
数据下载地址:数据集下载

图像:

想要表示出这些数据背后隐藏的规则,其中的一种方式是想办法得到某个方程,通过输入X得到对应的Y值。
我们假设这个方程的形式为:

其中ωi 为 Xij (0<i<n+1,0<j<4)对应的系数,我们称它为回归系数,我们称这个方程为回归方程,我们称求出系数ωij的过程为回归。
只要我们能够通过某种方法求出了系数ω,我们就能得到回归方程,只要我们得到回归方程,我们就能预测给定的x对应的点(x,y)。
求出系数ω的方式有很多,求出的方程对数据集的拟合程度也有差异。
最佳拟合直线方法:

Yi"是回归方程接收到输入X后对输出结果的预测值,预测的值与真实值存在偏差:Yi - Yi" 。如果对数据集中所有的点进行预测那么就存在一个总的偏差:

因为偏差有正偏差和负偏差,正负偏差可能会相互抵消,所以我们用下式代表总偏差:

因为Yi"=Xi*ω,所以上式等价于:

用矩阵的形式进行表达: (X、Y、ω都是矩阵)

对上式进行求导,得:
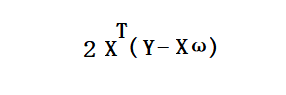
令上式等于零,解得:
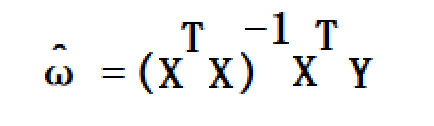
至此,就得到了能够使预测值总偏差最小的系数矩阵ω,同时也就得到了能够预测这个模型的回归方程。
对得到的回归方程进行测试:(图中蓝点为数据集,红线为回归方程)

最佳拟合直线算法将数据视为直线进行建模,具有十分不错的表现,但是很多时候,数据中还会存在其他的潜在模式。那么怎样才能利用这些模式呢?我们可以根据数据来局部调整预测,下面将要介绍的局部加权线性回归算法就是这样。
局部加权线性回归法:
线性回归的一个问题是可能出现欠拟合现象,因为它求的是最小均方误差的无偏估计。我们可以在估计中引入一些偏差,从而降低预测的均方误差。其中的一个方法是 局部 加权 线性回归。
在该算法中,我们在预测每个点前,先给数据集中的每个点赋予一个权重。离现在要预测的这个点越近的点,获得的权重就越大,离现在要预测的这个点越远的点,获得的权重就越小。
假设:
我们想要了解学生A是一个怎样的人,于是我们向全校所有师生发送一份调查问卷,问卷中只有一个问题:“学生A是一个怎样的人?”,假设所有师生都如实回答,最后我们能够得到全校师生对学生A的评价。我们要怎样用获取到的这些评价来判断出学生A最可能是一个怎么样的人呢?是不是所有人对学生A的评价都具有相同的参考价值呢?
我们先回答后面的问题,每个人对学生A的评价具有不同的参考价值,因为每个人对学生A的熟悉程度不一样,学生A的同班同学、老师对学生A的评价肯定比没见过学生A的路人甲对学生A的评价更有参考价值。
最终通过评价判断学生A的方法有两种:
方法一:综合每一个评价,得出对学生A的判断
方法二:根据每个人对学生A的熟悉程度,给每个人对学生A的评价加一个权重,然后综合每一个判断,得出对学生A的判断
用哪一种方法得到的对学生A的判断是更准确的呢?显然是方法二。
最佳拟合直线算法就好比方法一,对每一个评价一视同仁,每个评价对我们最终判断学生A发挥同样的最用;局部加权线性回归算法就好比方法二,每个评价占据不同的权重,有些评价甚至不影响(比如一个不认识学生A的学生B对学生A的评价)。
矩阵W是预测每个数据点时,数据集中每个点对应的权重。 (判断一个学生时,对学生的每个评价的占的份量)
局部加权线性回归算法中,预测每个点时,使用“核”来对数据集中的每个点赋予一个权重(数据集中每个点对要预测的点能够发挥多大的作用),对预测点附近的点赋予更高的权值(离预测点比较近的点对预测点发挥的作用更大)。核的类型可以自由选择,最常用的核就是高斯核,高斯核对应的权重如下:

矩阵W:
矩阵W的阶数为数据集中数据的条数,即点的个数。
矩阵中除了对角线,其他地方的值为0。
对角线上W(i,i)处的值即为预测当前点时,数据点(Xi,Yi)对应的权重。
得到权重后,我们就计算出,预测这个点要使用到的回归方程中的回归系数:

得到回归系数我们就能得到预测当前点的回归方程:
然后我们就能得到当前点的预测值:
(Xi,Yi")
使用局部线性回归算法对数据集中每一个点进行预测时都需要重复上面的过程:计算数据集中各点对在本测预测中该占的权重、计算回归系数、得到回归方程、给出预测值。所以局部加权线性回归算法存在计算量大的问题。
关于k:
参数k控制了权重随距离变化的速率,
k值越大,权重随距离变化的速率越小,预测某个点时用到的数据点就更多。
k值越小,权重随距离变化的速率越大,预测某个点时用到的数据点就更少。
k值的选择是很重要的,k值选择过大,可能出现过拟合问题,k值选择过小,可能出现欠拟合问题。
下图为,不同k值下,使用局部加权线性回归算法的拟合效果:
