大概实现思路如下:
- 通过Tushare等第三方渠道或Scrapy爬取所需要的股票信息,存在数据库中。
- 通过kafka-canal监控mysql的log,实时更新neo4j内的数据。
- 使用Django rest Framework生成微服务,提供api。
- 使用Vue搭建简单的前端,调取api以获得信息。
下面来看下具体的实现细节:
1.数据初次采集
通过Tushare等第三方渠道获取信息
(部分代码)
from py2neo import Node, Relationship, Graph
import tushare as ts
from sqlalchemy import create_engine
import pymysql
pymysql.install_as_MySQLdb()
from pandas import DataFrame
# TODO:获取上市公式的行业、概念、地域信息
# 行业
industry = ts.get_industry_classified()
# 概念
concept = ts.get_concept_classified()
# 地域
area = ts.get_area_classified()
插入neo4j
# 创建Company所属行业
industry_set = set()
for row in industry.itertuples():
code = row[1]
name = row[2]
c_name = row[3]
# 创建Company节点
company_node = Node('Company',code=code, name=name)
graph.create(company_node)
# 创建Industry节点
if c_name not in industry_set:
industry_set.add(c_name)
industry_node = Node('Industry',c_name=c_name)
graph.create(industry_node)
# 创建INDUSTRY_OF关系
crate_industry_rls_cql = 'match (c:Company{code:"'+code+'"}),(i:Industry{c_name:"'+c_name+'"}) create (c)-[:INDUSTRY_OF]->(i)'
graph.run(crate_industry_rls_cql)
存储如下:

通过同花顺等平台爬取股票的基础数据,例如这个。
将需要做关系抽取等操作的数据存入Neo4j,将只需要做简单查询的数据存入mysql。

2.数据的持续更新
之前博客分享过kafka相关的配置方法,有兴趣的同学可以查看这里。
使用kafka-canal监控mysql的log文件,数据有更新时,使用neo4j-java-driver更新neo4j内的信息。

3.数据清洗
类似于股价这样的信息,我们可以直接保存。但是像新闻文章类似的数据,因为是非结构化文本,我们要将文章与股票进行关联的操作之前,要做一些数据清洗的步骤。对文本预处理感兴趣的同学,可以看这里。
不进行清洗的文本可能是长成这样:

清洗完会变成这样:

当然,要进行向量化处理的时候,我们需要去除停用词,标点符号以及更多无意义的内容。
本项目主要使用了jieba、pyltp等库对文章进行分词、命名实体识别等操作。
4.问题及规则建立
我们可以建立如下的问题模板
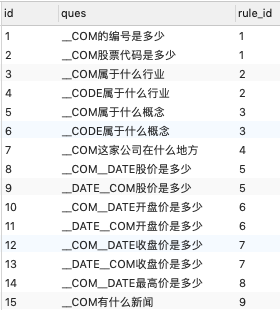
以及一些答案模板
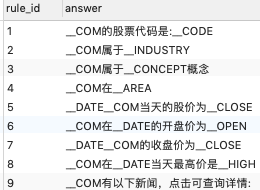
5.Django生成微服务
我们将上一步骤所有的问题,进行分词,然后使用tf-idf转成向量矩阵。
def vecMatrix(data):
"""
:param data: data Matrix(DataFrame)
:return:
vectorizer: vector model
X: vector matrix
"""
new_data = []
for q in data:
q = word_segmentation(q)
new_data.append(q)
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(new_data)
return vectorizer, X
sql = 'select ques,rule_id from question_lib'
data = read_mysql(sql)
ques_list = data['ques']
ruleId_list = data['rule_id']
vectorizer, X = vecMatrix(ques_list)
当拿到一个新的问题时,由vectorizer去计算句子的向量,遍历矩阵寻找最高相似度,然后拿到对应问题的index,通过index去查询对应的答案模板ruleId。
question_new = word_segmentation(question)
answer_vec = vectorizer.transform([question_new])
idx = cosine_similarity(answer_vec, X)[0]
top_idxs = np.argsort(idx)
ruleId = ruleId_list[top_idxs[-1]]
通过ruleId拿到答案模板,然后使用封装好的方法,将变量替换为真实值。
例如:“贵州茅台属于什么行业?”或“600519属于什么行业”
会找到问题模板:"__COM属于什么行业"或"__CODE属于什么行业"
然后得到答案模板:"__COM属于__INDUSTRY"
通过关键信息去neo4j里进行查询
cypher = "match (c:Company)-[:INDUSTRY_OF]->(i:Industry) where c.name = '" + com_name + "' return i.c_name"
industry = graph.run(cypher).data()
拿到结果,然后替换字符变成:“贵州茅台属于酿酒行业”
以上是提问的api的处理方式,换成查看新闻之类的api,一个简单的news_id查询结果即可。
6. 前端搭建
最后,使用Vue搭建一个简单的前端页面,使用axios调用对应的api,就实现啦~

项目的难点在于数据的梳理,和后端代码的实现结构,我也只是做了简单的实现,整个项目还有很多地方可以优化,例如:
- 数据更精确的实时获取
- 更好的存储方式,例如矩阵放在Redis中,或结构化信息放在MongoDB中等
- 问题的规则和类型完善
- 实现多轮对话
- UI的优化
有问题的同学可以在博客下方留言,谢谢~