首先我们需要在网上下载Linux系统,我在这次安装过程中使用的CentOS-7系统
CentOS-7镜像文件下载地址: https://www.centos.org/download/
1. 选择好自己需要的版本

2. 安装CentOS系统,并安装图形化界面,方便操作
打开VMware,选择创建新的虚拟机

选择好虚拟机位置

然后一直点击下一步到安装完成。
开机后我们选择第一项,直接安装


选择网络和主机名,配置好网关

直接点击打开就好

再选择上图中的安装位置,直接进去点击完成就好,然后点击开始安装,并为虚拟机配置密码。
安装完成后点击重启。
接下来安装图形化界面,安装时间比较久。
执行命令: (中途若遇到黑屏无显示直接敲回车)
yum groupinstall "X Window System"


显示complete则说明安装成功
执行命令:yum groupinstall “GNOME Desktop”
输入startx进行图形化界面。(可能需要重启)
这样CentOS安装就完成了。接下来需要配置jdk
jdk下载地址: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
选择Linux系统版本的下载。
3. Jdk的安装配置
下载好后解压: tar -zxvf jdk-8u191-linux-x64.tar.gz -C /root/training/ 或者 tar -zxvf jdk-8u191-linux-x64.tar.gz

配置环境: vim /etc/profile在最后面添加:
#java environment
export JAVA_HOME=/root/training/jdk1.8.0_191
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin


4. Hadoop安装以配置
下载后解压: tar -zxvf hadoop-2.9.2.tar.gz -C /root/training/ 或则 tar -zxvf hadoop-2.9.2.tar.gz
环境配置: vi ~/.bash_profile
最后面添加:
JAVA_HOME=/root/training/jdk1.8.0_191
export JAVA_HOME
PATH=$JAVA_HOME/bin:$PATH
export PATH
HADOOP_HOME=/root/training/hadoop-2.9.2
export HADOOP_HOME
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH

让配置文件生效: source ~/.bash_profile
hadoop本地模式配置:
cd /root/training/hadoop-2.9.2/etc/hadoop/
vim hadoop-env.sh

mapreduce测试wordcount
cd /root/training/hadoop-2.9.2/share/hadoop/mapreduce/

创建输入输出文件和文件夹
mkdir -p /root/data/input
mkdir -p /root/data/output
vi /root/data/input/data.txt

写入语段用于测试
hadoop jar hadoop-mapreduce-examples-2.9.2.jar wordcount /root/data/input/data.txt /root/data/output/wc.txt

统计结果

其他两个也是一样的语法进行测试
wordmean测试
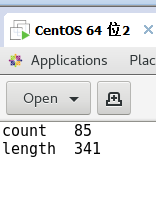
wordmedian测试

这样Hadoop本地模式就配置完成了