分类:
精度(accuracy)、召回率、精确率、F值、ROC-AUC 、混淆矩阵、PRC
回归:
RMSE(平方根误差)、MSE(平均平方误差)、MAE(平均绝对误差)、SSE(和方差, 误差平方和)、R-square(确定系数)
聚类:
兰德指数、互信息、轮廓系数
分类算法的评估方法
- 精度
被正确分类的样本占总样本的比
Accuracy = (预测正确的样本数)/(总样本数)=(TP+TN)/(TP+TN+FP+FN) - 召回率
比如病人调查 需要找到所有的病人 这时候就需要用到召回率
Recall = (预测为1且正确预测的样本数)/(所有真实情况为1的样本数) = TP/(TP+FN) - 精确率
Precision = (预测为1且正确预测的样本数)/(所有预测为1的样本数) = TP/(TP+FP) - F值
但由于Precision/Recall是两个值,无法根据两个值来对比模型的好坏。有没有一个值能综 合Precision/Recall呢?有,它就是F1
F1 = 2*(Precision*Recall)/(Precision+Recall) - ROC-AUC
ROC曲线:Receiver Operating Characteristic Curve
AUC:Area Under Curve
通常二分类分类用这种方式来衡量
纵轴:真阳性率(True positive rate、敏感性)-收益
横轴:假阳性率(False positive rate、误诊率=1-特异性)-代价
(1)真阳性率(True positive rate、敏感度sensitivity、Recall):TPR=TP/(TP+FN),即分类器预测的正确的正实例占所有正实例的比值。
(2)真阴性率(True negative rate、特异度specificity):TNR=TN/(FP+TN),即分类器预测的正确的负实例占所有负实例的比值。
(3)假阳性率(False positive rate、误诊率):FPR=FP/(FP+TN),即分类器错误预测为正实例的负实例占所有负实例的比值。
(4)假阴性率(False negative rate、漏诊率):FNR=FN/(TP+FN),即分类器错误预测为负实例的正实例占所有正实例的比值。

- 混淆矩阵

from sklearn .metrics import confusion_matrix
con_mat = confusion_matrix(y_true = y_test, y_pred = y_pred)
print(con_mat)
[[13 1]
[1 23]]
- PRC
precision recall curve
和ROC一样,先看平滑不平滑(蓝线明显好些),在看谁上谁下(同一测试集上),一般来说,上面的比下面的好(绿线比红线好)。F1(计算公式略)当P和R接近就也越大

回归算法的评估方法
-
RMSE(平方根误差)
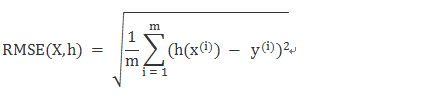
-
MSE(平均平方误差)
这的observed 便是 h(x)

-
MAE(平均绝对误差)
fi表示预测值,yi表示真实值
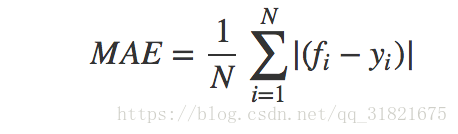
-
SSE(和方差, 误差平方和)
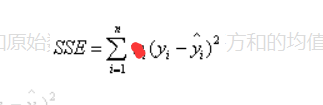
- R-square(确定系数)

图像源于百度
聚类的评估方法
-
兰德指数
需要true_label -
互信息
我们定义互信息的公式为:
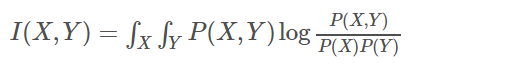
可以看出,如果X与Y独立,则P(X,Y)=P(X)P(Y),I(X,Y)就为0,即代表X与Y不相关 -
轮廓系数
a(i) :i向量到同一簇内其他点不相似程度的平均值
b(i) :i向量到其他簇的平均不相似程度的最小值

图像源于百度