给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配。
'.' 匹配任意单个字符
'*' 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
说明:
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:
s = "aa"
p = "a*"
输出: true
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:
s = "ab"
p = ".*"
输出: true
解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
输入:
s = "aab"
p = "c*a*b"
输出: true
解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:
输入:
s = "mississippi"
p = "mis*is*p*."
输出: false
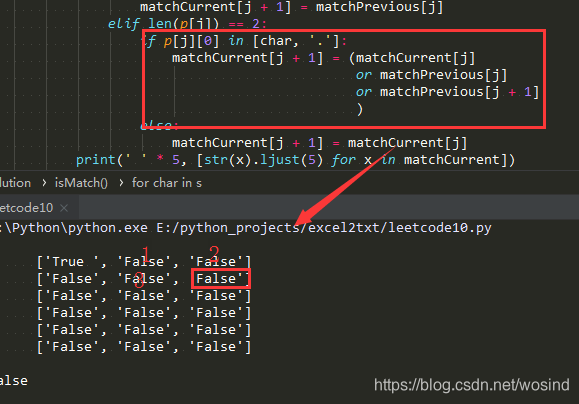
class Solution:
def isMatch(self, s, p):
# 合并*与前面一个字符
tempList = []
p +='#'
tempItem = ''
for item in p:
if item != '*':
tempList.append(tempItem)
tempItem = item
else:
tempItem += item
p = tempList[1:]
# 初始化match表
matchPrevious = [False] * (len(p) + 1)
matchCurrent = [False] * (len(p) + 1)
matchPrevious[0] = True
for j in range(len(p)):
if len(p[j]) == 2:
matchPrevious[j + 1] = matchPrevious[j]
else:
break
for char in s:
for j in range(len(p)):
if p[j] == char or p[j] == '.':
matchCurrent[j + 1] = matchPrevious[j]
elif len(p[j]) == 2:
if p[j][0] in [char, '.']:
matchCurrent[j + 1] = (matchCurrent[j]
or matchPrevious[j]
or matchPrevious[j + 1]
)
else:
matchCurrent[j + 1] = matchCurrent[j]
matchPrevious = matchCurrent
matchCurrent = [False] * (len(p) + 1)
return matchPrevious[-1]
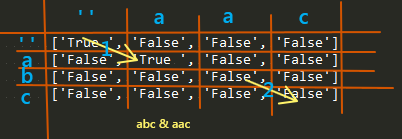
对match表不太理解可以先看两个没有通配符的例子

单个字符相同,要前面的字符也相同,才算匹配,第一个字符是没有前面的字符,所以给虚拟了两个相同的字符,比如图中的空格。
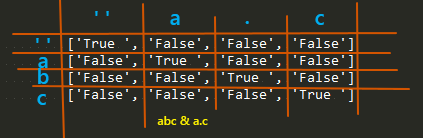
通配符. 比较简单,仍然是一个字符。
*号通配符,

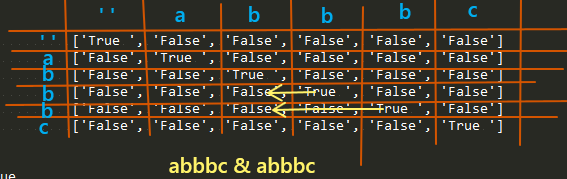
它要参考3个值