许多问题需要概率作为输出,逻辑回归是一种效率很高的概率计算机制。
虽然我在这里没有提及,但是各位对机器学习感兴趣的基本都会用到过mnist数据集。 在我们读取数据集的一般是这么写的
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)这里labels不再是一个值,而是独热码。
>>>print(mnist.train.labels)
array([[0., 0., 0., ..., 1., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]])这时候我们就需要进行逻辑回归。
mnist = input_data.read_data_sets('MNIST_data/', one_hot=False)则会返回固定值:
array([7, 3, 4, ..., 5, 6, 8], dtype=uint8)
大家可能发现了,逻辑回归与我们之前对经度和纬度进行的分箱有点类似,只不过这回变成判断数据落在哪个“箱”内而已。
文中给了我们一个例子,我们现在要创建一个逻辑回归模型来预测半夜狗叫的概率:
p(bark|night)
假设p(bark|night)为0.05,那么一年内就应该大概会叫 0.05*365次。
很多时候我们会将逻辑回归映射到二元分类问题的解决答案(例如垃圾邮件和非垃圾邮件)。
既然这个输出结果是概率,那么我们就要保证输出的值在0~1之间。这里我们需要一个激活函数,这个函数可以把 输入值映射到0~1区间。
activation_function = 1/(1+ e^(-z))
这个就是著名的sigmoid函数。在tf中可以使用
tf.nn.sigmoid()调用。
我们这里画一下图。
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
x = np.linspace(-10, 10, 1000)
y = tf.nn.sigmoid(x)
sess = tf.Session()
plt.figure(1)
plt.plot(x, sess.run(y))
plt.show()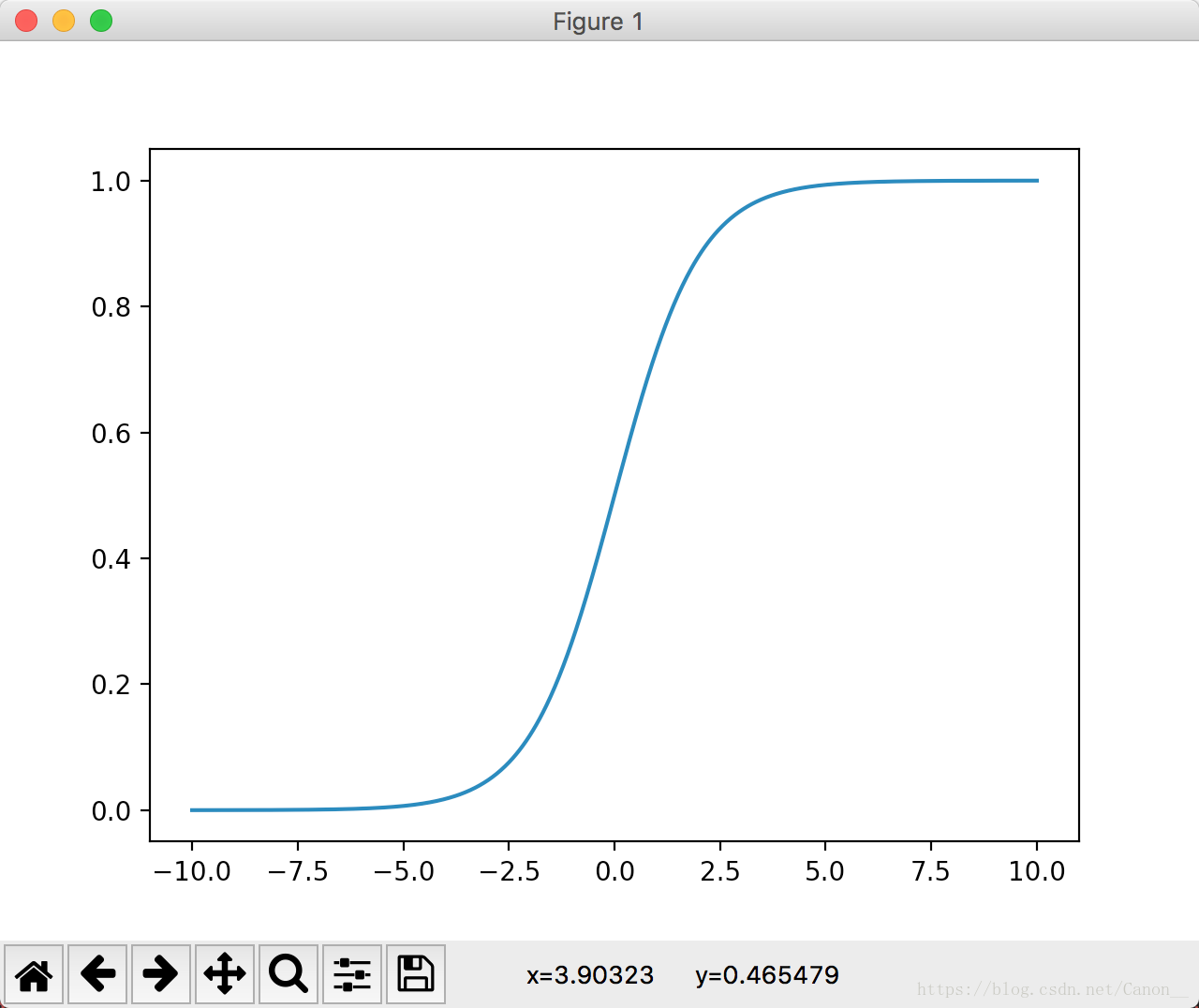
文中最后强调,这里的z叫做 对数几率,这个叫法是因为sigmoid的反函数,z=log(y/(1-y))。
知道用什么激活函数了,同样我们也需要重新设计loss算法。
在这之前我们一直使用RMSE(其实MSE使用的更多,但是原文为了loss便于我们观看,所以使用了RMSE,因此我们也一直沿用的RMSE)。
当我们的预测值越接近真实值的时候损失越小, 如果两者相等的话,那月 预测值-真实值 =0, loss也为0。我们为什么不直接使用MSE来预测呢?
我们这里假设 预测值为 prediction = [ 0.1, 0.3, 0.3, 0.7, 0.3]
真实值为 ys = [0, 0, 0, 1, 0]
我们这里用MSE来设计 loss = tf.reduce_mean(tf.square(prediction - ys))
这里的loss = (0.1^2 + 0.3^2 + 0.3^2 + 0.3^2 +0.3^2) /5 = 0.074
我们这里设计的loss,的确也反映了 预测值和真实值的变化,且预测值越接近真实值 loss越小。
但是这里有一个问题,不知道大家有没有发现呢?