研究论文《Joint Scheduling and Deep Learning-Based Beamforming for FD-MIMO Systems Over Correlated Rician Fading》
摘要: 本文研究了在相关瑞利衰落信道下的全维多输入多输出系统的下行传输问题。通过在基站获取的统计信道状态信息,每个用户的波束形成向量通过解耦彼此分离直至达到平均信噪比下界的最大值,推导出了最优波束形成矢量,该矢量涉及两个方向的视距分量和相关矩阵。为了减少获得每个用户波束向量的时间使用深度学习算法。基于所提出的波束形成方法,对每个用户的遍历率进行分析,并给出简单的封闭近似,对评价系统性能和用户调度有很大的帮助。此外提出两种最不相似和最小干扰信号因子的用户调度算法,与基于和速率的贪心调度算法相比,大大降低了算法复杂度。
系统模型
本文中,我们考虑的是单个的FD-MIMO下行传输系统,系统中有
L个单天线用户终端。基站采用
M×N型的均匀平面天线阵(UDP),每一行和每一列中相邻的两个天线单元之间的距离为载波
λ的一半,基站最多可以为
Ut个用户服务。则用户u处接收到的信号可以表示为:
yu=puhuT
wuxu+i=1,i=u∑UtpihuT
wixi+nu
其中,
hu∈CMN×1表示基站中的信道向量,
wi∈CMN×1表示用户i的标准波束形成矢量,
xi表示用户i满足
E{∣xi∣2}=1的数据符号,
nu∼CN(0,σu2)是复高斯白噪声,
pi是在总功率限制
∑i=1Utpi≤Pt下为用户i传输功率.
本文中研究相对一般的信道模型,即相关衰落信道模型。基站中用户间的信道矢量
hu可表示为
hu=Ku+1Ku
hu+Ku+11
h~u其中
hu∈CMN×1表示视距分量,
h~u∈CMN×1表示瑞利分布的非视距分量,
Ku表示LOS和非LOS信道功率的比率。在给定的UPA中,确定部分
hu可表示为:
hu=aH,u(θu,φu)⊗aV,u(θu)
with
aH,u(θu,φu)aV,u(θu)=[1,e−jπϕu,⋯,e−jπ(N−1)ϕu]T=[1,e−jπsinθu,⋯,e−jπ(M−1)sinθu]T
其中
ϕu=cosθusinφu,θu 和
φu 分别是用户
u 在竖直以及水平方向的倾斜角 (AoD)。通过引用资料可得,非LOS分量可表示为:
h~u=(RH,u1/2⊗RV,u1/2)hw,u
其中
hw,u∈CMN×1的项是独立同分布的具有零均值和单位方差的复高斯随机变量(RVs),
RH,u∈CN×N和
RV,u∈CM×M分别是水平和竖直信道的相关矩阵。此外,我们假设每个单用户都拥有各自的有效CSI,而基站有所有用户的统计CSI,即
Ku,σu2,hu,RH,u,RV,u,这些都可以通过基站对FDD系统的长期反馈来获得。
下行波束形成传输
在我们所研究的下行传输系统中,遍历和率可表示为:
Rsum=u=1∑UtRu
Ru是用户u的遍历和率,可表示为:
Ru=E{log2(1+σu2+UtPt∑i=1,i=uUt∣huTwi∣2UtPt∣∣huTwu∣∣2)}但是公式中的元素在相关衰落信道下很难获取。
受深度学习技术在无线通信中的新兴应用启发,我们计划通过深度神经网络来解决波束形成问题。当天线和用户数量增加时,传统的数据驱动DL方法会导致神经网络变得非常庞大和复杂,这需要大量的训练时间和庞大的训练数据集。为了减少网络的复杂性和训练数据的获取,以及大量的训练数据,我们分离计算并推导出结构每个用户的波束成形向量通过最优度量,即最大化信漏噪比(SLNR)。在此基础上,提出了基于模型驱动的深度学习波束形成算法和解析波束形成算法。
A. 波束成形架构
用户u 的SLNR可表示为:
SLNRu=σu2+UtPt∑i=1,i=uUt∣∣hiTwu∣∣2UtPt∣∣huTwu∣∣2最后可推导为
SLNRuL=σu2+UtPt∑i=1,i=uUtwuHΔiwuUtPtwuHΔuwu
其中
Δi=AH,i=Ki+11RH,iT⊗RV,iT+Ki+1KiAH,i⊗AV,ii=1,⋯,UtaH,i∗(θi,φi)aH,iT(θi,φi)
并且
AV,i=aV,i∗(θi)aV,iT(θi)
定义
ΛH,u=FNHRH,uTFNΛV,u=FMHRV,uTFMAH,u=FNHAH,uFN
且
AV,u=FMHAV,uFM
其中
FN∈CN×N和
FM∈CM×M都是统一DFT矩阵.对于大型均匀直线天线阵,其相关矩阵的特征向量可以用DFT矩阵近似,只有少数相邻的特征值非零。最后我们可以得到SLNR下界的表达式为
SLNRuL≤Utρu(Ku+1λH,u(nˉu)λV,u(mˉu)+Ku+1KuaH,u(mˉu)aV,u(mˉu))
其中
ρu=Pt/σu2,λH,u(i) 和
λV,u(i) 是
ΛH,u and
ΛV,u第i
个对角元素,aH,u(i)和
aV,u(i) 是
AH,u and
AV,u第i
个对角元素,
mˉu和
nˉu是矩阵
Ωu最大元素的索引值
(i,j) -
ωu(i,j) :
ωu(i,j)=Ku+11λV,u(i)λH,u(j)+Ku+1KuaV,u(i)aH,u(j)
ωu(mˉu,nˉu)=1≤i≤M,1≤j≤Nmaxωu(i,j)
SLNR表达式只在且仅当基站用波束形成向量传输给用户u时实现
wu=(FN)nˉu⊗(FM)mˉu
用户i(i≠u)应该满足
ωi(mu,nu)=1≤m≤M,1≤n≤Nminωi(m,n)=0.的条件.
基于以上分析后,将
wu作为我们想要得到的波束赋形向量.
B. 基于深度学习的波束成形算法
由此我们可以得出求波束赋形向量
wu的关键是求出
mu和
nu.为了降低计算复杂度和时间,我们采用深度学习算法.
- 深度学习神经网络架构
wu可分为竖直和水平两个方向分别进行计算,由之前推导可知,
nu和
mu只有关于
λH,u(i),aH,u(i),i=1. . . , N,
N,λV,u(j),aV,u(j),j=1,⋯ ,
M 和
Ku.
我们构建前向传播深度神经网络(BFDNN)来对这两个未知量进行计算.
输入值为
xu={Ku, λH,u(i), aH,u(i), λV,u(j), aV,u(j)∣i=1, ⋯, N,j=1, ⋯, M},这些都可以在基站中获取到.
网络输出值为
pu∈R(N+M)×1,取值为0或1
直接上图:
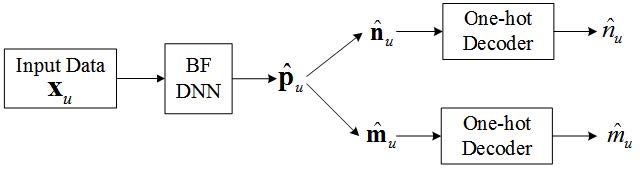

最后的输出值可表示为
Pu=f(xu, θ)=f(3)(f(2)(f(1)(xu)))
网络一共分为四层,即输入层,隐含层,dropout层和输出层.
- 输入层: 即输入之前在基站中获取的必要数据集;
- 隐含层: 使用Relu非线性激活函数,
fR(x)=max(0, x). 第i个神经元输出为
zi(1)=fR(j∑wi,j(1)xuι(j)+bi(1)),i=1,⋯,N1
- dropout层: 防止在训练过程中数据过拟合.依旧使用Relu非线性激活函数. 第i个神经元输出为
zi(2)=fR[ri(j∑wi,j(2)zj(1)+bi(2))],i=1,⋯,N2
ri∼Bernoulli(P)是指
ri有P的概率为0.
- 输出层: 分别包含水平概率向量所有可能的水平索引值和垂直概率向量所有可能的垂直索引值. 激活函数是S型函数,即
fS(x)i=1/(1+e−xi),
x=[x, x, ⋯ , xN+M]T.第i个输出可表示为
pu,i=fS(g)i, i=1, ⋯ , N+M
gi=j∑wi,j(3)zj(2)+bi(3),wi,j(3)是连接前层第i个神经元的第j个输出的权重.
2. 训练过程
BFDNN(波束赋形深度神经网络)是监督学习使用前向传播算法去寻找适当的参数集的神经网络.
从DNN按不同层的位置划分,DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。
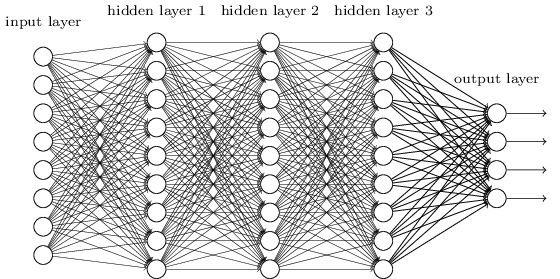
层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i+1层的任意一个神经元相连。
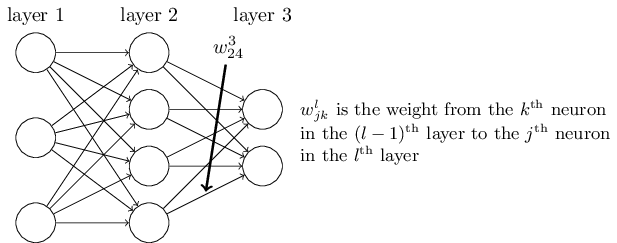
我们可以利用上一层的输出计算下一层的输出,也就是所谓的DNN前向传播算法.DNN的前向传播算法也就是利用我们的若干个权重系数矩阵WW和偏倚向量bb来和输入值向量xx进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直到运算到输出层,得到输出结果为止 。
- 首先我们随机生成一组输输入参数集
xu={Ku, λH,u(i), aH,u(i), λV,u(j), aV,u(j)∣i=1, ⋯, N,j=1, ⋯, M}
- 接下来我们得到了对应的水平索引和数值索引
- 最后我们通过one-hot编码法对
nu和
mu进行编码得到训练标签
pu
通过采用监督学习的方法,该网络经过训练,使分类交叉熵(CE)损失函数最小化。分类交叉熵一般使用损失函数去测量目标和输出预测值的差距,被定义为:
L(θ)=U−1i=1∑Uk=1∑N+M[pi,kln(pi,k^)+(1−pi,k)ln(1−p^i,k)]
U是训练样本数,
pi,k是
pi的第k个元素.
BFDNN由于不同用户的波束形成向量是解耦的,与调度结果无关,所以对所有用户可以通过单个线下训练实现.计算由线上转为了线下,所以大大减小了计算复杂度.它还可以在不需要重复训练的情况下处理各种各样的环境,因为它同时考虑了LOS和相关性的影响。
以上内容为论文中关于数据驱动算法求解波束成形问题的讲解,下面的内容是关于模型驱动求解以及解决用户调度的问题,我会在接下来的文章中继续进行分析.
接下来我来对以上的内容进行一些补充.
对于本文的数据驱动算法求解波束赋形向量中,使用BFDNN对非线性模型进行预测,运用了DNN前向传播算法.
所谓的DNN前向传播算法就是利用若干个权重系数矩阵W,偏倚向量b来和输入值向量x进行一系列线性运算和激活运算,从输入层开始,一层层的向后计算,一直到运算到输出层,得到输出结果为值。
输入: 总层数L,所有隐藏层和输出层对应的矩阵W,偏倚向量b,输入值向量x
输出:输出层的输出。
因为本论文中研究的模型较为简单,数据集较易获取,输出值只为0或1,所以就直接采用较为简单的前向传播算法进行训练.
同时我们要注意几个非线性回归的基本要素:
- 模型: 这里我们使用的BFDNN模型
- 数据集: 这里我们的输入数据集就是我们在基站中所采取的需要的数据,直接代入到网络中即可求解
- 损失函数和激活函数: 我们BFDNN模型中选用的损失函数是交叉熵损失函数以及Relu和Sigmoid两个非线性激活函数改进DNN算法收敛速度,之所以这样搭配是因为在用Sigmoid函数作为激活函数的时候,交叉熵损失函数比平方差损失函数的效果更加出色.
- 优化函数 - 使用Dropout层,这里我们使用dropout很好地防止了在训练过程中的过拟合现象.
以上暂时为本人对该论文的一些浅薄的认识,会有继续的更新.
