BNN和异或网将权重和卷积层的值进行量化,进而将在前相传播过程中花费最多的卷积操作转化为了两个bit向量的逐比特的点积:
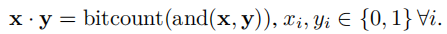
这里bitcount计算比特向量中比特的数量。
之前的网络都没能在反向传播保持8比特以下的精度的同时,能够拥有可接受的精度。
dorefa-net的创新点在于:
1、它能够以任意的精度量化权重、激活层和梯度。
2、由于比特卷积可以高效地在各种设备上实现,因此他为在各种软件上实现神经网络提供了方法。
3、实验证明,为了尽可能地保持模型精度,对量化精度的要求的降序排列是梯度、激活层和权重。
4、实验证明了dorefa-net的有效性。
作者强调了一点,在量化权重和激活层时,要用确定的函数来做,但梯度要进行随机量化。
上面提到的x·y是当它们是1比特时的,若它们是多比特的数字,则乘法规则变为:
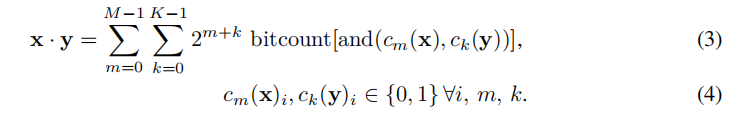
其复杂度为O(MK)。
STE
因为我们要用量化的方式来表示数据,那么在计算梯度时就会出现问题:因为量化后的数值的表达能力是有限的,这使得导数并不总是能够正确地表示。

于是如上图的STE方法就被提出了:
我们不能直接求得q对p的导数,因为伯努利分布是不可导的。但因为q的期望等于p,所以我们可以使用c对q的导数来近似地表示c对p的导数。
运用这个思想,作者提出了如下形式的STE:
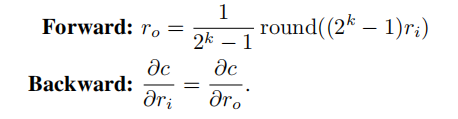
由于量化的过程本身不可导,但ro的期望是ri,所以我们可以用上图下面的方式来近似地表示c对ro的导数。而ro参与的计算如上图3式所示。
对权重的量化
BNN使用的STE如下:
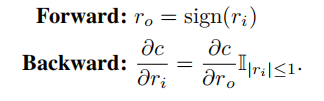
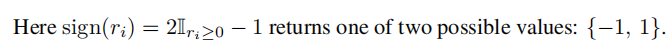
异或网使用的STE如下:
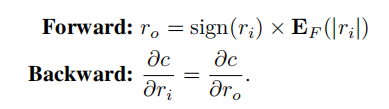
这里
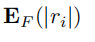
是每个输出层的权重的绝对值的均值,这样就能在保持量化的同时,提高权重的值域。但这种方法会导致在反向传播时,计算梯度和权重的卷积是不能使用位卷积运算。于是本文提出了如下的STE:
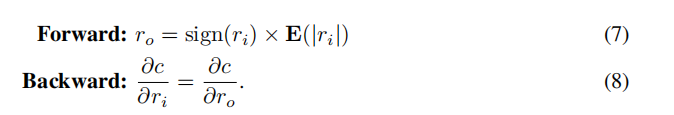
这里的
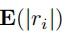
是一个固定的值(这里没说它是如何得出的,但从形式上来看可能是所有输出层的权重的绝对值的均值。但使用这种方法并不一定是合适的,可以考虑用学习的方法来得到这个值。)
上面那是一位时的STE方法,当使用k位时,使用的STE如下:
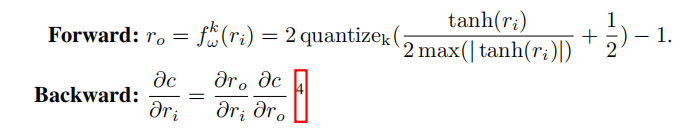
当k=1时,其实它和7式并不相同,但作者在实验中发现,这个不同并不重要。
对激活层的量化
在BNN和异或网中,对激活层的量化方法和权重一致,但作者并不能重现它们这种方法的精度,于是他采用了如下方法:

这里作者式假定了r之前经过了一个边界函数使其落入[0,1]。感觉这样的方法太简单了,应该会带来很大的精度损失。
对梯度的量化
这里的STE如下:
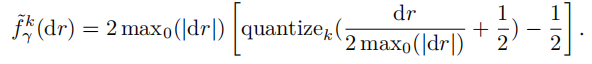
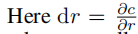
这里max是遍历每个数据的所有维度得出的最大值。
但由于实验证明,在量化梯度时必须引入随机量来弥补量化误差,于是作者在梯度量化方程里加入了人工噪音:
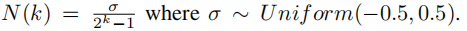
最终式子如下:
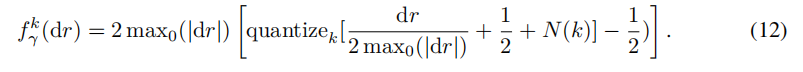
这个方法挺精巧,但感觉还是过于简单了。虽然梯度的量化误差确实是在(-0.5,0.5)区域内,但这种取样方法除非是训练无数次取最佳,否则应该很难达到理想状态。理想的方法应该是想办法把它变成一个可学习的参数,但是这样每个参数都设置一个学习参数,对训练的要求可能就会过高。所以后续的类似inq这样的渐进式量化方法的改进点,应该就来自于此。
算法

网络的第一层和最后一层
这两层是网络中比较特殊的两层,因为前者的输入一般是8比特的图像,对其进行量化会导致极大的精度损失,而且图像一般通道数都很小,所以计算起来也比较省事,所以不对其进行量化。而后者的输出则近似是独热类型,这和位矢量在定义上比较相似,所以一般也不进行量化。
总的感受
STE的方法很精巧,把卷积操作转化为位操作,确实会节省不少运算消耗。基础方面知识的讲解很清晰,是入门量化必读的一篇论文。
但是量化的方程,参数的设置,训练的方法,还是存在一些感觉可以改进的点。
