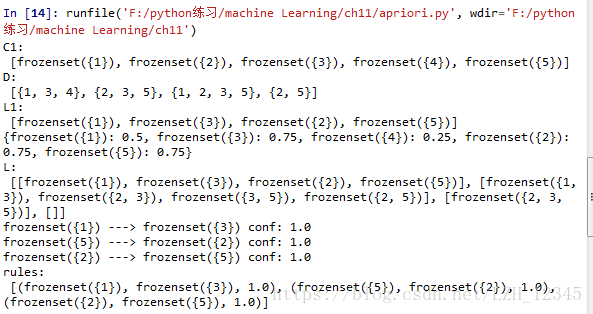
一、关联分析
从大规模数据集中寻找物品间的隐含关系被称作关联分析( association analysis ) 或者关联规则学习(association rule learning)。
关联分析是一种在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:频繁项集或者关联规则。频繁项集(frequent item sets)是经常出现在一块的物品的集合,关联规则 ( association rules )暗示两种物品之间可能存在很强的关系。
频繁项集是指那些经常出现在一起的物品集合。一个项集的支持度(support)被定义为数据集中包含该项集的记录所占的比例。支持度是针对项集来说的,因此可以定义一个最小支持度,而只保留满足最小支持度的项集。
可信度或置信度(confidence)是针对一条诸如{尿布} --->{葡萄酒}的关联规则来定义的。这条规则的可信度被定义为“ 支持度({尿布, 葡萄酒})/支持度({尿布})"。
二、Apriori原理
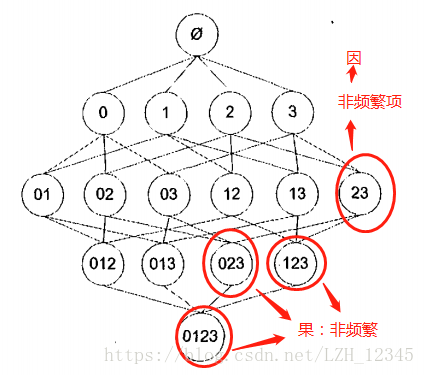
为了降低所需的计算时间,研究人员发现一种所谓的Apriori原理。Apriori原理可以帮我们减少可能感兴趣的项集。这意味着如果{0,1}是频繁的,那么{0} 、{1}也一定是频繁的。这个原理直观上并没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是非频繁集,那么它的所有超集也是非频繁的,如下图所示。
Apriori 原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。
三、利用Apriori算法来发现频繁集,并挖掘关联规则
3.1 代码实现
# -*- coding: utf-8 -*-
"""
Created on Fri May 11 10:21:49 2018
@author: lizihua
"""
def loadDataSet():
return [[1,3,4],[2,3,5],[1,2,3,5],[2,5]]
#构建集合C1,用来存储所有不重复的项值
#类似于C1= set(dataSet) #但这句代码是有问题的,因为dataSet是不可哈希的
#int、float、str、tuple:是可以哈希的; list、set、dict:是不可哈希的
#set、dict的键要求其参数是可哈希的,即哈希or不哈希对可迭代类型的存储元素的要求
#例如:[[1,3,4],[2,3,5],[1,2,3,5],[2,5]]是可迭代的,其存储类型是list,因此,不可哈希
#再例如:[1,2,3,4,5,,6,7,8,9]是可迭代的,其存储类型是int,因此是可哈希的
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort() #排序
return list(map(frozenset, C1)) #frozenset指“冰冻”的集合,即不可变集合
#从C1生成L1。
#三个参数:D:数据集的集合形式,Ck:候选项集列表,minSupport:感兴趣的最小支持度
def scanD(D, Ck, minSupport):
#空子典,用来存储候选集子集(键key)列表,及出现的次数(值value)
ssCnt = {}
for tid in D: #遍历数据集所有交易记录
for can in Ck: #遍历候选集
if can.issubset(tid): #判断候选集是否是交易记录的子集,
if can not in ssCnt.keys(): #若候选集不是ssCnt的键
ssCnt[can]=1 #则使得字典中该键的值为1
else: #反之,即存在该键,则键值+1
ssCnt[can]+=1
numItems = float(len(D)) #迭代次数
retList = [] #用来存储大于最小支持度的的候选集
supportData = {} #用来存储各个候选集及其支持度
for key in ssCnt:
support = ssCnt[key]/numItems
if support >= minSupport:
retList.append(key)
supportData[key] = support
return retList, supportData
#Apriori算法
#输入参数是:频繁项集列表Lk与项集元素个数k,输出为Ck
#例如:Lk=[{1},{2},{3}],k=3,则,Ck=[{1,2},{1,3},{2,3}]
#作用:由k个项组成的候选集,构建一个k+1项组成的候选集的列表
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk):
for j in range(i+1, lenLk):
#前k-2个项相同时,将两个集合合并
#注意:当Lk[0]={1},k=2,则list(Lk[i])[:k-2]=[]
L1 = list(Lk[i])[:k-2];L2 = list(Lk[j])[:k-2]
L1.sort();L2.sort()
if L1 == L2:
retList.append(Lk[i] | Lk[j])
return retList
#生成最终支持度大于minSupport的候选集列表
def apriori(dataSet, minSupport = 0.5):
C1 = createC1(dataSet)
D = list(map(set,dataSet))
L1,supportData = scanD(D,C1,minSupport)
L = [L1]
k=2
while(len(L[k-2]) > 0):
Ck = aprioriGen(L[k-2], k)
Lk,supK = scanD(D,Ck,minSupport)
supportData.update(supK)
L.append(Lk)
k += 1
return L,supportData
#关联规则生成函数
#参数:频繁项集列表,包含频繁项集支持数据的字典,最小可信度阈值
#生成一个包含可信度的规则列表
def generateRules(L,supportData,minConf = 0.7):
bigRuleList = []
#只获取有两个或更多元素的集合,L[0]有1个元素,L[1]有2个元素,L[2]有3个元素
for i in range(1,len(L)):
for freqSet in L[i]:
H1 = [frozenset([item]) for item in freqSet]
if (i > 1): #3个及3个以上元素
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf)
else: #i=1,有2个元素
calcConf(freqSet,H1,supportData,bigRuleList,minConf)
return bigRuleList
#对规则进行评估
#
def calcConf(freqSet,H,supportData,brl,minConf = 0.7):
prunedH = [] #用来保存满足最小可信度的规则
#遍历H中所有项集,计算它们的可信度
for conseq in H:
#计算freqSet-conseq--->conseq的可信度
conf = supportData[freqSet]/supportData[freqSet - conseq]
if conf >= minConf:
print (freqSet-conseq,'--->',conseq,'conf:',conf)
brl.append((freqSet-conseq,conseq,conf)) #将规则及可信度以元组的方式存储在brl
prunedH.append(conseq)
return prunedH
#生成候选集规则集合
#参数:频繁项集,规则右边的元素列表H
def rulesFromConseq(freqSet,H,supportData,brl,minConf=0.7):
m = len(H[0]) #频繁集大小m
#查看频繁项是否可以大到可以移除大小为m的子集
if (len(freqSet) > (m+1)):
Hmp1 = aprioriGen(H,m+1) #利用aprioriGen来生成H中元素的无重复组合,并存储到Hmp1
#作为下一次迭代的H列表,利用calcConf函数测试它们的可信度以确定是否满足要求
Hmp1 = calcConf(freqSet,Hmp1,supportData,brl,minConf)
#若不止一条规则满足要求,则使用函数rulesFromConseq()来判断是否可以进一步组合这些规则
if (len(Hmp1) > 1):
rulesFromConseq(freqSet,Hmp1,supportData,brl,minConf)
if __name__ == '__main__':
dataSet = loadDataSet()
C1=createC1(dataSet)
print(C1)
D = list(map(set,dataSet))
print(D)
L1,suppData0 = scanD(D,C1,0.5)
print(L1)
print(suppData0)
L,suppData = apriori(dataSet, minSupport = 0.5)
print(L)
rules = generateRules(L,suppData, minConf = 0.7)
print(rules)