因为爬取起点目录页找不到各个章节的url,因此只能一章一章的往下爬
分析下起点网页html
首先导入相关jar包 (我用的是gradle)

上代码
url="https://read.qidian.com/chapter/6xbxCkvMZqw1/OCcwrQf_B4Qex0RJOkJclQ2";
//伪装浏览器
Document document = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36").timeout(500000).get();
//获得书名
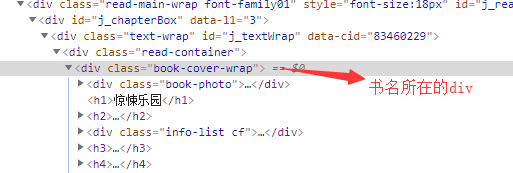
String bookName = document.getElementsByClass("book-cover-wrap").select("h1").text();
int i = 1;
//一直循环,直到找不到下一章url
while (true) {
//获取章节名
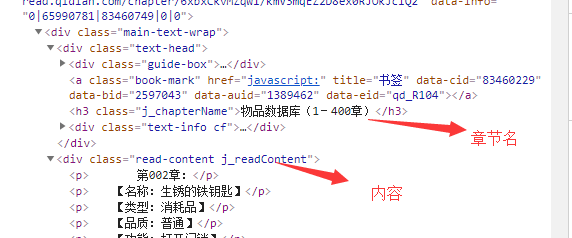
String name = document.select("h3[class = j_chapterName]").text();
//获取下一章的element
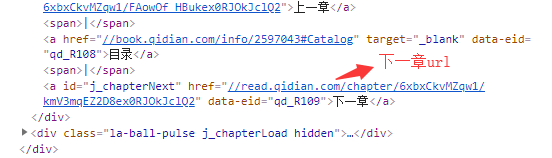
Element element = document.getElementById("j_chapterNext");
String nexturl;
//获取内容
String fiction = document.select("div[class = read-content j_readContent]").select("p").toString();
//正则替换<p></p>
String s = fiction.replaceAll("<\\/?p>", "");
if (element == null) {
break;
}
nexturl = "https:" + element.attr("href");
//is表示免费章节数(vip章节需要登录付费)loginUrl 表示vip章节的url
if(i==is){
i++;
nexturl = loginUrl;
}
if (i >= is) {
try {
//获取vip章节,并带头文件,可能报400,500
document = Jsoup.connect(nexturl).header("", "").header("","").header("", "").header("", "").timeout(60000).get();
} catch (Exception e) {
System.out.println("ss"+e.getMessage());
document = Jsoup.connect(nexturl).header("", "").header("", "").header("", "").header("", "").userAgent("").timeout(60000).get();
}
} else {
i++;
try {
document = Jsoup.connect(nexturl).timeout(60000).get();
} catch (Exception e) {
System.out.println("----------------------");
}
}
}