版权声明:转载请注明出处 https://blog.csdn.net/zhouchen1998/article/details/88853664
Apriori算法
- 前言
-
关联分析是一种无监督的机器学习方法,主要用于发现大规模数据集中事物之间的依存性和关联性。挖掘数据中隐藏的有价值的关系(如频繁项集、关联规则),有利于对相关事物进行预测,也能帮助系统制定合理决策。
-
关联分析的典型例子就是购物篮分析,通过发现顾客放入购物篮中不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买可以帮助零售商制定营销策略。另外,关联分析还能应用于餐饮企业的菜品搭配、搜索引擎的内容推荐、新闻流行趋势分析、发现毒蘑菇的相似特征等应用中。
-
为了解释关联分析的一些名词,我使用了一个案例。
号码 商品列表 001 cola,egg,ham 002 cola,diaper,beer 003 cola,diaper,beer,ham 004 diaper,beer -
名词说明
- 事物:每一条交易为一个事物,上表数据集包含三个事物。
- 项:交易的每一个物品称为一个项,如cola、ham等。
- 项集:包含零个或多个项的集合称为项集,如{cola,ham,beer}。
- 规则:从项集中找出各项之间的关系。例如,关联规则{diaper}—>{beer}。
- 支持度计数:整个数据集中包含该项集的事物数。如{diaper,beer}出现在事物002、003和004中,所以它的支持度计数是3。
- 支持度:支持度计数除以总的事物数。{diaper,beer}支持度为75%,说明有75%的人同时买了diaper和beer。
- 频繁项集:支持度大于或等于某个阈值的项集为频繁项集。例如,阈值设为50%时,{diaper,beer}支持度为75%,所以是频繁项集。
- 前件和后件:对于规则{diaper}—>{beer},{diaper}称为前件,{beer}称为后件。
- 置信度:数据集中同时包含两项的百分比。对于规则{diaper}—>{beer},{diaper,beer}的支持度计数除以{diaper}的支持度计数,即为这个规则的置信度。
- 强关联规则:大于或等于最小支持度阈值和最小置信度阈值的规则称为强关联规则,关联分析的最终目的就是找出强关联规则。
-
基本方法
- 关联分析的目标包括两项:发现频繁项集和关联规则。首先需要找到频繁项集,然后才能获得关联规则。关联分析的主要目的就是寻找频繁项集,如果暴力搜索,运算量会几何性增长。为了减少频繁项集的计算量,可以使用Apriori算法和FP-Growth算法。
-
- 原理
- 如果某个项集是频繁的,那么它的所有自己也是频繁的。这个原理反过来看更有用,即如果一个项集是非频繁项集,那么它的所有超集也是非频繁的。
- 算法步骤
- (1)根据数据集生成候选项,首先生成单物品候选项集。
- (2)设定最小支持度和最小置信度。
- (3)过滤掉数据项集占比低于最小支持度的项,形成频繁项。
- (4)根据步骤3形成的频繁项集结果,进行项集之间的组合形成新的项集集合。
- (5)重复步骤3、4,直到没有新的项集满足最小支持度。
-(6)根据步骤5形成的最终频繁集合,计算频繁集合所含物品之间的置信度,过滤掉小于最小置信度的项集。 - (7)根据步骤6的结果生成关联规则,并计算其置信度。
- 上述步骤体现了Apriori算法的两个重要过程:连接步和剪枝步。连接步的目的是找到K项集,从满足约束条件1项候选项集,逐步连接并检测约束条件产生高一级候选项集,知道得到最大的频繁项集。剪枝步是在产生候选项Ck的过程中起到减小搜索空间的目的。根据Apriori原理,频繁项集的所有非空子集也是频繁的,反之,不满足该性质的项集不会存在于Ck中,因此这个过程称为剪枝。
- Apriori算法从单元素项集开始,通过组合满足最小支持度要求的项集来形成更大的集合。每次增加频繁项集的大小,Apriori算法都会重新扫描整个数据集。当数据集很大时,会显著降低频繁项集发现的速度。比较来说,FP-Growth算法只要对数据集进行两次遍历,就能够显著加快发现频繁项集的速度。
- 实战
- 用Apriori进行关联分析
- 发现商品购买的关联规则
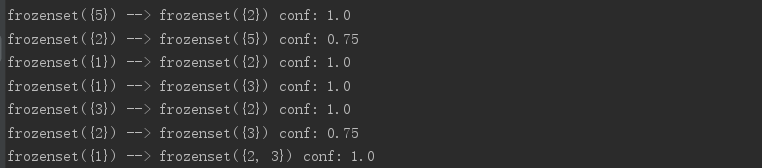
- 可以看到,购买商品1的一定购买商品2和3;商品2与5我的关联可以互换前后件。这些结果都是很有效的。
- 代码
-
# -*-coding:utf-8-*- def loadDataSet(): """ 生成数据集 :return: """ return [[1, 2, 3], [2, 3, 5], [1, 2, 3, 5], [2, 5]] def createC1(dataSet): """ 生成长度为1的所有候选项 :param dataSet: :return: """ C1 = [] for transaction in dataSet: for item in transaction: if not [item] in C1: C1.append([item]) C1.sort() return list(map(frozenset, C1)) def scanD(D, Ck, minSupport): """ 从候选项集中生成频繁项集,同时输出一个包含支持度值的字典 :param D: :param Ck: :param minSupport: :return: """ ssCnt = {} for tid in D: for can in Ck: if can.issubset(tid): if can not in (ssCnt.keys()): ssCnt[can] = 1 else: ssCnt[can] += 1 numItems = float(len(D)) retList = [] supportData = {} for key in ssCnt: support = ssCnt[key] / numItems if support >= minSupport: retList.insert(0, key) supportData[key] = support return retList, supportData def aprioriGen(Lk, k): retList = [] lenLk = len(Lk) for i in range(lenLk): for j in range(i + 1, lenLk): L1 = list(Lk[i])[:k - 2] L2 = list(Lk[j])[:k - 2] L1.sort() L2.sort() if L1 == L2: retList.append(Lk[i] | Lk[j]) return retList def apriori(dataSet, minSupport=0.5): """ 得到频繁项的基础上,进一步将频繁项组合并计算支持度 返回一个包含整个频繁项集的列表和频繁项集列表中每个元素对应的支持度值的字典 :return: """ C1 = createC1(dataSet) D = list(map(set, dataSet)) L1, supportData = scanD(D, C1, minSupport) L = [L1] k = 2 while (len(L[k - 2]) > 0): Ck = aprioriGen(L[k - 2], k) Lk, supK = scanD(D, Ck, minSupport) supportData.update(supK) L.append(Lk) k += 1 return L, supportData def generateRules(L, supportData, minConf=0.7): """ 由于小于最小支持度的项集已经剔除,剩余项集形成的规则中如果大于设定的最小置信度阈值,则认为它们是强关联规则 :param L: :param supportData: :param minConf: :return: """ bigRuleList = [] for i in range(1, len(L)): for freqSet in L[i]: H1 = [frozenset([item]) for item in freqSet] if i > 1: rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) else: calcConf(freqSet, H1, supportData, bigRuleList, minConf) return bigRuleList def calcConf(freqSet, H, supportData, brl, minConf=0.7): prunedH = [] for conseq in H: conf = supportData[freqSet] / supportData[freqSet - conseq] if conf >= minConf: print(freqSet - conseq, '-->', conseq, 'conf:', conf) brl.append((freqSet - conseq, conseq, conf)) prunedH.append(conseq) return prunedH def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7): m = len(H[0]) if len(freqSet) > (m + 1): Hmp1 = aprioriGen(H, m + 1) Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf) if len(Hmp1) > 1: rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf) if __name__ == '__main__': dataSet_1 = loadDataSet() L, suppData = apriori(dataSet_1) print(L) print('\n--------------------\n') print(suppData) rules = generateRules(L, suppData, minConf=0.7) print(rules)
-
- 补充说明
- 参考书《Python3数据分析与机器学习实战》
- 具体数据集和代码可以查看我的GitHub,欢迎star或者fork
- 几个著名的机器学习包内均没有实现Apriori算法