python爬取起点免费小说
按F12查看网页源代码:
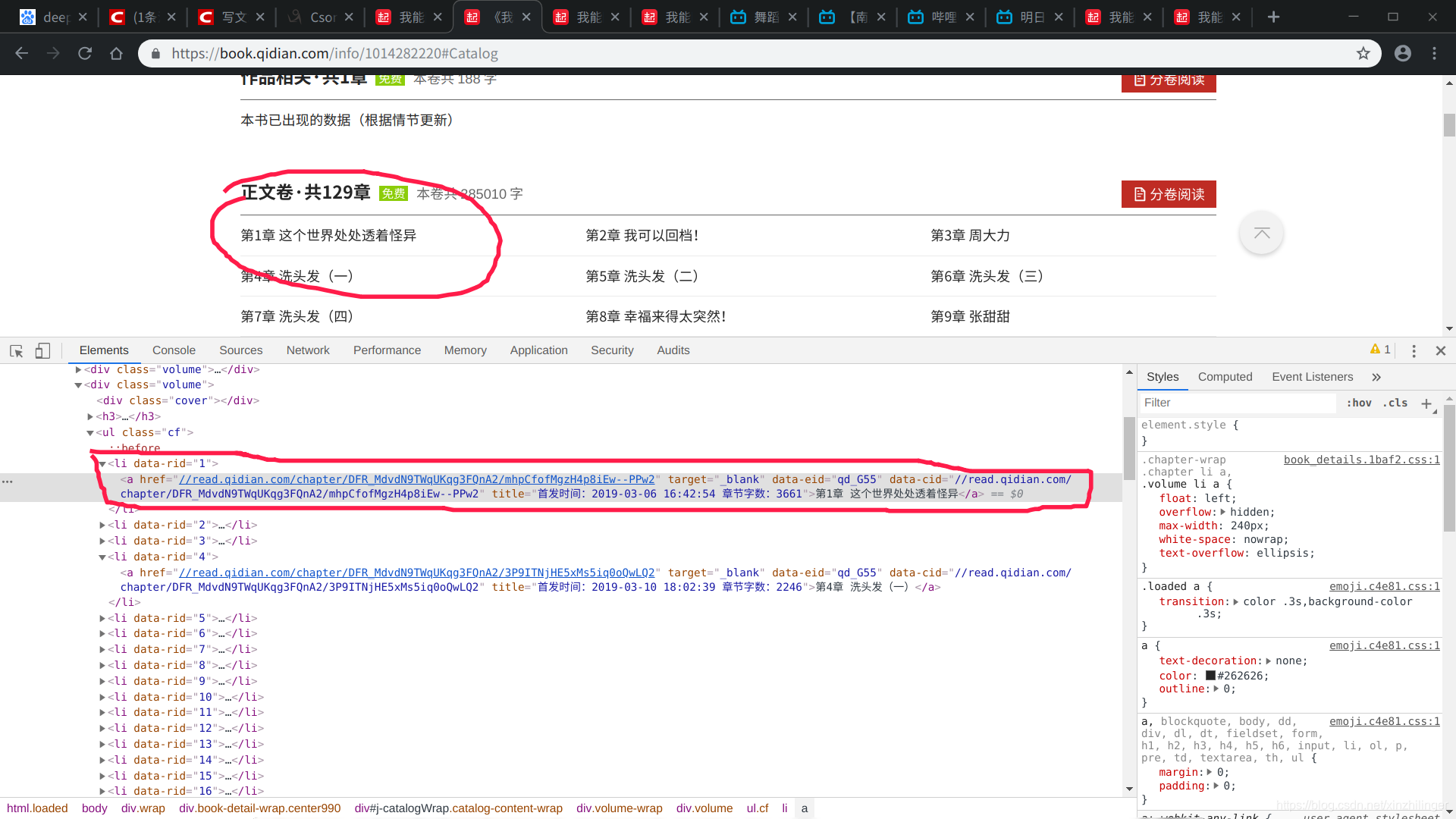
发现每一章小说链接在li中,这时可以提取每一章的链接:
def get_html(url):
r=requests.get(url)
html=BeautifulSoup(r.text,"html.parser")
return html
def get_url(html):
url_list=[]
ul_list=html.find_all("ul") #找到li的父亲标签ul
li_list=ul_list[4].contents #这里我省事,直接从源代码看到在列表第五个,也可以通过判断找到含有li的ul标签
# print(li_list[1])
for i in range(1,len(li_list),2):
url_list.append("https:"+li_list[i].a.attrs["href"])#将找到的li标签中的每一章的链接放入一个列表
# print(url_list)
return url_list
后续就是从每一章的链接中找到文本写入文本文档
不多说,上代码:
def get_text(url_list):
text1=""
text=" "
for i in range(len(url_list)):
html=get_html(url_list[i])
text_list=html.find_all("p")
for j in range(len(text_list)):
text1=text_list[j].text
if len(jin)>100:
break
jia=jia+jin
return text
def write_text(text):
path="起点小说.text"
with open(path,"w") as file:
file.write(text)
最后完整的代码:
import requests
from bs4 import BeautifulSoup
url="https://book.qidian.com/info/1014282220#Catalog"
def get_html(url):
r=requests.get(url)
r.encoding=r.apparent_encoding
html=BeautifulSoup(r.text,"html.parser")
return html
def get_url(html):
url_list=[]
ul_list=html.find_all("ul")
li_list=ul_list[4].contents
# print(li_list[1])
for i in range(1,len(li_list),2):
url_list.append("https:"+li_list[i].a.attrs["href"])
# print(url_list)
return url_list
def get_text(url_list):
text1=""
text=" "
for i in range(len(url_list)):
html=get_html(url_list[i])
text_list=html.find_all("p")
for j in range(len(text_list)):
text1=text_list[j].text
if len(jin)>100:
break
jia=jia+jin
return text
def write_text(text):
path="/home/jin/life/jin.text"
with open(path,"w") as file:
file.write(text)
def main():
html=get_html(url)
url_list=get_url(html)
text_list=get_text(url_list)
write_text(text_list)
main()