本博客所用代码来源:数据挖掘十大算法(四):Apriori(关联分析算法)
在网上搜索Apriori算法很多博客里用的代码都是同一个,看介绍应该最初是来源《机器学习实战》这本书
这篇博客实质就是按运行顺序对这个的代码理解与分析,请务必结合完整代码一块阅读!(完整代码见本文第三部分,或点击来源链接)
一、获取频繁项集
1、获取数据
获取数据的步骤封装在一个函数中,一方面看着思路清晰,另一面替换数据集也方便
dataSet = loadDataSet()
# 构造数据
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
2、调用apripri()函数,返回频繁项集及其对应支持度
L,suppData = apriori(dataSet)
# 封装所有步骤的函数
# 返回 所有满足大于阈值的组合 集合支持度列表
def apriori(dataSet, minSupport = 0.5):
3、将列表类型dataSet转成集合型(set),并用列表表示后赋值给D
(在代码注释中将D的类型理解成是字典型,个人感觉不准确,虽然集合型和字典型都是{}为标志,但这里应该是借用map函数将列表类型转成集合类型,最后用列表表示才对)
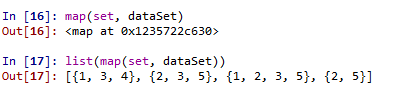
D = list(map(set, dataSet))
# 转换列表记录为字典 [{1, 3, 4}, {2, 3, 5}, {1, 2, 3, 5}, {2, 5}]
转化前转换后:
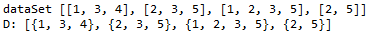
关于map函数的用法的简单介绍教程
注意:Python 3.x 返回是迭代器,所以要用list()表示
没理解透彻也不要紧,记住组合数据类型之间的类型转换可以采用这种方式就好了
4、将列表类型dataSet中出现的每个元素提取出来,并转换成frozenset类型,最后用列表表示后赋值给C1

个人认为,整个程序最核心也是最不好理解的就是:为什么要转换成frozenset()集合类型的!

C1 = createC1(dataSet) #将每个元素转会为frozenset字典
# 将所有元素转换为frozenset型字典,存放到列表中
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
# 使用frozenset是为了后面可以将这些值作为字典的键
return list(map(frozenset, C1)) # frozenset一种不可变的集合,set可变集合
5、去除非频繁的项集,并计算对应的支持度
进入函数前已有的数据:

函数运行后或许到的数据:

L1, supportData = scanD(D, C1, minSupport) # 过滤数据
# 过滤掉不符合支持度的集合
# 返回 频繁项集列表retList 所有元素的支持度字典
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid): # 判断can是否是tid的《子集》 (这里使用子集的方式来判断两者的关系)
if can not in ssCnt: # 统计该值在整个记录中满足子集的次数(以字典的形式记录,frozenset为键)
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = [] # 重新记录满足条件的数据值(即支持度大于阈值的数据)
supportData = {} # 每个数据值的支持度
for key in ssCnt:
support = ssCnt[key] / numItems
if support >= minSupport:
retList.insert(0, key)
supportData[key] = support
return retList, supportData # 排除不符合支持度元素后的元素 每个元素支持度
6、通过组合函数aprioriGen(),组合多元素的频繁项集。

# 生成所有可以组合的集合
# 频繁项集列表Lk 项集元素个数k [frozenset({2, 3}), frozenset({3, 5})] -> [frozenset({2, 3, 5})]
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk): # 两层循环比较Lk中的每个元素与其它元素
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2] # 将集合转为list后取值
L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort() # 这里说明一下:该函数每次比较两个list的前k-2个元素,如果相同则求并集得到k个元素的集合
if L1==L2:
retList.append(Lk[i] | Lk[j]) # 求并集
return retList # 返回频繁项集列表Ck
7、通过循环,找出所有满足支持度的频繁项集组合,并最终确定的频繁项集集合和相关支持度
进入循环前的数据:
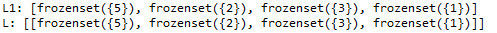
循环结束后,即函数apriori()结束后返回的数据:

对应def apriori(dataSet, minSupport = 0.5):函数部分
L = [L1]
k = 2
while (len(L[k-2]) > 0): # 若仍有满足支持度的集合则继续做关联分析
Ck = aprioriGen(L[k-2], k) # Ck候选频繁项集
Lk, supK = scanD(D, Ck, minSupport) # Lk频繁项集
supportData.update(supK) # 更新字典(把新出现的集合:支持度加入到supportData中)
L.append(Lk)
k += 1 # 每次新组合的元素都只增加了一个,所以k也+1(k表示元素个数)
return L, supportData
二、关联规则
1、函数调用部分(整个程序的主函数)
dataSet = loadDataSet() #加载数据集
L,suppData = apriori(dataSet,minSupport=0.5) #获取频繁项集L,对应支持度字典suppData
rules = generateRules(L,suppData,minConf=0.7)#求关联规则,置信度设置为0.7
# rules = generateRules(L,suppData,minConf=0.5)
print(rules)
2、对集合元素等于2个和大于2个的关联规则情况进行分别讨论
# 获取关联规则的封装函数
def generateRules(L, supportData, minConf=0.7): # supportData 是一个字典
bigRuleList = []
for i in range(1, len(L)): # 从为2个元素的集合开始
for freqSet in L[i]:
# 只包含单个元素的集合列表
H1 = [frozenset([item]) for item in freqSet] # frozenset({2, 3}) 转换为 [frozenset({2}), frozenset({3})]
# 如果集合元素大于2个,则需要处理才能获得规则
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) # 集合元素 集合拆分后的列表 。。。
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
元素集合元素为2个的:
直接用calcConf()函数计算出,两两之间的互相置信度,并判断其是否为强关联。
元素集合元素大于2个的:
采用rulesFromConseq()函数,将部分元素进行合并,之后再进行“一推二”,所谓“一推二”为:

bigRuleList用于记录达到最小置信度的“强关联”,也就是要输出的最终结果。

3、 calcConf()函数主要用于计算集合元素之间互相的关联置信度
这关于集合中有三个元素的情况只考虑了一推二,没有考虑二推一
对于二推一(多退一),这里或许只需要加个if-else即可。
# 对规则进行评估 获得满足最小可信度的关联规则
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] # 创建一个新的列表去返回
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq] # 计算置信度
if conf >= minConf:
print(freqSet-conseq,'-->',conseq,'conf:',conf)
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
集合元素为2个的情况举例:
一共有4种[{2,3},{3,5},{2,5},{1,3}],这里举例{2,3}

集合元素为3个的情况:
这里可以看出,用于循环序列的变量conseq实际上是拥有的元素是占多的:conseq: frozenset({2, 3}),而集合全体freqSet: frozenset({2, 3, 5}),去减去循环序列conseq为:freqSet-conseq: frozenset({5}),反倒是只会有一个元素。

4、rulesFromConseq()函数处理多元素集合关联问题
# 生成候选规则集合
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): # 尝试进一步合并
Hmp1 = aprioriGen(H, m+1) # 将单个集合元素两两合并
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): #need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)

这里也就解释了:为什么置信度计算函数calcConf()会有返回值。
这里假设:frozenset({5}) --> frozenset({2, 3}) 为强关联,那么这时calcConf()函数的返回值prunedH集合就不为空,那么就有if (len(Hmp1) > 1)为True,从而进一步分析frozenset({2, 3}) 的关联特性!
三、所谓的完整代码
在这里衷心的感谢这个代码的原作者(虽然有点瑕疵,但确实写的很好!)
from numpy import *
# 构造数据
def loadDataSet():
return [[1, 3, 4], [2, 3, 5], [1, 2, 3, 5], [2, 5]]
# 将所有元素转换为frozenset型字典,存放到列表中
def createC1(dataSet):
C1 = []
for transaction in dataSet:
for item in transaction:
if not [item] in C1:
C1.append([item])
C1.sort()
# 使用frozenset是为了后面可以将这些值作为字典的键
return list(map(frozenset, C1)) # frozenset一种不可变的集合,set可变集合
# 过滤掉不符合支持度的集合
# 返回 频繁项集列表retList 所有元素的支持度字典
def scanD(D, Ck, minSupport):
ssCnt = {}
for tid in D:
for can in Ck:
if can.issubset(tid): # 判断can是否是tid的《子集》 (这里使用子集的方式来判断两者的关系)
if can not in ssCnt: # 统计该值在整个记录中满足子集的次数(以字典的形式记录,frozenset为键)
ssCnt[can] = 1
else:
ssCnt[can] += 1
numItems = float(len(D))
retList = [] # 重新记录满足条件的数据值(即支持度大于阈值的数据)
supportData = {} # 每个数据值的支持度
for key in ssCnt:
support = ssCnt[key] / numItems
if support >= minSupport:
retList.insert(0, key)
supportData[key] = support
return retList, supportData # 排除不符合支持度元素后的元素 每个元素支持度
# 生成所有可以组合的集合
# 频繁项集列表Lk 项集元素个数k [frozenset({2, 3}), frozenset({3, 5})] -> [frozenset({2, 3, 5})]
def aprioriGen(Lk, k):
retList = []
lenLk = len(Lk)
for i in range(lenLk): # 两层循环比较Lk中的每个元素与其它元素
for j in range(i+1, lenLk):
L1 = list(Lk[i])[:k-2] # 将集合转为list后取值
L2 = list(Lk[j])[:k-2]
L1.sort(); L2.sort() # 这里说明一下:该函数每次比较两个list的前k-2个元素,如果相同则求并集得到k个元素的集合
if L1==L2:
retList.append(Lk[i] | Lk[j]) # 求并集
return retList # 返回频繁项集列表Ck
# 封装所有步骤的函数
# 返回 所有满足大于阈值的组合 集合支持度列表
def apriori(dataSet, minSupport = 0.5):
D = list(map(set, dataSet)) # 转换列表记录为字典 [{1, 3, 4}, {2, 3, 5}, {1, 2, 3, 5}, {2, 5}]
C1 = createC1(dataSet) # 将每个元素转会为frozenset字典 [frozenset({1}), frozenset({2}), frozenset({3}), frozenset({4}), frozenset({5})]
L1, supportData = scanD(D, C1, minSupport) # 过滤数据
L = [L1]
k = 2
while (len(L[k-2]) > 0): # 若仍有满足支持度的集合则继续做关联分析
Ck = aprioriGen(L[k-2], k) # Ck候选频繁项集
Lk, supK = scanD(D, Ck, minSupport) # Lk频繁项集
supportData.update(supK) # 更新字典(把新出现的集合:支持度加入到supportData中)
L.append(Lk)
k += 1 # 每次新组合的元素都只增加了一个,所以k也+1(k表示元素个数)
return L, supportData
# 获取关联规则的封装函数
def generateRules(L, supportData, minConf=0.7): # supportData 是一个字典
bigRuleList = []
for i in range(1, len(L)): # 从为2个元素的集合开始
for freqSet in L[i]:
# 只包含单个元素的集合列表
H1 = [frozenset([item]) for item in freqSet] # frozenset({2, 3}) 转换为 [frozenset({2}), frozenset({3})]
# 如果集合元素大于2个,则需要处理才能获得规则
if (i > 1):
rulesFromConseq(freqSet, H1, supportData, bigRuleList, minConf) # 集合元素 集合拆分后的列表 。。。
else:
calcConf(freqSet, H1, supportData, bigRuleList, minConf)
return bigRuleList
# 对规则进行评估 获得满足最小可信度的关联规则
def calcConf(freqSet, H, supportData, brl, minConf=0.7):
prunedH = [] # 创建一个新的列表去返回
for conseq in H:
conf = supportData[freqSet]/supportData[freqSet-conseq] # 计算置信度
if conf >= minConf:
print(freqSet-conseq,'-->',conseq,'conf:',conf)
brl.append((freqSet-conseq, conseq, conf))
prunedH.append(conseq)
return prunedH
# 生成候选规则集合
def rulesFromConseq(freqSet, H, supportData, brl, minConf=0.7):
m = len(H[0])
if (len(freqSet) > (m + 1)): # 尝试进一步合并
Hmp1 = aprioriGen(H, m+1) # 将单个集合元素两两合并
Hmp1 = calcConf(freqSet, Hmp1, supportData, brl, minConf)
if (len(Hmp1) > 1): #need at least two sets to merge
rulesFromConseq(freqSet, Hmp1, supportData, brl, minConf)
dataSet = loadDataSet()
L,suppData = apriori(dataSet,minSupport=0.5)
rules = generateRules(L,suppData,minConf=0.7)
# rules = generateRules(L,suppData,minConf=0.5)
print("具有强关联规则的项集为:",rules)
后记
本篇博客很多细节是能讲的更清楚的,可以继续深究的东西实际上也有很多,但碍于时间有限,要做的事情太多,很多东西只能是点到为止。
最后说明一下:这篇博客本质就只是我个人的学习笔记罢了。
