前面三节,我们从最简单的一元线性回归到多元线性回归,讨论了,损失函数到底由那几部分组成(这点我觉很重要,因为它不仅仅存在线性回归中还存在其他机器学习中,因此有必要搞明白他,有兴趣的请看这篇文章),后面详细讨论了多元线性回归,主要介绍了多元线性回归的共线性问题,为了解决共线性问题引出了岭回归,然而岭回归存在缺点,因此又引出了lasso算法,此算法是解决共线性和选择特征很有效的方法(不懂的请看这篇文章),讲解了Lasso 算法的原理,下面就详解了lasso 的计算原理,通过使用LAR算法间接解决lasso 的计算问题,他们有很高的相似性,详解了相似的原因,本人认为LAR算法值得大家好好研究体会,因为这个算法使用了很高超的技巧去求解最优问题,计算量很低而且可以推广到高维特征,有兴趣的请看这篇文章,上面就是前三节的主要内容,下面开始根据机器学习实战进行学习:
先回顾一下简单的原理过程:

 我们知道了上面的式子就是最优估计了,使用最小二乘法就可以求解出来,但是并不是所有的都可以使用最小二乘法,前提需要保证上式可逆才能使用,
我们知道了上面的式子就是最优估计了,使用最小二乘法就可以求解出来,但是并不是所有的都可以使用最小二乘法,前提需要保证上式可逆才能使用,
其中和
代表的是同一个意思,好,下面我们就开始敲代码了:
#!/usr/bin/env/python
# -*- coding: utf-8 -*-
# Author: 赵守风
# File name: regression.py
# Time:2018/11/1
# Email:[email protected]
import numpy as np
# 读取数据
def loaddataset(filename):
numfeat = len(open(filename).readline().split('\t')) - 1 # 计算一个样本特征有几个
datmat = []
labelmat = []
fr = open(filename)
for line in fr.readlines(): # 读取数据,并把特征提取出来
linearr = []
curline = line.strip().split('\t')
for i in range(numfeat):
linearr.append(float(curline[i]))
datmat.append(linearr)
labelmat.append(float(curline[-1]))
return datmat, labelmat
# 求解ws
def standregres(xarr, yarr):
xmat = np.mat(xarr)
ymat = np.mat(yarr)
xTx = xmat.T * xmat
if np.linalg.det(xTx) == 0.0: #判断矩阵的行列式是否为0,如果为0说明矩阵不可逆
print('xTx矩阵不可逆')
return
ws = xTx.I * (xmat.T * ymat.T) # 这里会报错,原因是这里ymat需要转置一下
# ws = np.linalg.solve(xTx, xmat*ymat)
return ws
测试代码:
#!/usr/bin/env/python
# -*- coding: utf-8 -*-
# Author: 赵守风
# File name: test.py
# Time:2018/11/1
# Email:[email protected]
import regression
import matplotlib.pyplot as plt
import numpy as np
xarr, yarr = regression.loaddataset('ex0.txt')
print('xarr: ', xarr)
print('yarr: ', yarr)
ws = regression.standregres(xarr, yarr)
print('ws: ', ws)
xmat = np.mat(xarr)
ymat = np.mat(yarr)
plt.scatter(xmat[:,1].flatten().A[0],ymat.T[:,0].flatten().A[0])
plt.show()
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xmat[:,1].flatten().A[0],ymat.T[:,0].flatten().A[0])
xcopy = xmat.copy()
xcopy.sort(0)
yhat = xcopy* ws
ax.plot(xcopy[:,1],yhat)
plt.show()


我们发现拟合效果还行,只是没有把细节的变化表现出来即数据是锯齿状上升的,如何把细节表现出来呢?下面使用局部拟合就可以解决问题。
局部拟合:
所谓局部拟合,简单的来说就是在拟合时,引入权值,是拟合点的相邻的数据的权值增加,远离的数据的权值减小或者消除(容易过拟合),其实这个和通信里的滤波器差不多,滤波器的目的就是只让频带内的数据通过,其他的不通过,因此想达到这样的效果就需要引入权值函数,这个函数和很当前的数据相关,和邻边很近的数据也相关,即需要呈现‘带通’特性,此时最容易想到的就是核函数的高斯核函数或者径向基核函数具有这样的特性,如下:
我们的优化函数为:
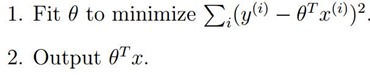
使用这个函数的效果就是我们上面的图的效果,只是测试细节的变化趋势忽略了,因此引入局部拟合即加入权值:
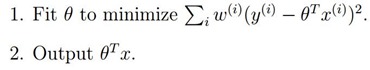
 为权值,从上面我们可以看出,如果很大,我们将很难去使得
为权值,从上面我们可以看出,如果很大,我们将很难去使得 小,所以如果很小,则它所产生的影响也就很小。
小,所以如果很小,则它所产生的影响也就很小。
我们w的权值通过高斯核引入,如下:
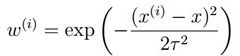
图形为:
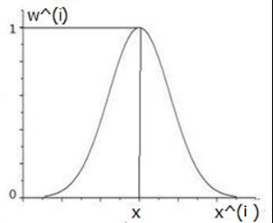
通过这里我们可以看到,每预测一个待预测样本数据时 ,靠近x的样本的数据的权值接近1,而远离x的权值趋向于0,这就是局部的意思,就是每加入一个数据,都会以局数据为准进行拟合,这样就可以把细节也突出了,我们看看,高斯核函数的的特性:

其中k就是上式的,调节
我们发现其选择临近数据的多少即权值为多少,可以很清楚的看到,权值可以决定哪些数据参与局部拟合,因此可以把数据的潜在规律也挖掘出来,但是局部拟合的缺点是增加了计算量,因为它每预测一个数据时,都会调用整个样本的数据,这和KNN工作机制差不多。好,下面我们看看代码实现和效果:
# 局部线性回归
def lwlr(testPoint, xArr, yArr, k=1.0):
xMat = np.mat(xArr)
yMat = np.mat(yArr).T
m = np.shape(xMat)[0] # 取矩阵的行数
weights = np.mat(np.eye((m))) # 创建一个对角矩阵,对角线为1,其他为0
for j in range(m): #next 2 lines create weights matrix
diffMat = testPoint - xMat[j,:] # 开始计算权值了
weights[j,j] = np.exp(diffMat*diffMat.T/(-2.0*k**2))
xTx = xMat.T * (weights * xMat)
if np.linalg.det(xTx) == 0.0:
print("矩阵不可逆")
return
ws = xTx.I * (xMat.T * (weights * yMat))
return testPoint * ws
def lwlrTest(testArr,xArr,yArr,k=1.0): #loops over all the data points and applies lwlr to each one
m = np.shape(testArr)[0]
yHat = np.zeros(m)
for i in range(m):
yHat[i] = lwlr(testArr[i],xArr,yArr,k)
return yHat
测试代码:
#!/usr/bin/env/python
# -*- coding: utf-8 -*-
# Author: 赵守风
# File name: test.py
# Time:2018/11/1
# Email:[email protected]
import regression
import matplotlib.pyplot as plt
import numpy as np
xarr, yarr = regression.loaddataset('ex0.txt')
print('xarr: ', xarr)
print('yarr: ', yarr)
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.scatter(xmat[:,1].flatten().A[0],ymat.T[:,0].flatten().A[0])
xcopy = xmat.copy()
xcopy.sort(0)
yhat = xcopy* ws
ax.plot(xcopy[:,1],yhat)
plt.show()
yhat1 = regression.lwlrTest(xarr,xarr, yarr, 0.03)
srtind = xmat[:,1].argsort(0)
xsort = xmat[srtind][:, 0, :]
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(xsort[:,1], yhat1[srtind])
ax.scatter(xmat[:,1].flatten().A[0],ymat.T[:,0].flatten().A[0],s=2,c='red')
plt.show()
yhat1 = regression.lwlrTest(xarr,xarr, yarr, 0.01)
srtind = xmat[:,1].argsort(0)
xsort = xmat[srtind][:, 0, :]
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(xsort[:,1], yhat1[srtind])
ax.scatter(xmat[:,1].flatten().A[0],ymat.T[:,0].flatten().A[0],s=2,c='blue')
plt.show()
yhat1 = regression.lwlrTest(xarr,xarr, yarr, 0.005)
srtind = xmat[:,1].argsort(0)
xsort = xmat[srtind][:, 0, :]
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(xsort[:,1], yhat1[srtind])
ax.scatter(xmat[:,1].flatten().A[0],ymat.T[:,0].flatten().A[0],s=2,c='blue')
plt.show()结果:

我们发现随着k值的减小,数据的细节特性也表现出来了,尤其在k=0.03时达到最好,而在小以后就出现过拟合了,机器学习实战好像讲反了,实际测试是这样的,从原理也能解释,就是说当k越小时,器参与的数据越少,因此更容易过拟合的,好,本节到这里,下一节继续讨论岭回归和lasso已经LAR算法的实现。