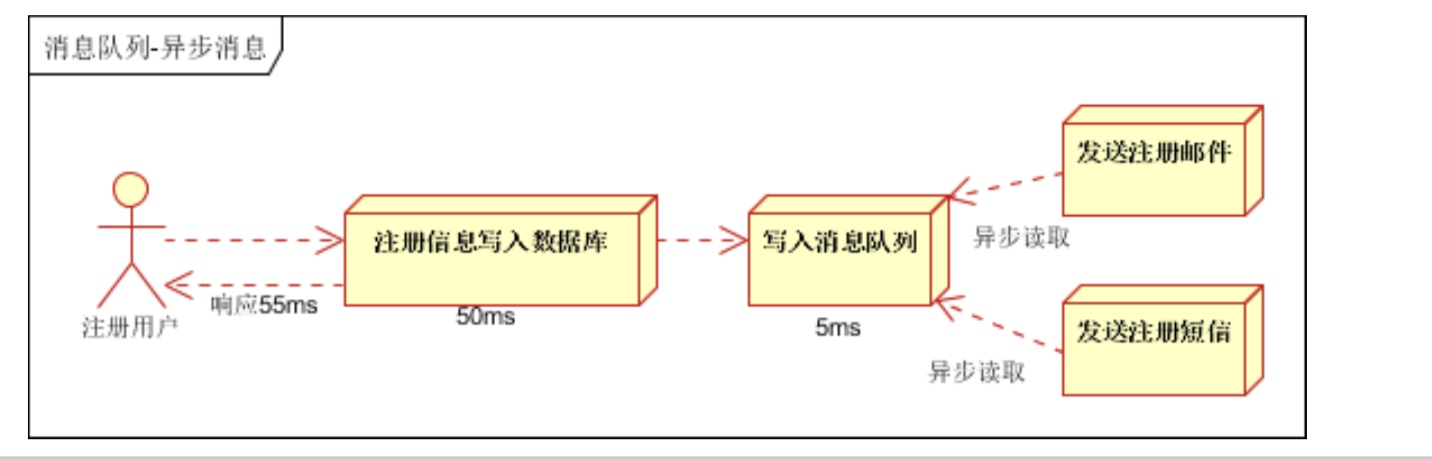
- 异步处理, 把非关键流程异步化,提高系统的响应时间和健壮性

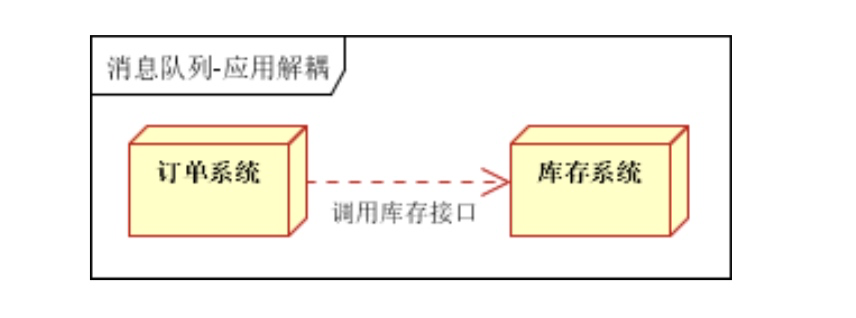
- 应用解耦,通过消息队列

- 流量削峰
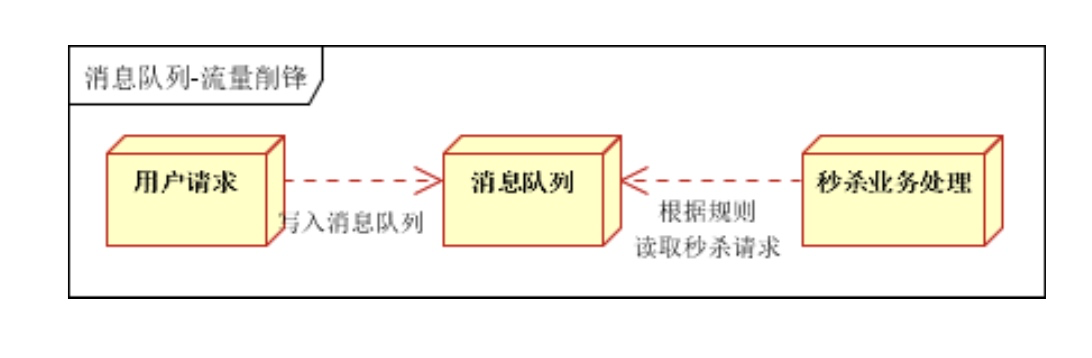
关于ZooKeeper介绍
ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
Apache ZooKeeper是由集群(节点组)使用的一种服务,用于在自身之间协调,并通过稳健的同步技术维护共享数据。ZooKeeper本身是一个分布式应用程序,为写入分布式应用程序提供服务。
ZooKeeper主要包含几下几个组件:
- Client(客户端):我们的分布式应用集群中的一个节点,从服务器访问信息。对于特定的时间间隔,每个客户端向服务器发送消息以使服务器知道客户端是活跃的。类似地,当客户端连接时,服务器发送确认码。如果连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。
- Server(服务器):服务器,我们的ZooKeeper总体中的一个节点,为客户端提供所有的服务。向客户端发送确认码以告知服务器是活跃的。
- Ensemble:ZooKeeper服务器组。形成ensemble所需的最小节点数为3。
- Leader: 服务器节点,如果任何连接的节点失败,则执行自动恢复。Leader在服务启动时被选举。
- Follower:跟随leader指令的服务器节点。
ZooKeeper的应用场景:
- 服务注册&服务发现

- 配置中心
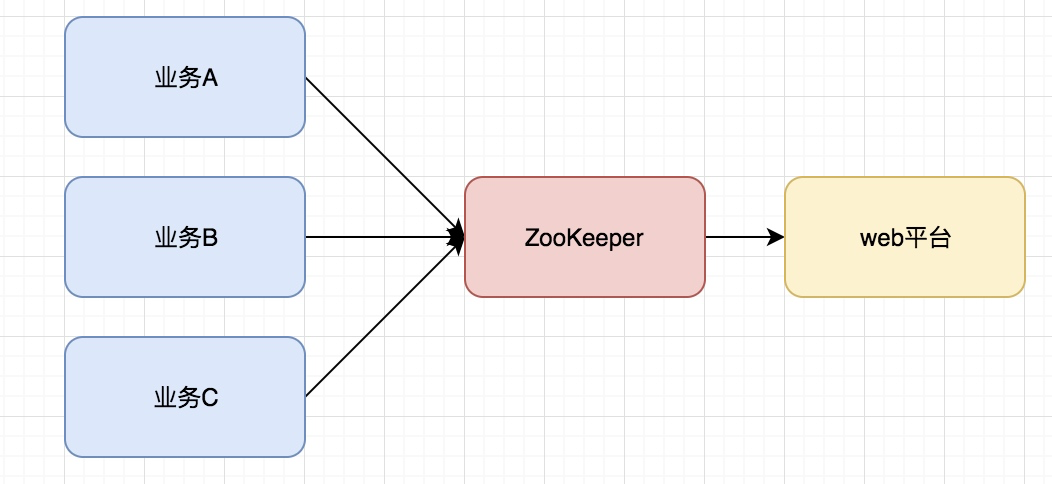
- 分布式锁
Zookeeper是强一致的多个客户端同时在Zookeeper上创建相同znode,只有一个创建成功
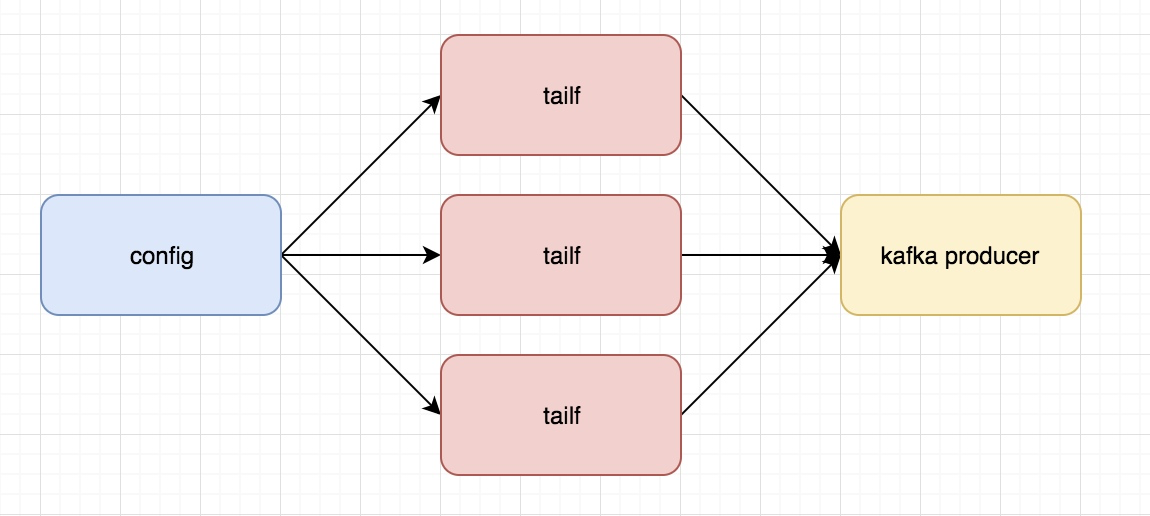
关于Log Agent
这个就是我们后面要通过代码实现的一步分内容,主要实现的功能是:
类似于我们在linux下通过tail的方法读日志文件,讲读取的内容发给Kafka
这里需要知道的是,我们这里的tailf是可以动态变化的,当配置文件发生变化是,可以通知我们程序自动增加需要增加的tailf去获取相应的日志并发给kafka producer
主要由一下几部目录组成:
- Kafka
- tailf
- configlog
小结
以上是对整个要开发的系统的一个总的概括,以及架构的一个构建,并且各个组件的实现,接下来会一个一个实现每个部分的功能,下一篇文章会实现上述组件中log Agent的开发
关于zookeeper+kafka
我们需要先把两者启动,先启动zookeeper,再启动kafka
启动ZooKeeper:./bin/zkServer.sh start
启动kafka:./bin/kafka-server-start.sh ./config/server.properties
操作kafka需要安装一个包:go get github.com/Shopify/sarama
写一个简单的代码,通过go调用往kafka里扔数据:

package main import ( "github.com/Shopify/sarama" "fmt" ) func main() { config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll config.Producer.Partitioner = sarama.NewRandomPartitioner config.Producer.Return.Successes = true msg := &sarama.ProducerMessage{} msg.Topic = "nginx_log" msg.Value = sarama.StringEncoder("this is a good test,my message is zhaofan") client,err := sarama.NewSyncProducer([]string{"192.168.0.118:9092"},config) if err != nil{ fmt.Println("producer close err:",err) return } defer client.Close() pid,offset,err := client.SendMessage(msg) if err != nil{ fmt.Println("send message failed,",err) return } fmt.Printf("pid:%v offset:%v\n",pid,offset) }
config.Producer.RequiredAcks = sarama.WaitForAll 这里表示是在给kafka扔数据的时候是否需要确认收到kafka的ack消息
msg.Topic = "nginx_log" 因为kafka是一个分布式系统,假如我们要读的是nginx日志,apache日志,我们可以根据topic做区分,同时也是我们也可以有不同的分区
我们将上述代码执行一下,就会往kafka中扔一条消息,可以通过kakfa中自带的消费者命令查看:
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic nginx_log --from-beginning

我们可以将最后的代码稍微更改一下,更改为循环发送:
for{ pid,offset,err := client.SendMessage(msg) if err != nil{ fmt.Println("send message failed,",err) return } fmt.Printf("pid:%v offset:%v\n",pid,offset) time.Sleep(2*time.Second) }
这样当我们再次执行的程序的时候,我们可以看到客户端在不停的消费到数据:
这样我们就实现一个kakfa的生产者的简单的demo
接下来我们还需要知道一个工具的使用tailf
tailf
我们的agent需要读日志目录下的日志文件,而日志文件是不停的增加并且切换文件的,所以我们就需要借助于tailf这个包来读文件,当然这里的tailf和linux里的tail -f命令虽然不同,但是效果是差不多的,都是为了获取日志文件新增加的内容。
而我们的客户端非常重要的一个地方就是要读日志文件并且将读到的日志文件推送到kafka
这里需要我们下载一个包:go get github.com/hpcloud/tail
我们通过下面一个例子对这个包进行一个基本的使用,更详细的api说明看:https://godoc.org/github.com/hpcloud/tail
package main import ( "github.com/hpcloud/tail" "fmt" "time" ) func main() { filename := "/Users/zhaofan/go_project/src/go_dev/13/tailf/my.log" tails,err := tail.TailFile(filename,tail.Config{ ReOpen:true, Follow:true, Location:&tail.SeekInfo{Offset:0,Whence:2}, MustExist:false, Poll:true, }) if err !=nil{ fmt.Println("tail file err:",err) return } var msg *tail.Line var ok bool for true{ msg,ok = <-tails.Lines if !ok{ fmt.Printf("tail file close reopen,filenam:%s\n",tails,filename) time.Sleep(100*time.Millisecond) continue } fmt.Println("msg:",msg.Text) } }
最终实现的效果是当你文件里面添加内容后,就可以不断的读取文件中的内容
日志库的使用
这里是通过beego的日志库实现的,beego的日志库是可以单独拿出来用的,还是非常方便的,使用例子如下:
package main import ( "github.com/astaxie/beego/logs" "encoding/json" "fmt" ) func main() { config := make(map[string]interface{}) config["filename"] = "/Users/zhaofan/go_project/src/go_dev/13/log/logcollect.log" config["level"] = logs.LevelTrace configStr,err := json.Marshal(config) if err != nil{ fmt.Println("marshal failed,err:",err) return } logs.SetLogger(logs.AdapterFile,string(configStr)) logs.Debug("this is a debug,my name is %s","stu01") logs.Info("this is a info,my name is %s","stu02") logs.Trace("this is trace my name is %s","stu03") logs.Warn("this is a warn my name is %s","stu04") }
简单版本logagent的实现
这里主要是先实现核心的功能,后续再做优化和改进,主要实现能够根据配置文件中配置的日志路径去读取日志并将读取的实时推送到kafka消息队列中
关于logagent的主要结构如下:
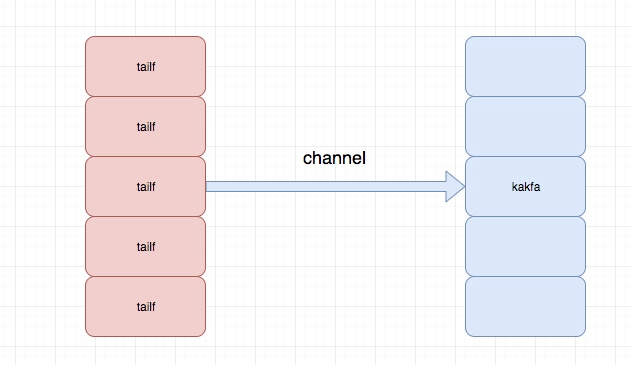
程序目录结构为:
├── conf
│ └── app.conf
├── config.go
├── kafka.go
├── logs
│ └── logcollect.log
├── main.go
└── server.go
app.conf :配置文件
config.go:用于初始化读取配置文件中的内容,这里的配置文件加载是通过之前自己实现的配置文件热加载包处理的,博客地址:http://www.cnblogs.com/zhaof/p/8593204.html
logcollect.log:日志文件
kafka.go:对kafka的操作,包括初始化kafka连接,以及给kafka发送消息
server.go:主要是tail 的相关操作,用于去读日志文件并将内容放到channel中
所以这里我们主要的代码逻辑或者重要的代码逻辑就是kafka.go 以及server.go
kafka.go代码内容为:
// 这里主要是kafak的相关操作,包括了kafka的初始化,以及发送消息的操作 package main import ( "github.com/Shopify/sarama" "github.com/astaxie/beego/logs" ) var ( client sarama.SyncProducer kafkaSender *KafkaSender ) type KafkaSender struct { client sarama.SyncProducer lineChan chan string } // 初始化kafka func NewKafkaSender(kafkaAddr string)(kafka *KafkaSender,err error){ kafka = &KafkaSender{ lineChan:make(chan string,100000), } config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll config.Producer.Partitioner = sarama.NewRandomPartitioner config.Producer.Return.Successes = true client,err := sarama.NewSyncProducer([]string{kafkaAddr},config) if err != nil{ logs.Error("init kafka client failed,err:%v\n",err) return } kafka.client = client for i:=0;i<appConfig.KafkaThreadNum;i++{ // 根据配置文件循环开启线程去发消息到kafka go kafka.sendToKafka() } return } func initKafka()(err error){ kafkaSender,err = NewKafkaSender(appConfig.kafkaAddr) return } func (k *KafkaSender) sendToKafka(){ //从channel中读取日志内容放到kafka消息队列中 for v := range k.lineChan{ msg := &sarama.ProducerMessage{} msg.Topic = "nginx_log" msg.Value = sarama.StringEncoder(v) _,_,err := k.client.SendMessage(msg) if err != nil{ logs.Error("send message to kafka failed,err:%v",err) } } } func (k *KafkaSender) addMessage(line string)(err error){ //我们通过tailf读取的日志文件内容先放到channel里面 k.lineChan <- line return }
server.go的代码为:
package main import ( "github.com/hpcloud/tail" "fmt" "sync" "github.com/astaxie/beego/logs" "strings" ) type TailMgr struct { //因为我们的agent可能是读取多个日志文件,这里通过存储为一个map tailObjMap map[string]*TailObj lock sync.Mutex } type TailObj struct { //这里是每个读取日志文件的对象 tail *tail.Tail offset int64 //记录当前位置 filename string } var tailMgr *TailMgr var waitGroup sync.WaitGroup func NewTailMgr()(*TailMgr){ tailMgr = &TailMgr{ tailObjMap:make(map[string]*TailObj,16), } return tailMgr } func (t *TailMgr) AddLogFile(filename string)(err error){ t.lock.Lock() defer t.lock.Unlock() _,ok := t.tailObjMap[filename] if ok{ err = fmt.Errorf("duplicate filename:%s\n",filename) return } tail,err := tail.TailFile(filename,tail.Config{ ReOpen:true, Follow:true, Location:&tail.SeekInfo{Offset:0,Whence:2}, MustExist:false, Poll:true, }) tailobj := &TailObj{ filename:filename, offset:0, tail:tail, } t.tailObjMap[filename] = tailobj return } func (t *TailMgr) Process(){ //开启线程去读日志文件 for _, tailObj := range t.tailObjMap{ waitGroup.Add(1) go tailObj.readLog() } } func (t *TailObj) readLog(){ //读取每行日志内容 for line := range t.tail.Lines{ if line.Err != nil { logs.Error("read line failed,err:%v",line.Err) continue } str := strings.TrimSpace(line.Text) if len(str)==0 || str[0] == '\n'{ continue } kafkaSender.addMessage(line.Text) } waitGroup.Done() } func RunServer(){ tailMgr = NewTailMgr() // 这一部分是要调用tailf读日志文件推送到kafka中 for _, filename := range appConfig.LogFiles{ err := tailMgr.AddLogFile(filename) if err != nil{ logs.Error("add log file failed,err:%v",err) continue } } tailMgr.Process() waitGroup.Wait() }
可以整体演示一下代码实现的效果,当我们运行程序之后我配置文件配置的目录为:
log_files=/app/log/a.log,/Users/zhaofan/a.log
我通过一个简单的代码对对a.log循环追加内容,你可以从kafka的客户端消费力看到内容了:
完成的代码地址:https://github.com/pythonsite/logagent
小结
这次只是实现logagent的核心功能,实现了从日志文件中通过多个线程获取要读的日志内容,这里借助了tailf,并将获取的内容放到channel中,kafka.go会从channel中取出日志内容并放到kafka的消息队列中
这里并没有做很多细致的处理,下一篇文章会在这个代码的基础上进行改进。同时现在的配置文件的方式也不是最佳的,每次改动配置文件都需要重新启动程序,后面将通过etcd的方式。
再次整理了一下这个日志收集系统的框,如下图

这次要实现的代码的整体逻辑为:
完整代码地址为: https://github.com/pythonsite/logagent
etcd介绍
高可用的分布式key-value存储,可以用于配置共享和服务发现
类似的项目:zookeeper和consul
开发语言:go
接口:提供restful的接口,使用简单
实现算法:基于raft算法的强一致性,高可用的服务存储目录
etcd的应用场景:
- 服务发现和服务注册
- 配置中心(我们实现的日志收集客户端需要用到)
- 分布式锁
- master选举
官网对etcd的有一个非常简明的介绍:

etcd搭建:
下载地址:https://github.com/coreos/etcd/releases/
根据自己的环境下载对应的版本然后启动起来就可以了
启动之后可以通过如下命令验证一下:
[root@localhost etcd-v3.2.18-linux-amd64]# ./etcdctl set name zhaofan zhaofan [root@localhost etcd-v3.2.18-linux-amd64]# ./etcdctl get name zhaofan [root@localhost etcd-v3.2.18-linux-amd64]#
context 介绍和使用
其实这个东西翻译过来就是上下文管理,那么context的作用是做什么,主要有如下两个作用:
- 控制goroutine的超时
- 保存上下文数据
通过下面一个简单的例子进行理解:
package main import ( "fmt" "time" "net/http" "context" "io/ioutil" ) type Result struct{ r *http.Response err error } func process(){ ctx,cancel := context.WithTimeout(context.Background(),2*time.Second) defer cancel() tr := &http.Transport{} client := &http.Client{Transport:tr} c := make(chan Result,1) req,err := http.NewRequest("GET","http://www.google.com",nil) if err != nil{ fmt.Println("http request failed,err:",err) return } // 如果请求成功了会将数据存入到管道中 go func(){ resp,err := client.Do(req) pack := Result{resp,err} c <- pack }() select{ case <- ctx.Done(): tr.CancelRequest(req) fmt.Println("timeout!") case res := <-c: defer res.r.Body.Close() out,_:= ioutil.ReadAll(res.r.Body) fmt.Printf("server response:%s",out) } return } func main() { process() }
写一个通过context保存上下文,代码例子如:
package main import ( "github.com/Go-zh/net/context" "fmt" ) func add(ctx context.Context,a,b int) int { traceId := ctx.Value("trace_id").(string) fmt.Printf("trace_id:%v\n",traceId) return a+b } func calc(ctx context.Context,a, b int) int{ traceId := ctx.Value("trace_id").(string) fmt.Printf("trace_id:%v\n",traceId) //再将ctx传入到add中 return add(ctx,a,b) } func main() { //将ctx传递到calc中 ctx := context.WithValue(context.Background(),"trace_id","123456") calc(ctx,20,30) }
结合etcd和context使用
关于通过go连接etcd的简单例子:(这里有个小问题需要注意就是etcd的启动方式,默认启动可能会连接不上,尤其你是在虚拟你安装,所以需要通过如下命令启动:
./etcd --listen-client-urls http://0.0.0.0:2371 --advertise-client-urls http://0.0.0.0:2371 --listen-peer-urls http://0.0.0.0:2381
)
package main import ( etcd_client "github.com/coreos/etcd/clientv3" "time" "fmt" ) func main() { cli, err := etcd_client.New(etcd_client.Config{ Endpoints:[]string{"192.168.0.118:2371"}, DialTimeout:5*time.Second, }) if err != nil{ fmt.Println("connect failed,err:",err) return } fmt.Println("connect success") defer cli.Close() }
下面一个例子是通过连接etcd,存值并取值
package main import ( "github.com/coreos/etcd/clientv3" "time" "fmt" "context" ) func main() { cli,err := clientv3.New(clientv3.Config{ Endpoints:[]string{"192.168.0.118:2371"}, DialTimeout:5*time.Second, }) if err != nil{ fmt.Println("connect failed,err:",err) return } fmt.Println("connect succ") defer cli.Close() ctx,cancel := context.WithTimeout(context.Background(),time.Second) _,err = cli.Put(ctx,"logagent/conf/","sample_value") cancel() if err != nil{ fmt.Println("put failed,err",err) return } ctx, cancel = context.WithTimeout(context.Background(),time.Second) resp,err := cli.Get(ctx,"logagent/conf/") cancel() if err != nil{ fmt.Println("get failed,err:",err) return } for _,ev := range resp.Kvs{ fmt.Printf("%s:%s\n",ev.Key,ev.Value) } }
关于context官网也有一个例子非常有用,用于控制开启的goroutine的退出,代码如下:
package main import ( "context" "fmt" ) func main() { // gen generates integers in a separate goroutine and // sends them to the returned channel. // The callers of gen need to cancel the context once // they are done consuming generated integers not to leak // the internal goroutine started by gen. gen := func(ctx context.Context) <-chan int { dst := make(chan int) n := 1 go func() { for { select { case <-ctx.Done(): return // returning not to leak the goroutine case dst <- n: n++ } } }() return dst } ctx, cancel := context.WithCancel(context.Background()) defer cancel() // cancel when we are finished consuming integers for n := range gen(ctx) { fmt.Println(n) if n == 5 { break } } }
关于官网文档中的WithDeadline演示的代码例子:
package main import ( "context" "fmt" "time" ) func main() { d := time.Now().Add(50 * time.Millisecond) ctx, cancel := context.WithDeadline(context.Background(), d) // Even though ctx will be expired, it is good practice to call its // cancelation function in any case. Failure to do so may keep the // context and its parent alive longer than necessary. defer cancel() select { case <-time.After(1 * time.Second): fmt.Println("overslept") case <-ctx.Done(): fmt.Println(ctx.Err()) } }
通过上面的代码有了一个基本的使用,那么如果我们通过etcd来做配置管理,如果配置更改之后,我们如何通知对应的服务器配置更改,通过下面例子演示:
package main import ( "github.com/coreos/etcd/clientv3" "time" "fmt" "context" ) func main() { cli,err := clientv3.New(clientv3.Config{ Endpoints:[]string{"192.168.0.118:2371"}, DialTimeout:5*time.Second, }) if err != nil { fmt.Println("connect failed,err:",err) return } defer cli.Close() // 这里会阻塞 rch := cli.Watch(context.Background(),"logagent/conf/") for wresp := range rch{ for _,ev := range wresp.Events{ fmt.Printf("%s %q : %q\n", ev.Type, ev.Kv.Key, ev.Kv.Value) } } }
实现一个kafka的消费者代码的简单例子:
package main import ( "github.com/Shopify/sarama" "strings" "fmt" "time" ) func main() { consumer,err := sarama.NewConsumer(strings.Split("192.168.0.118:9092",","),nil) if err != nil{ fmt.Println("failed to start consumer:",err) return } partitionList,err := consumer.Partitions("nginx_log") if err != nil { fmt.Println("Failed to get the list of partitions:",err) return } fmt.Println(partitionList) for partition := range partitionList{ pc,err := consumer.ConsumePartition("nginx_log",int32(partition),sarama.OffsetNewest) if err != nil { fmt.Printf("failed to start consumer for partition %d:%s\n",partition,err) return } defer pc.AsyncClose() go func(partitionConsumer sarama.PartitionConsumer){ for msg := range pc.Messages(){ fmt.Printf("partition:%d Offset:%d Key:%s Value:%s",msg.Partition,msg.Offset,string(msg.Key),string(msg.Value)) } }(pc) } time.Sleep(time.Hour) consumer.Close() }
但是上面的代码并不是最佳代码,因为我们最后是通过time.sleep等待goroutine的执行,我们可以更改为通过sync.WaitGroup方式实现
package main import ( "github.com/Shopify/sarama" "strings" "fmt" "sync" ) var ( wg sync.WaitGroup ) func main() { consumer,err := sarama.NewConsumer(strings.Split("192.168.0.118:9092",","),nil) if err != nil{ fmt.Println("failed to start consumer:",err) return } partitionList,err := consumer.Partitions("nginx_log") if err != nil { fmt.Println("Failed to get the list of partitions:",err) return } fmt.Println(partitionList) for partition := range partitionList{ pc,err := consumer.ConsumePartition("nginx_log",int32(partition),sarama.OffsetNewest) if err != nil { fmt.Printf("failed to start consumer for partition %d:%s\n",partition,err) return } defer pc.AsyncClose() go func(partitionConsumer sarama.PartitionConsumer){ wg.Add(1) for msg := range partitionConsumer.Messages(){ fmt.Printf("partition:%d Offset:%d Key:%s Value:%s",msg.Partition,msg.Offset,string(msg.Key),string(msg.Value)) } wg.Done() }(pc) } //time.Sleep(time.Hour) wg.Wait() consumer.Close() }
将客户端需要收集的日志信息放到etcd中
关于etcd处理的代码为:
package main import ( "github.com/coreos/etcd/clientv3" "time" "github.com/astaxie/beego/logs" "context" "fmt" ) var Client *clientv3.Client var logConfChan chan string // 初始化etcd func initEtcd(addr []string,keyfmt string,timeout time.Duration)(err error){ var keys []string for _,ip := range ipArrays{ //keyfmt = /logagent/%s/log_config keys = append(keys,fmt.Sprintf(keyfmt,ip)) } logConfChan = make(chan string,10) logs.Debug("etcd watch key:%v timeout:%v", keys, timeout) Client,err = clientv3.New(clientv3.Config{ Endpoints:addr, DialTimeout: timeout, }) if err != nil{ logs.Error("connect failed,err:%v",err) return } logs.Debug("init etcd success") waitGroup.Add(1) for _, key := range keys{ ctx,cancel := context.WithTimeout(context.Background(),2*time.Second) // 从etcd中获取要收集日志的信息 resp,err := Client.Get(ctx,key) cancel() if err != nil { logs.Warn("get key %s failed,err:%v",key,err) continue } for _, ev := range resp.Kvs{ logs.Debug("%q : %q\n", ev.Key, ev.Value) logConfChan <- string(ev.Value) } } go WatchEtcd(keys) return } func WatchEtcd(keys []string){ // 这里用于检测当需要收集的日志信息更改时及时更新 var watchChans []clientv3.WatchChan for _,key := range keys{ rch := Client.Watch(context.Background(),key) watchChans = append(watchChans,rch) } for { for _,watchC := range watchChans{ select{ case wresp := <-watchC: for _,ev:= range wresp.Events{ logs.Debug("%s %q : %q\n", ev.Type, ev.Kv.Key, ev.Kv.Value) logConfChan <- string(ev.Kv.Value) } default: } } time.Sleep(time.Second) } waitGroup.Done() } func GetLogConf()chan string{ return logConfChan }
同样的这里增加对了限速的处理,毕竟日志收集程序不能影响了当前业务的性能,所以增加了limit.go用于限制速度:
package main import ( "time" "sync/atomic" "github.com/astaxie/beego/logs" ) type SecondLimit struct { unixSecond int64 curCount int32 limit int32 } func NewSecondLimit(limit int32) *SecondLimit { secLimit := &SecondLimit{ unixSecond:time.Now().Unix(), curCount:0, limit:limit, } return secLimit } func (s *SecondLimit) Add(count int) { sec := time.Now().Unix() if sec == s.unixSecond { atomic.AddInt32(&s.curCount,int32(count)) return } atomic.StoreInt64(&s.unixSecond,sec) atomic.StoreInt32(&s.curCount, int32(count)) } func (s *SecondLimit) Wait()bool { for { sec := time.Now().Unix() if (sec == atomic.LoadInt64(&s.unixSecond)) && s.curCount == s.limit { time.Sleep(time.Microsecond) logs.Debug("limit is running,limit:%d s.curCount:%d",s.limit,s.curCount) continue } if sec != atomic.LoadInt64(&s.unixSecond) { atomic.StoreInt64(&s.unixSecond,sec) atomic.StoreInt32(&s.curCount,0) } logs.Debug("limit is exited") return false } }
小结
这次基本实现了日志收集的前半段的处理,后面将把日志扔到es中,并最终在页面上呈现