1、二分查找
从有序列表的候选区data[0:n]开始,通过对待查找的值与候选区中间值的比较,可以使候选区减少一半。
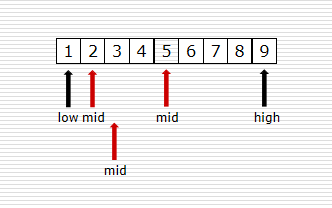
示例(使用二分查找3):
二分查找代码:
def bin_search(data_set, val):
low = 0
high = len(data_set) - 1
while low <= high:
mid = (low+high)//2
if data_set[mid]['id'] == val:
return mid
elif data_set[mid]['id'] < val:
low = mid + 1
else:
high = mid - 1
return
2、冒泡排序
列表有n个数,列表每两个相邻的数,如果前边的比后边的大,那么交换这两个数……
一共冒泡n-1趟,第 i 趟交换 n-i-1 次。
时间复杂度 o(n^2) 。
代码如下
def bubble_sort(li):
for i in range(len(li) - 1):
for j in range(len(li) - i - 1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
冒泡排序优化:
def bubble_sort_1(li):
for i in range(len(li) - 1):
exchange = False
for j in range(len(li) - i - 1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
exchange = True
if not exchange:
break
优化后的冒泡排序时间复杂度 o(n^2) ,最好的时间复杂度是 o(n) 。
3、选择排序
一趟遍历记录最小的数,放到第一个位置;一趟遍历记录最小的数,放到第一个位置;……
时间复杂度 o(n^2) 。
代码如下
def select_sort(li):
for i in range(len(li) - 1):
min_loc = i
for j in range(i+1,len(li)):
if li[j] < li[min_loc]:
min_loc = j
li[i], li[min_loc] = li[min_loc], li[i]
4、插入排序
列表被分为有序区和无序区两个部分。最初有序区只有一个元素。
每次从无序区选择一个元素,插入到有序区的位置,直到无序区变空。
时间复杂度 o(n^2) 。
代码如下
def insert_sort(li):
for i in range(1, len(li)):
tmp = li[i]
j = i - 1
while j >= 0 and li[j] > tmp:
li[j+1]=li[j]
j = j - 1
li[j + 1] = tmp